Introdução: Os dados não mentem, mas os gráficos podem
Você está em uma reunião. Um colega apresenta um gráfico mostrando que a eficácia de um novo medicamento é muito superior à do antigo. Você vê claramente a diferença no visual. Depois, outro colega apresenta o mesmo dado e conclui que não há diferença significativa. Como é possível?
A resposta é simples: as escolhas visuais são escolhas editoriais. Cada decisão — onde começar o eixo Y, que escala usar, que cores escolher, qual período mostrar — é uma decisão sobre a narrativa que você quer contar. E o mesmo dataset pode contar histórias completamente diferentes, até opostas.
Este capítulo é sobre responsabilidade. Não se trata de “como trapacear com gráficos”. Trata-se de entender que cada gráfico que você cria conta uma história, e você é responsável por essa história. Na medicina, essa responsabilidade tem peso de ouro — literal. Decisões baseadas em má visualização custam vidas.
1. Manipulação do Eixo Y: A Diferença Que Parece Enorme
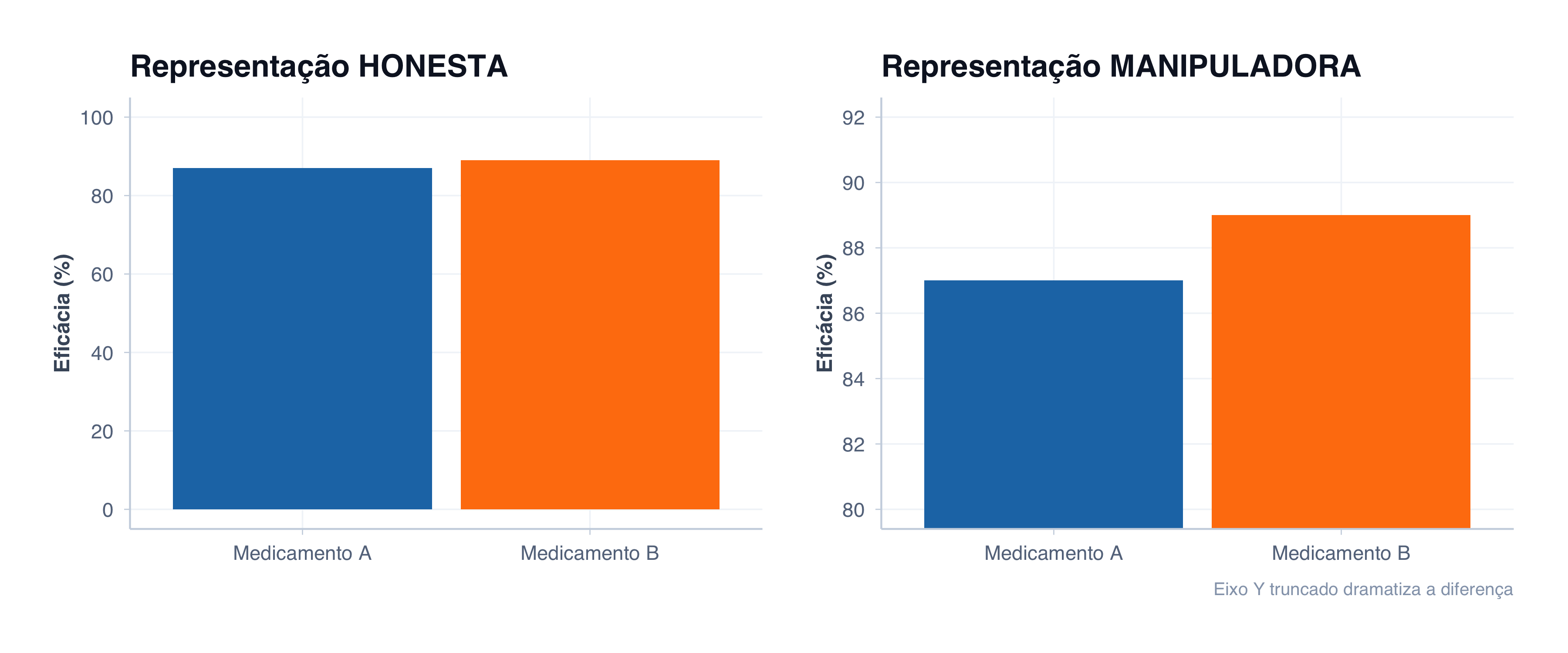
Imagine um estudo comparando dois medicamentos para controle de glicemia:
Medicamento A: eficácia de 87%
Medicamento B: eficácia de 89%
Diferença real: 2 pontos percentuais. Diferença visual? Depende do seu gráfico.
Ver código R
# Dados dos medicamentosmed_comparacao <-tibble(medicamento =c("Medicamento A", "Medicamento B"),eficacia =c(87, 89))# Gráfico 1: Eixo Y CORRETO (começa em 0)p1 <- med_comparacao %>%ggplot(aes(x = medicamento, y = eficacia, fill = medicamento)) +geom_col(show.legend =FALSE) +scale_fill_manual(values =c("#1f77b4", "#ff7f0e")) +scale_y_continuous(limits =c(0, 100), breaks =seq(0, 100, 20)) +labs(title ="Representação HONESTA",x =NULL,y ="Eficácia (%)" ) +tema_graficos() +theme(axis.text.x =element_text(size =11))# Gráfico 2: Eixo Y TRUNCADO (começa em 80)p2 <- med_comparacao %>%ggplot(aes(x = medicamento, y = eficacia, fill = medicamento)) +geom_col(show.legend =FALSE) +scale_fill_manual(values =c("#1f77b4", "#ff7f0e")) +scale_y_continuous(breaks =seq(80, 92, 2)) +coord_cartesian(ylim =c(80, 92)) +labs(title ="Representação MANIPULADORA",x =NULL,y ="Eficácia (%)",caption ="Eixo Y truncado dramatiza a diferença" ) +tema_graficos() +theme(axis.text.x =element_text(size =11))p1 | p2
O mesmo dado contado de duas formas: o gráfico à direita manipula o eixo Y para dramatizar a diferença
Observe a diferença:
No gráfico honesto, as colunas são praticamente iguais. A diferença é real, mas pequena.
No gráfico manipulador, parece que o Medicamento B é duas vezes melhor!
Esse é um truque clássico em publicidade de fármacos, relatórios corporativos e até em jornalismo sensacionalista.
Quando começar o eixo em zero?
Tipo de Gráfico
Começa em Zero?
Por quê?
Gráficos de Barras
SIM, sempre
Barras representam volumes/quantidades. Começar em zero é o único jeito honesto de comparar tamanhos
Gráficos de Linhas
Depende
Se mostra uma série temporal de quantidade, comece em zero. Se quer ver variação/tendência, pode truncar
Scatter Plot
Não necessariamente
O interesse é a relação entre variáveis, não a escala absoluta
Heatmap
Não
Representa densidade/intensidade, não quantidade
AvisoRegra de Ouro para Gráficos de Barras
Sempre comece em zero. Ponto.
Se você está comparando quantidades visualmente (o tamanho das barras), o único jeito de fazer isso honestamente é começar em zero. Caso contrário, está contando uma mentira visual.
2. Manipulação de Escala: Linear vs. Logarítmica
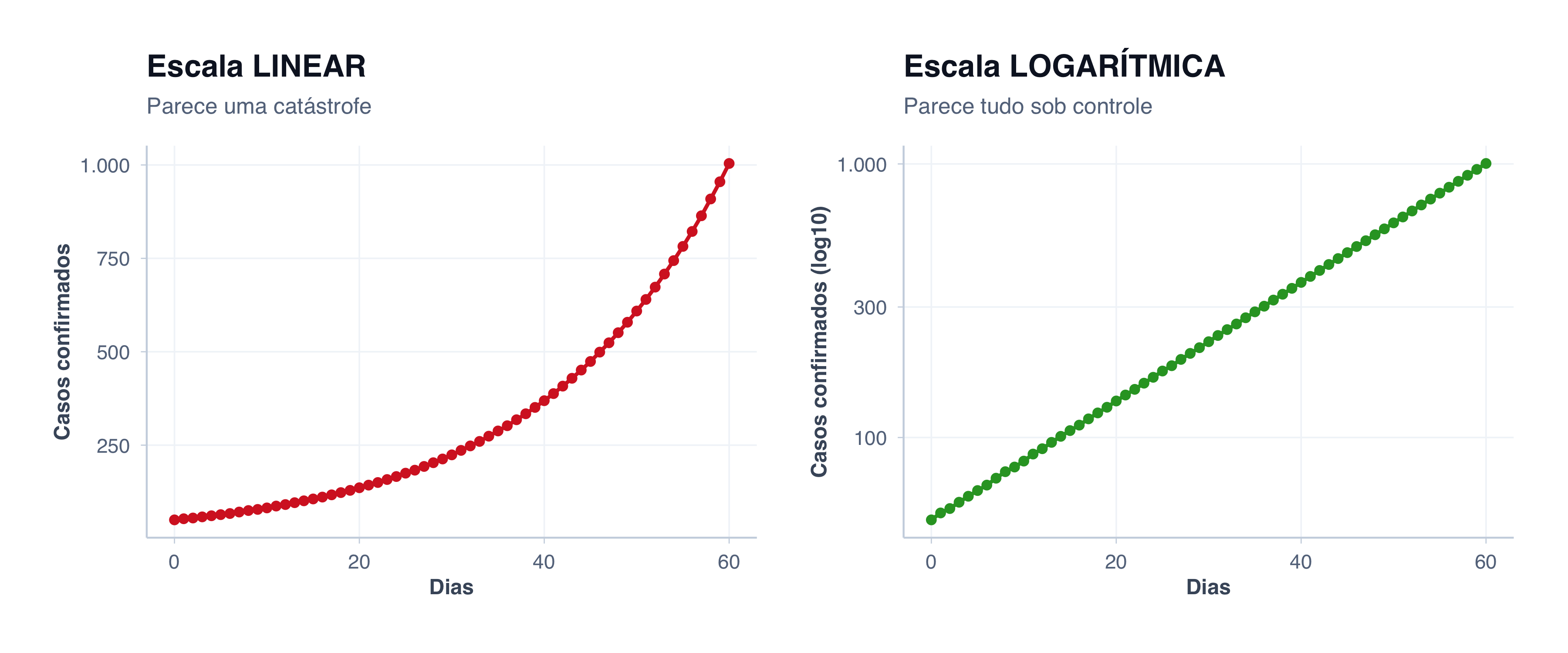
Escala linear: 1, 2, 3, 4, 5… o espaçamento é constante.
Escala logarítmica: 1, 10, 100, 1000… cada incremento é 10 vezes maior.
Quando você tem dados que crescem exponencialmente (como uma epidemia ou crescimento viral), a escala logarítmica é honesta. Mas parece que minimiza o problema.
Vamos simular uma epidemia de COVID-19 em um município:
A mesma epidemia contada de duas formas: linear parece catastrófica, logarítmica parece controlada
Qual está certa?Ambas. Mas contam histórias diferentes:
Escala linear: “Vemos o crescimento explosivo. É uma catástrofe. Precisamos agir AGORA.”
Escala logarítmica: “O crescimento parece uma linha reta — calmo, previsível, sob controle.” (Na verdade, uma reta na escala log é crescimento exponencial — mas visualmente não parece alarmante.)
Na pandemia real, a mídia mostrava gráficos lineares (porque era alarmante), enquanto epidemiologistas usavam logarítmicos (porque era preciso).
Dica
Quando usar escala logarítmica:
Dados que cobrem várias ordens de magnitude (1 a 1.000.000)
Crescimento/decaimento exponencial
Quando você quer ver taxa de mudança, não valor absoluto
Quando usar escala linear:
Dados que representam quantidades comparáveis
Quando o valor absoluto importa
Sempre indique qual escala está usando no eixo Y.
3. Escolha da Geometria: Barras vs. Linhas vs. Pontos
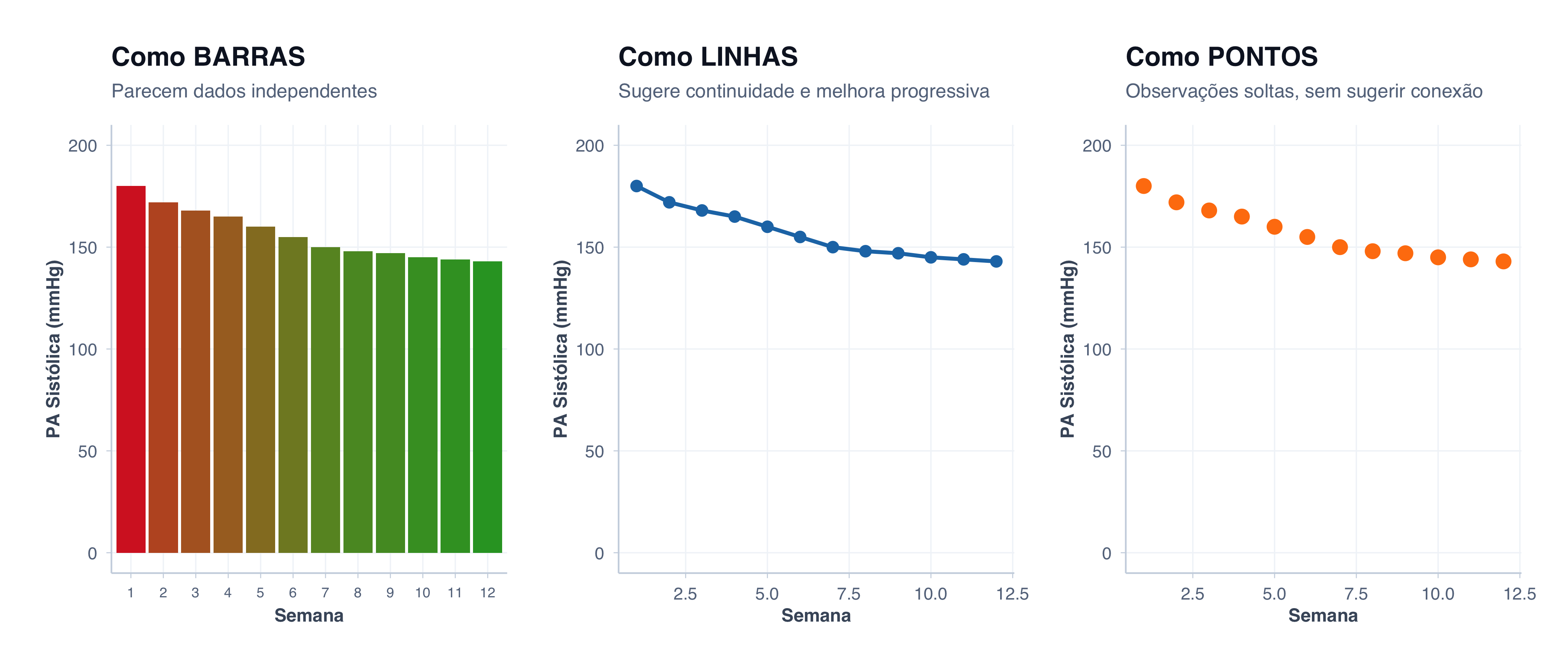
A geometria diz uma história implícita sobre seus dados.
Barras dizem: “Estes são valores discretos e independentes. Compare os tamanhos.”
Linhas dizem: “Existe continuidade. Observe a tendência e a progressão.”
Pontos dizem: “Observe a relação entre variáveis.”
Vamos pegar dados de pressão arterial ao longo de um tratamento:
Ver código R
# Dados de PA em paciente durante tratamentopa_dados <-tibble(semana =1:12,sistolica =c(180, 172, 168, 165, 160, 155, 150, 148, 147, 145, 144, 143))# Gráfico 1: Barras (parece dados independentes)p1_pa <- pa_dados %>%ggplot(aes(x =factor(semana), y = sistolica, fill = sistolica)) +geom_col(show.legend =FALSE) +scale_fill_gradient(low ="#2ca02c", high ="#d62728") +scale_y_continuous(limits =c(0, 200)) +labs(title ="Como BARRAS",subtitle ="Parecem dados independentes",x ="Semana",y ="PA Sistólica (mmHg)" ) +tema_graficos() +theme(axis.text.x =element_text(size =9))# Gráfico 2: Linhas (mostra continuidade e tendência)p2_pa <- pa_dados %>%ggplot(aes(x = semana, y = sistolica)) +geom_line(color ="#1f77b4", linewidth =1.2) +geom_point(color ="#1f77b4", size =3) +scale_y_continuous(limits =c(0, 200)) +labs(title ="Como LINHAS",subtitle ="Sugere continuidade e melhora progressiva",x ="Semana",y ="PA Sistólica (mmHg)" ) +tema_graficos()# Gráfico 3: Pontos (mostra observações individuais, sem conexão)p3_pa <- pa_dados %>%ggplot(aes(x = semana, y = sistolica)) +geom_point(color ="#ff7f0e", size =4) +scale_y_continuous(limits =c(0, 200)) +labs(title ="Como PONTOS",subtitle ="Observações soltas, sem sugerir conexão",x ="Semana",y ="PA Sistólica (mmHg)" ) +tema_graficos()p1_pa | p2_pa | p3_pa
Mesmos dados, três histórias diferentes
As histórias implícitas:
Barras: “Cada semana é uma medição independente. Compare os tamanhos.”
Linhas: “Veja como a PA cai consistentemente. O tratamento está funcionando.”
Pontos: “Aqui estão as observações. Tire suas próprias conclusões sobre a relação.”
Todas as três são graficamente corretas, mas cada uma enfatiza aspectos diferentes.
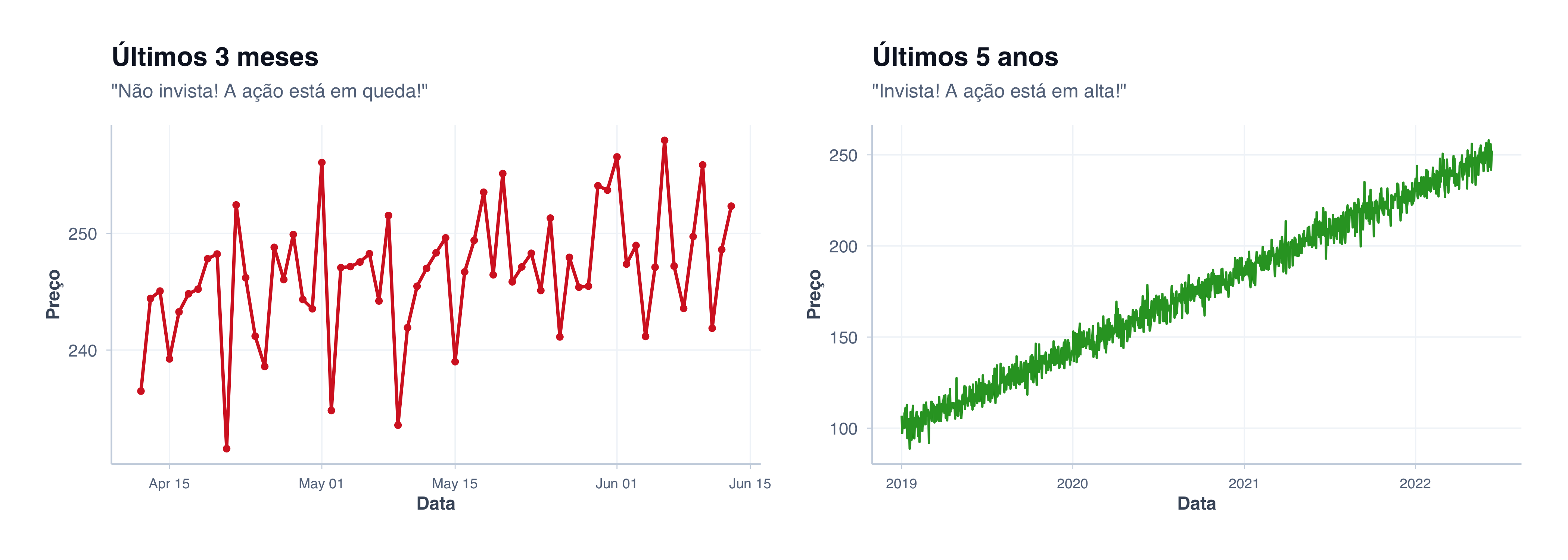
4. Seleção do Período: O mesmo ativo, duas histórias
Você está considerando investir em ações de uma empresa. Um analista otimista mostra o gráfico dos últimos 3 meses. Um analista pessimista mostra os últimos 5 anos. Mesma ação, completamente diferentes conclusões.
Vamos simular o preço de uma ação:
Ver código R
# Simular preço com tendência de longo prazo e queda recenteset.seed(42)dias_totais <-5*252# 5 anos de pregãotendencia <-seq(100, 250, length.out = dias_totais)ruido <-rnorm(dias_totais, sd =5)preco <- tendencia + ruidopreco_dados <-tibble(dia =1:dias_totais,data =seq(as.Date("2019-01-01"), by ="day", length.out = dias_totais),preco =pmax(preco, 50) # evitar valores negativos)# Últimos 3 mesespreco_3m <- preco_dados %>%filter(dia > (dias_totais -63)) # aprox 3 meses# Últimos 5 anospreco_5a <- preco_dados# Gráfico 1: Últimos 3 meses (parece estar em queda)p1_preco <- preco_3m %>%ggplot(aes(x = data, y = preco)) +geom_line(color ="#d62728", linewidth =1) +geom_point(color ="#d62728", size =1.5) +labs(title ="Últimos 3 meses",subtitle ="\"Não invista! A ação está em queda!\"",x ="Data",y ="Preço" ) +tema_graficos() +theme(axis.text.x =element_text(size =9))# Gráfico 2: Últimos 5 anos (parece estar em alta)p2_preco <- preco_5a %>%ggplot(aes(x = data, y = preco)) +geom_line(color ="#2ca02c", linewidth =0.7) +labs(title ="Últimos 5 anos",subtitle ="\"Invista! A ação está em alta!\"",x ="Data",y ="Preço" ) +tema_graficos() +theme(axis.text.x =element_text(size =9))p1_preco | p2_preco
Escolher o período é escolher a narrativa
Responsabilidade médica: Em pesquisa clínica, há regulações sobre qual período você deve mostrar. Se um medicamento teve bons resultados nos 6 primeiros meses, mas os efeitos colaterais apareceram no ano 2, você precisa mostrar os 2 anos. Escolher apenas os 6 primeiros meses é fraude.
5. Cores e Proporções: Emoções Visuais
Vermelho alerta. Verde acalma. Preto intimida. Amarelo avisa.
Essas reações são quase universais e profundamente emocionais. Quando você muda a cor, muda a emoção da informação, não a informação em si.
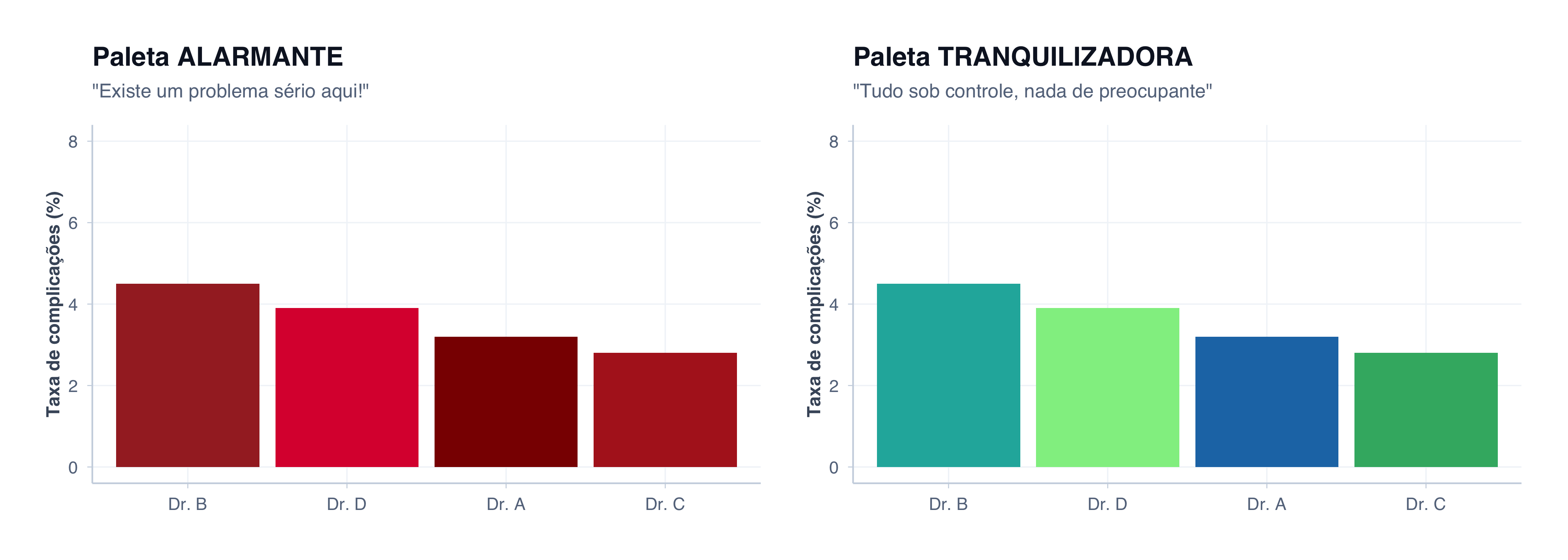
Vamos simular dados de taxa de complicação pós-cirúrgica:
Ver código R
# Dados de complicações por cirurgiãocirurgioes_dados <-tibble(cirurgiao =c("Dr. A", "Dr. B", "Dr. C", "Dr. D"),complicacoes_pct =c(3.2, 4.5, 2.8, 3.9))# Gráfico 1: Paleta ALARMANTE (vermelho escuro)p1_cores <- cirurgioes_dados %>%ggplot(aes(x =reorder(cirurgiao, -complicacoes_pct), y = complicacoes_pct, fill = cirurgiao)) +geom_col(show.legend =FALSE) +scale_fill_manual(values =c("#8b0000", "#a52a2a", "#b22222", "#dc143c")) +scale_y_continuous(limits =c(0, 8)) +labs(title ="Paleta ALARMANTE",subtitle ="\"Existe um problema sério aqui!\"",x =NULL,y ="Taxa de complicações (%)" ) +tema_graficos()# Gráfico 2: Paleta TRANQUILIZADORA (verde/azul)p2_cores <- cirurgioes_dados %>%ggplot(aes(x =reorder(cirurgiao, -complicacoes_pct), y = complicacoes_pct, fill = cirurgiao)) +geom_col(show.legend =FALSE) +scale_fill_manual(values =c("#1f77b4", "#20b2aa", "#3cb371", "#90ee90")) +scale_y_continuous(limits =c(0, 8)) +labs(title ="Paleta TRANQUILIZADORA",subtitle ="\"Tudo sob controle, nada de preocupante\"",x =NULL,y ="Taxa de complicações (%)" ) +tema_graficos()p1_cores | p2_cores
Mesmos dados, reações emocionais opostas
Observe: os dados são idênticos. Apenas as cores mudaram. Mas a reação emocional é completamente diferente.
Essa tática é usada frequentemente em relatórios corporativos: dados ruins em gráficos vermelhos aparecem em slides de “problemas”, enquanto dados igualmente ruins em gráficos azuis passam despercebidos.
6. Risco Relativo vs. Risco Absoluto: O Exemplo Farmacêutico
Este é o exemplo mais importante para médicos. A indústria farmacêutica o adora.
Cenário: Um novo medicamento reduz o risco de infarto em 50%.
Parece incrível, não é? 50%!
Agora vamos ver o risco absoluto:
Sem medicamento: 2 em 100 pessoas sofrem infarto (2%)
Com medicamento: 1 em 100 pessoas sofrem infarto (1%)
Redução de 2% para 1% é tecnicamente uma redução de 50% (relativa). Mas o benefício absoluto é apenas 1%.
Vamos visualizar:
Ver código R
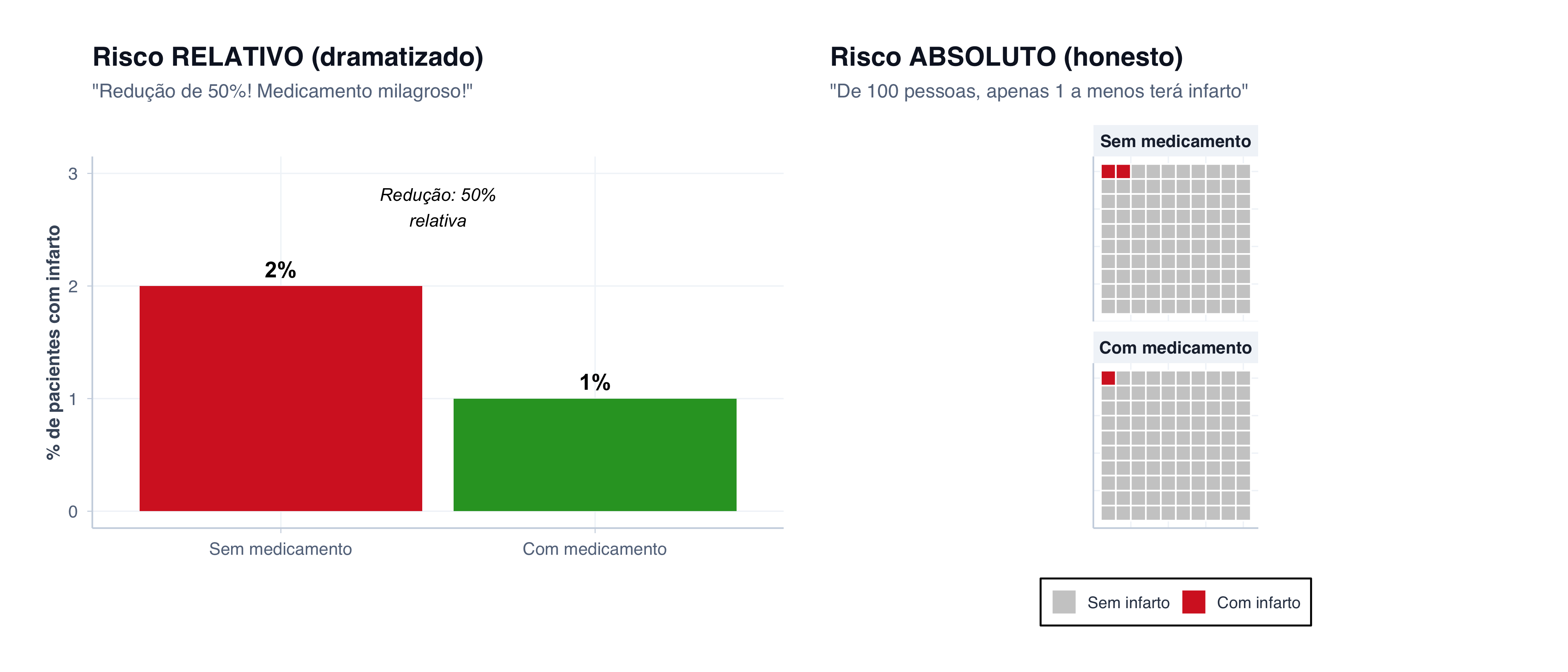
# Dados de eficácia do medicamento hipotéticorisco_dados <-tibble(grupo =c("Sem medicamento", "Com medicamento"),risco =c(2, 1),nao_risco =c(98, 99),total =c(100, 100))# Gráfico 1: Mostra APENAS os infartos (risco relativo dramatizado)risco_dados <- risco_dados %>%mutate(grupo =factor(grupo, levels =c("Sem medicamento", "Com medicamento")))p1_risco <- risco_dados %>%ggplot(aes(x = grupo, y = risco, fill = grupo)) +geom_col(show.legend =FALSE) +scale_fill_manual(values =c("Sem medicamento"="#d62728","Com medicamento"="#2ca02c" )) +scale_y_continuous(limits =c(0, 3)) +geom_text(aes(y = risco +0.15, label =paste0(risco, "%")),size =5, fontface ="bold") +annotate("text", x =1.5, y =2.7, label ="Redução: 50%\nrelativa",size =4, hjust =0.5, fontface ="italic") +labs(title ="Risco RELATIVO (dramatizado)",subtitle ="\"Redução de 50%! Medicamento milagroso!\"",x =NULL,y ="% de pacientes com infarto" ) +tema_graficos()# Gráfico 2: Grade 10x10 (waffle) mostrando 100 pacientes# Cada quadrado = 1 pessoa. Vermelhos = infarto.fazer_waffle <-function(n_infarto, label_grupo) {tibble(x =rep(1:10, 10),y =rep(10:1, each =10),pessoa =1:100,infarto =c(rep("Com infarto", n_infarto), rep("Sem infarto", 100- n_infarto)) ) %>%mutate(grupo = label_grupo)}waffle_dados <-bind_rows(fazer_waffle(2, "Sem medicamento"),fazer_waffle(1, "Com medicamento")) %>%mutate(grupo =factor(grupo, levels =c("Sem medicamento", "Com medicamento")),infarto =factor(infarto, levels =c("Sem infarto", "Com infarto")) )p2_risco <- waffle_dados %>%ggplot(aes(x = x, y = y, fill = infarto)) +geom_tile(color ="white", linewidth =0.5) +facet_wrap(~ grupo, ncol =1) +scale_fill_manual(values =c("Sem infarto"="#cccccc", "Com infarto"="#d62728"), name =NULL) +labs(title ="Risco ABSOLUTO (honesto)",subtitle ="\"De 100 pessoas, apenas 1 a menos terá infarto\"",x =NULL, y =NULL ) +tema_graficos() +theme(axis.text =element_blank(),axis.ticks =element_blank(),legend.position ="bottom",strip.text =element_text(size =11, face ="bold") ) +coord_equal()p1_risco | p2_risco
Risco Relativo (dramatizado) vs. Risco Absoluto (honesto)
A narrativa de marketing: “Reduz risco de infarto em 50%”
A verdade: “De 100 pessoas tratadas, 1 a menos terá infarto. Os outros 99 não ganham nada.”
ImportantePara Médicos: Sempre Calcule o NNT
NNT = Number Needed to Treat = quantas pessoas você precisa tratar para evitar 1 evento adverso.
No exemplo acima: - Risco absoluto sem medicamento: 2% - Risco absoluto com medicamento: 1% - NNT = 100 (você precisa tratar 100 pessoas para evitar 1 infarto)
Agora pergunte: qual é o custo do medicamento? Quais são os efeitos colaterais? Vale a pena tratar 100 pessoas para ajudar 1?
Essa é uma decisão clínica responsável. Simplesmente ouvir “reduz risco em 50%” é ser manipulado.
7. Aplicação Real: Publicidade Farmacêutica
Vamos construir um exemplo realista que você provavelmente viu em anúncios de TV:
Ver código R
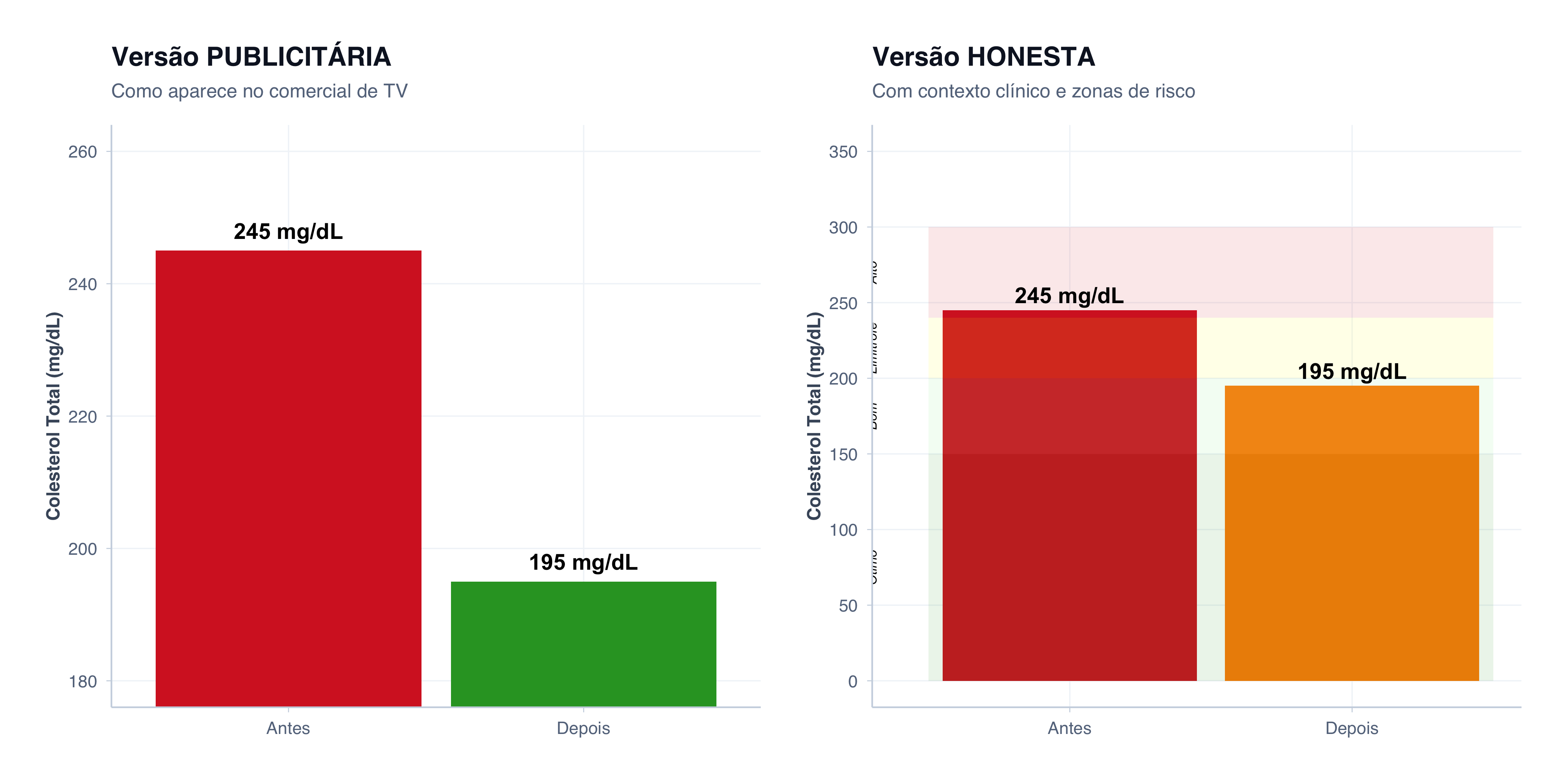
# Medicamento fictício para colesterolcolesterol_dados <-tibble(tempo =factor(c("Antes", "Depois"), levels =c("Antes", "Depois")),media_colesterol =c(245, 195),n_pacientes =c(250, 250))# Gráfico 1: VERSÃO PUBLICITÁRIA (dramatizada)p1_pub <- colesterol_dados %>%ggplot(aes(x = tempo, y = media_colesterol, fill = tempo)) +geom_col(show.legend =FALSE) +scale_fill_manual(values =c("Antes"="#d62728", "Depois"="#2ca02c")) +geom_text(aes(y = media_colesterol +3, label =paste0(media_colesterol, " mg/dL")),fontface ="bold", size =5) +coord_cartesian(ylim =c(180, 260)) +labs(title ="Versão PUBLICITÁRIA",subtitle ="Como aparece no comercial de TV",x =NULL,y ="Colesterol Total (mg/dL)" ) +tema_graficos()# Gráfico 2: VERSÃO HONESTA (com contexto clínico)contexto_colesterol <-tibble(categoria =c("Ótimo", "Bom", "Limítrofe", "Alto", "Muito Alto"),minimo =c(0, 150, 200, 240, 300),maximo =c(150, 199, 239, 299, 400))p2_pub <- colesterol_dados %>%ggplot(aes(x = tempo, y = media_colesterol, fill = tempo)) +geom_col(show.legend =FALSE) +scale_fill_manual(values =c("Antes"="#d62728", "Depois"="#ff8c00")) +scale_y_continuous(limits =c(0, 350), breaks =seq(0, 350, 50)) +# Zonas de riscoannotate("rect", xmin =0.5, xmax =2.5, ymin =0, ymax =150,fill ="#2ca02c", alpha =0.1) +annotate("rect", xmin =0.5, xmax =2.5, ymin =150, ymax =200,fill ="#90ee90", alpha =0.1) +annotate("rect", xmin =0.5, xmax =2.5, ymin =200, ymax =240,fill ="#ffff00", alpha =0.1) +annotate("rect", xmin =0.5, xmax =2.5, ymin =240, ymax =300,fill ="#d62728", alpha =0.1) +annotate("text", x =0.3, y =75, label ="Ótimo", angle =90, size =3, fontface ="italic") +annotate("text", x =0.3, y =175, label ="Bom", angle =90, size =3, fontface ="italic") +annotate("text", x =0.3, y =220, label ="Limítrofe", angle =90, size =3, fontface ="italic") +annotate("text", x =0.3, y =270, label ="Alto", angle =90, size =3, fontface ="italic") +geom_text(aes(y = media_colesterol +10, label =paste0(media_colesterol, " mg/dL")),fontface ="bold", size =5) +labs(title ="Versão HONESTA",subtitle ="Com contexto clínico e zonas de risco",x =NULL,y ="Colesterol Total (mg/dL)" ) +tema_graficos()p1_pub | p2_pub
Como a indústria farmacêutica apresenta dados (e como deveriam ser apresentados)
NotaAnálise Crítica
Gráfico 1 (Publicitário): eixo Y truncado (180 a 260), nenhum contexto clínico, cores que dramatizam a mudança. Impressão: transformação milagrosa.
Gráfico 2 (Honesto): eixo Y começa em 0, mostra zonas de risco clínico. O colesterol passou de “Alto” (245) para “Limítrofe” (195). Impressão: melhora significativa, mas não milagrosa.
Ambos os gráficos mostram uma melhora real. Mas a magnitude visual da melhora é completamente diferente.
8. Dados Multidimensionais: Quando Esconder é Honesto
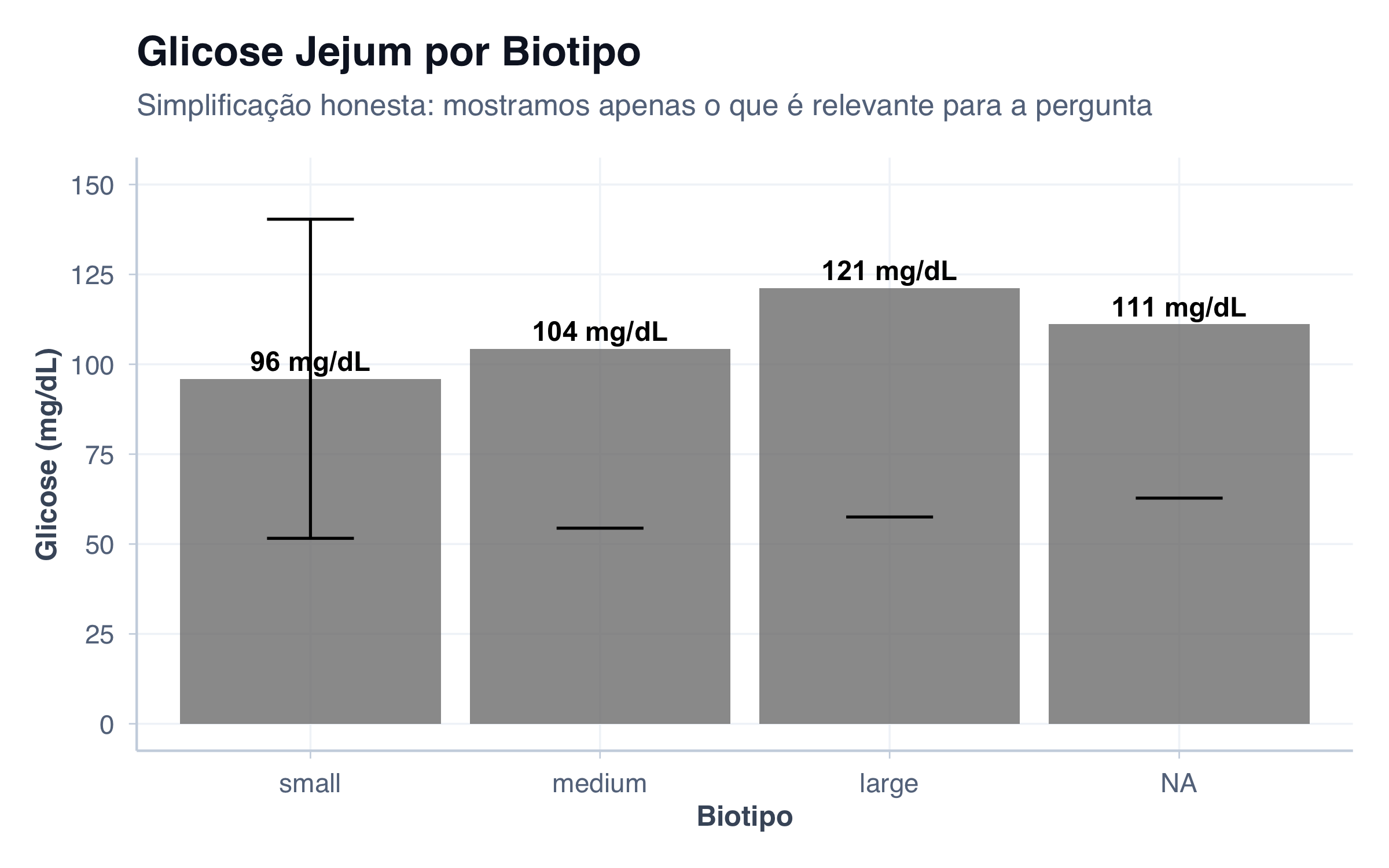
Às vezes, simplificar é o jeito certo de visualizar dados. Não estou falando de esconder informação — estou falando de reconhecer que nem todos os aspectos de um dataset são relevantes para a pergunta que você está respondendo.
Exemplo: você quer comparar glicose jejum por biotipo. Você poderia mostrar tudo (idade, sexo, peso, altura, etc.), mas isso seria desonesto porque obscureceria a mensagem principal.
Ver código R
# Comparação simples: glicose por biotipoglicose_biotipo <- pacientes %>%group_by(biotipo) %>%summarise(media =mean(glicose, na.rm =TRUE),dp =sd(glicose, na.rm =TRUE),n =n(),.groups ="drop" ) %>%arrange(media)glicose_biotipo %>%ggplot(aes(x =reorder(biotipo, media), y = media, fill = biotipo)) +geom_col(show.legend =FALSE, alpha =0.8) +geom_errorbar(aes(ymin = media - dp, ymax = media + dp), width =0.3) +scale_y_continuous(limits =c(0, 150), breaks =seq(0, 150, 25)) +scale_fill_manual(values = cores) +geom_text(aes(y = media +5, label =paste0(round(media, 0), " mg/dL")),fontface ="bold", size =4) +labs(title ="Glicose Jejum por Biotipo",subtitle ="Simplificação honesta: mostramos apenas o que é relevante para a pergunta",x ="Biotipo",y ="Glicose (mg/dL)" ) +tema_graficos()
9. Resumo: Checklist de Responsabilidade
Toda vez que você criar um gráfico, faça-se essas perguntas:
NotaPerguntas para Verificação Ética
Se respondeu “sim” a qualquer uma dessas, repense seu gráfico.
Quiz
Questão 1: Um medicamento reduz o tempo de internação de 10 dias para 8 dias (em média). Em qual situação seria APROPRIADO truncar o eixo Y do gráfico?
Sempre. Queremos mostrar a melhora.
Quando usamos gráficos de linhas ou scatter plots com dados contínuos, é aceitável.
Quando queremos apenas mostrar a tendência, não a magnitude absoluta.
Nunca. Sempre começar em zero.
NotaResposta
Resposta correta: b) Quando usamos gráficos de linhas ou scatter plots com dados contínuos, é aceitável.
Gráficos de linhas ou scatter plots com dados contínuos podem ter eixo Y truncado se o interesse é na tendência, não na magnitude. Mas se está comparando com um gráfico de barras, comece em zero — barras representam volumes, e truncar o eixo distorce a percepção visual.
Questão 2: Você precisa escolher entre mostrar 5 anos de dados (com recuperação recente) ou 1 ano (com declínio). Qual é a escolha ética?
Mostrar os 5 anos, pois é mais favorável.
Mostrar o 1 ano, pois é mais recente.
Mostrar ambos ou explicar por que escolheu um período.
Escolher o que você acredita ser mais representativo.
NotaResposta
Resposta correta: c) Mostrar ambos ou explicar por que escolheu um período.
Escolher o período que favorece sua narrativa é manipulação, mesmo que os dados sejam reais. A ética exige transparência sobre a escolha do período. Quando possível, mostre ambos; quando não for possível, justifique a escolha.
Questão 3: Qual das seguintes NÃO é uma manipulação visual desonesta?
Usar escala logarítmica para dados de crescimento exponencial, desde que indicado.
Começar eixo Y em 50 em um gráfico de barras mostrando diferenças pequenas.
Usar cores vermelhas para dados ruins mesmo quando estatisticamente insignificantes.
Mostrar 3 meses de dados quando 5 anos seriam mais representativos.
NotaResposta
Resposta correta: a) Usar escala logarítmica para dados de crescimento exponencial, desde que indicado.
A escala logarítmica é apropriada para dados exponenciais e, se bem indicada no eixo, é uma escolha honesta. As outras são manipulações: truncar eixo Y em barras distorce volumes, cores alarmantes induzem emoções injustificadas, e selecionar períodos favoráveis é viés de seleção.
Questão 4: Um tratamento reduz o risco absoluto de câncer de 5% para 4%. Qual afirmação é CORRETA?
Reduz risco em 20% (relativo), então é um grande avanço.
Reduz risco em 1% (absoluto), então tem impacto pequeno na população.
Ambas as afirmações são tecnicamente corretas, mas têm implicações diferentes.
Reduz risco em 80%, portanto é revolucionário.
NotaResposta
Resposta correta: c) Ambas as afirmações são tecnicamente corretas, mas têm implicações diferentes.
Redução de 5% para 4% é uma redução relativa de 20% (1/5 = 0,2), mas uma redução absoluta de apenas 1 ponto percentual. Para comunicação responsável, sempre mencione ambas as métricas — e calcule o NNT (neste caso, 100 pessoas precisam ser tratadas para evitar 1 caso).
Leitura Recomendada
Para aprofundamento, recomendamos Huff (1954), Nussbaumer Knaflic (2015) e Tufte (2001).
Conclusão
Os dados não mentem. Mas os gráficos? Eles contam histórias.
E você é responsável pela história que conta.
Na medicina, essa responsabilidade é particularmente pesada. Um gráfico manipulador em uma apresentação de droga pode levar a decisões de prescrição que afetam milhões de pessoas. Um gráfico enganoso em um relatório de saúde pública pode levar a políticas de saúde que moldam nações.
Isso não quer dizer que você nunca deve usar cores vibrantes, ou escolher uma escala logarítmica, ou truncar um eixo. Quer dizer que você deve ter uma razão defensável para cada escolha, e essa razão deve ser servir à verdade, não a sua narrativa.
Quando você está em dúvida, pergunte-se: “Um colega inteligente, cético e de boa fé chegaria às mesmas conclusões com este gráfico?”
Se a resposta for não, repense seu gráfico.
Referências
HUFF, Darrell. How to Lie with Statistics. New York: W. W. Norton & Company, 1954.
NUSSBAUMER KNAFLIC, Cole. Storytelling with Data: A Data Visualization Guide for Business Professionals. Hoboken, NJ: John Wiley & Sons, 2015.
TUFTE, Edward R. The Visual Display of Quantitative Information. 2. ed. Cheshire, Connecticut: Graphics Press, 2001.