Ver código R
| Sexo | N | Percentual |
|---|---|---|
| Mulheres | 234 | 58.1 |
| Homens | 169 | 41.9 |
Quando visualizar (e quando não)
Vamos começar com uma verdade inconveniente: nem toda visualização torna as coisas melhores. Sim, você leu certo. Nós vamos passar este capítulo inteiro falando sobre gráficos, mas a primeira lição é aprender quando não fazer um gráfico.
Considere este exemplo simples:
Uma imagem vale mais que mil palavras — seu gráfico realmente te economizou mil palavras?
Vamos ser práticos. Imagine que você coletou dados sobre o sexo dos participantes em um estudo: 234 mulheres e 169 homens (total de 403 pessoas). Agora, o que comunica melhor essa informação?
Opção 1: Tabela (simples e direta)
| Sexo | N | Percentual |
|---|---|---|
| Mulheres | 234 | 58.1 |
| Homens | 169 | 41.9 |
Opção 2: Gráfico (um pizza chart bem colorido?)
dados_sexo_plot <- tibble::tibble(
Sexo = c("Mulheres", "Homens"),
N = c(234, 169)
)
ggplot(dados_sexo_plot, aes(x = "", y = N, fill = Sexo)) +
geom_col(width = 1) +
coord_polar("y") +
labs(title = "Distribuição por Sexo",
y = NULL, x = NULL) +
tema_graficos() +
scale_fill_manual(values = c("Mulheres" = paleta_cat[1],
"Homens" = paleta_cat[2]))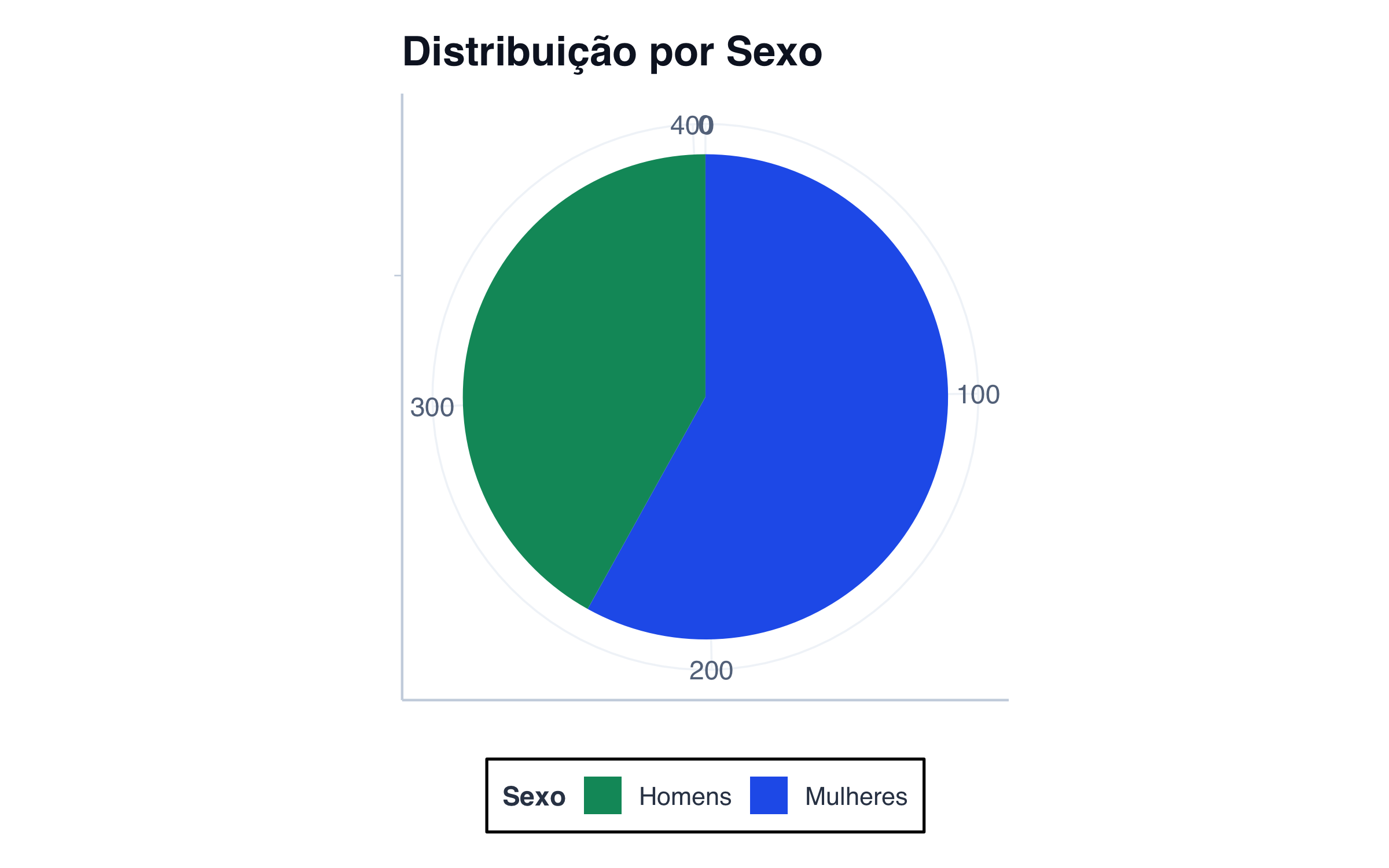
Se você for honesto: a tabela venceu, certo?
Você consegue ler “234 mulheres” da tabela em 2 segundos. Do gráfico de pizza? Leva mais tempo, e você ainda precisa conferir a legenda de cores. Além disso, aquele gráfico de pizza consome espaço precioso — e em um artigo científico, espaço é ouro. Um gráfico ocupa facilmente 10 cm² ou mais da página, espaço suficiente para vários parágrafos de resultados e discussão.
Então, quando usar um gráfico? A resposta é simples:
Use um gráfico quando ele revela padrões que números sozinhos não conseguem mostrar.
Use um gráfico quando:
Não use um gráfico quando:
Mas temos um problema: como saber se você realmente descobriu um padrão? Aqui entra a lição mais importante desta disciplina.
Em 1973, o estatístico Francis Anscombe enfrentou um problema que ainda nos assombra: números podem mentir lindamente (Anscombe, 1973).
Ele criou 4 conjuntos de dados diferentes. Veja só: todos têm exatamente a mesma média, variância, correlação e até a mesma reta de regressão. Vamos começar exatamente como Anscombe fez — mostrando apenas os números:
# Carrega o dataset clássico
data(anscombe)
# Calcula estatísticas para cada conjunto
stats_summary <- tibble::tibble(
Dataset = c("I", "II", "III", "IV"),
"Média X" = c(
round(mean(anscombe$x1), 2),
round(mean(anscombe$x2), 2),
round(mean(anscombe$x3), 2),
round(mean(anscombe$x4), 2)
),
"Média Y" = c(
round(mean(anscombe$y1), 2),
round(mean(anscombe$y2), 2),
round(mean(anscombe$y3), 2),
round(mean(anscombe$y4), 2)
),
"Variância X" = c(
round(var(anscombe$x1), 2),
round(var(anscombe$x2), 2),
round(var(anscombe$x3), 2),
round(var(anscombe$x4), 2)
),
"Variância Y" = c(
round(var(anscombe$y1), 2),
round(var(anscombe$y2), 2),
round(var(anscombe$y3), 2),
round(var(anscombe$y4), 2)
),
"Correlação" = c(
round(cor(anscombe$x1, anscombe$y1), 3),
round(cor(anscombe$x2, anscombe$y2), 3),
round(cor(anscombe$x3, anscombe$y3), 3),
round(cor(anscombe$x4, anscombe$y4), 3)
)
)
knitr::kable(stats_summary,
caption = "Estatísticas descritivas do Quarteto de Anscombe — Todos idênticos!",
align = "c")| Dataset | Média X | Média Y | Variância X | Variância Y | Correlação |
|---|---|---|---|---|---|
| I | 9 | 7.5 | 11 | 4.13 | 0.816 |
| II | 9 | 7.5 | 11 | 4.13 | 0.816 |
| III | 9 | 7.5 | 11 | 4.12 | 0.816 |
| IV | 9 | 7.5 | 11 | 4.12 | 0.817 |
Nesse ponto, a maioria dos estudantes pensa: “Tudo igual? Então são dados iguais.”
Errado! E é por isso que vamos agora plotar essas quatro série de dados — prepare-se para uma surpresa:
# Prepara os dados em formato longo para faceting
anscombe_long <- anscombe %>%
mutate(obs = row_number()) %>%
pivot_longer(
cols = -obs,
names_to = c("var", "dataset"),
names_pattern = "(.)(.)",
values_to = "value"
) %>%
pivot_wider(
names_from = var,
values_from = value
) %>%
mutate(dataset = paste("Dataset", dataset))
# Cria os plots individuais
p_anscombe <- ggplot(anscombe_long, aes(x = x, y = y)) +
geom_point(size = 3, color = paleta_cat[1], alpha = 0.7) +
geom_smooth(method = "lm", se = FALSE, color = paleta_cat[2], linewidth = 1.2) +
facet_wrap(~dataset, nrow = 2, ncol = 2) +
coord_cartesian(xlim = c(3, 19), ylim = c(3, 13)) +
labs(
title = "Quarteto de Anscombe: A Mesma Reta, Dados Completamente Diferentes",
x = "X",
y = "Y"
) +
tema_graficos()
print(p_anscombe)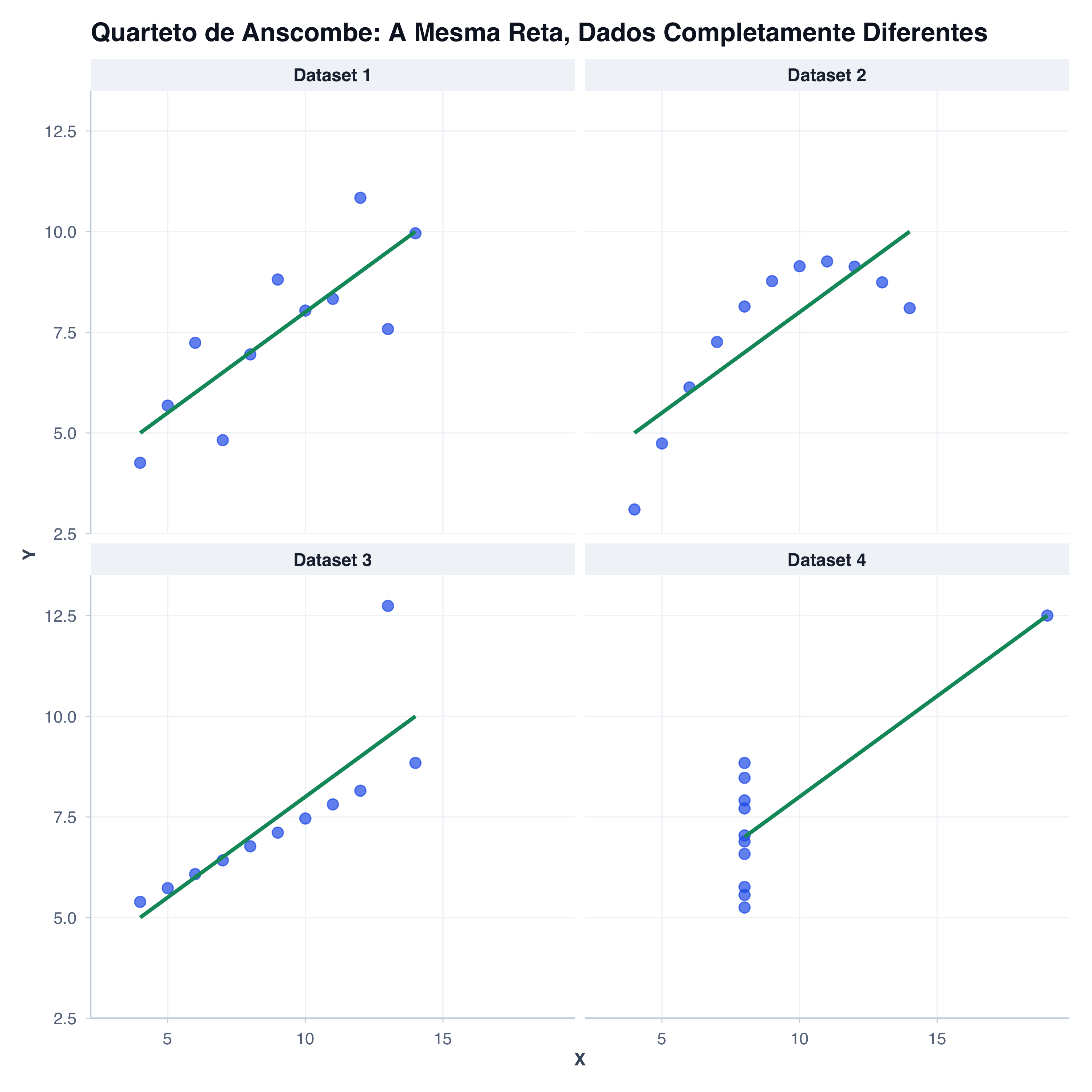
Conclusão: Descrição estatística sozinha é cega. Você precisa visualizar.
Agora vamos criar uma versão interativa em Plotly para você explorar os dados:
# Prepara dados para plotly
anscombe_datasets <- list(
"Dataset I" = list(x = anscombe$x1, y = anscombe$y1),
"Dataset II" = list(x = anscombe$x2, y = anscombe$y2),
"Dataset III" = list(x = anscombe$x3, y = anscombe$y3),
"Dataset IV" = list(x = anscombe$x4, y = anscombe$y4)
)
# Cria figura base
fig <- plot_ly()
# Adiciona cada dataset
for (name in names(anscombe_datasets)) {
dataset <- anscombe_datasets[[name]]
# Pontos
fig <- fig %>%
add_trace(
x = dataset$x, y = dataset$y,
name = name,
mode = "markers",
marker = list(size = 8, opacity = 0.7),
showlegend = TRUE,
hovertemplate = paste0(name, "<br>X: %{x}<br>Y: %{y}<extra></extra>")
)
# Reta de regressão
lm_model <- lm(y ~ x, data = data.frame(x = dataset$x, y = dataset$y))
x_line <- range(dataset$x)
y_line <- predict(lm_model, newdata = data.frame(x = x_line))
fig <- fig %>%
add_trace(
x = x_line, y = y_line,
name = paste(name, "(fit)"),
mode = "lines",
line = list(dash = "dash"),
showlegend = FALSE,
hoverinfo = "skip"
)
}
fig %>%
layout(
title = "Quarteto de Anscombe — Exploração Interativa",
xaxis = list(title = "X", range = c(2, 20)),
yaxis = list(title = "Y", range = c(2, 14)),
hovermode = "closest",
template = "plotly_white"
)Versão interativa do Quarteto de Anscombe
O Quarteto de Anscombe é uma obra-prima dos anos 1970. Mas em 2017, Matejka e Fitzmaurice levaram a ideia ao extremo com o Datasaurus Dozen — 13 conjuntos de dados diferentes, todos com a mesma média, variância e correlação… incluindo um que forma um dinossauro de verdade (Matejka; Fitzmaurice, 2017)!
Vamos começar novamente apenas com números:
# Carrega o datasaurus
data(datasaurus_dozen)
# Calcula estatísticas por dataset
datasaurus_stats <- datasaurus_dozen %>%
group_by(dataset) %>%
summarise(
"Média X" = round(mean(x), 2),
"Média Y" = round(mean(y), 2),
"DP X" = round(sd(x), 2),
"DP Y" = round(sd(y), 2),
"Correlação" = round(cor(x, y), 3),
.groups = "drop"
) %>%
arrange(dataset)
knitr::kable(datasaurus_stats,
caption = "Datasaurus Dozen: 13 datasets com estatísticas idênticas (ou quase)",
align = "c")| dataset | Média X | Média Y | DP X | DP Y | Correlação |
|---|---|---|---|---|---|
| away | 54.27 | 47.83 | 16.77 | 26.94 | -0.064 |
| bullseye | 54.27 | 47.83 | 16.77 | 26.94 | -0.069 |
| circle | 54.27 | 47.84 | 16.76 | 26.93 | -0.068 |
| dino | 54.26 | 47.83 | 16.77 | 26.94 | -0.064 |
| dots | 54.26 | 47.84 | 16.77 | 26.93 | -0.060 |
| h_lines | 54.26 | 47.83 | 16.77 | 26.94 | -0.062 |
| high_lines | 54.27 | 47.84 | 16.77 | 26.94 | -0.069 |
| slant_down | 54.27 | 47.84 | 16.77 | 26.94 | -0.069 |
| slant_up | 54.27 | 47.83 | 16.77 | 26.94 | -0.069 |
| star | 54.27 | 47.84 | 16.77 | 26.93 | -0.063 |
| v_lines | 54.27 | 47.84 | 16.77 | 26.94 | -0.069 |
| wide_lines | 54.27 | 47.83 | 16.77 | 26.94 | -0.067 |
| x_shape | 54.26 | 47.84 | 16.77 | 26.93 | -0.066 |
O Datasaurus Dozen foi criado como resposta moderna ao Quarteto de Anscombe. Os autores queriam mostrar que, mesmo com melhor infraestrutura computacional, ainda confiamos demais em estatísticas descritivas. O dataset com formato de dinossauro é particularmente viral — é impossível resistir ao charme de um T-Rex na hora de visualizar dados!
Agora, prepare-se para a grande revelação — vamos visualizar os 13 datasets todos de uma vez:
p_datasaurus <- ggplot(datasaurus_dozen, aes(x = x, y = y, color = dataset)) +
geom_point(size = 2, alpha = 0.6) +
facet_wrap(~dataset, nrow = 3, ncol = 5) +
tema_graficos() +
scale_color_manual(values = rep(paleta_cat, length.out = 13)) +
theme(
legend.position = "none",
strip.text = element_text(size = 9, face = "bold")
) +
labs(
title = "Datasaurus Dozen: 13 Padrões Completamente Diferentes, Mesmas Estatísticas",
subtitle = "Você consegue encontrar o dinossauro?",
x = "X",
y = "Y"
)
print(p_datasaurus)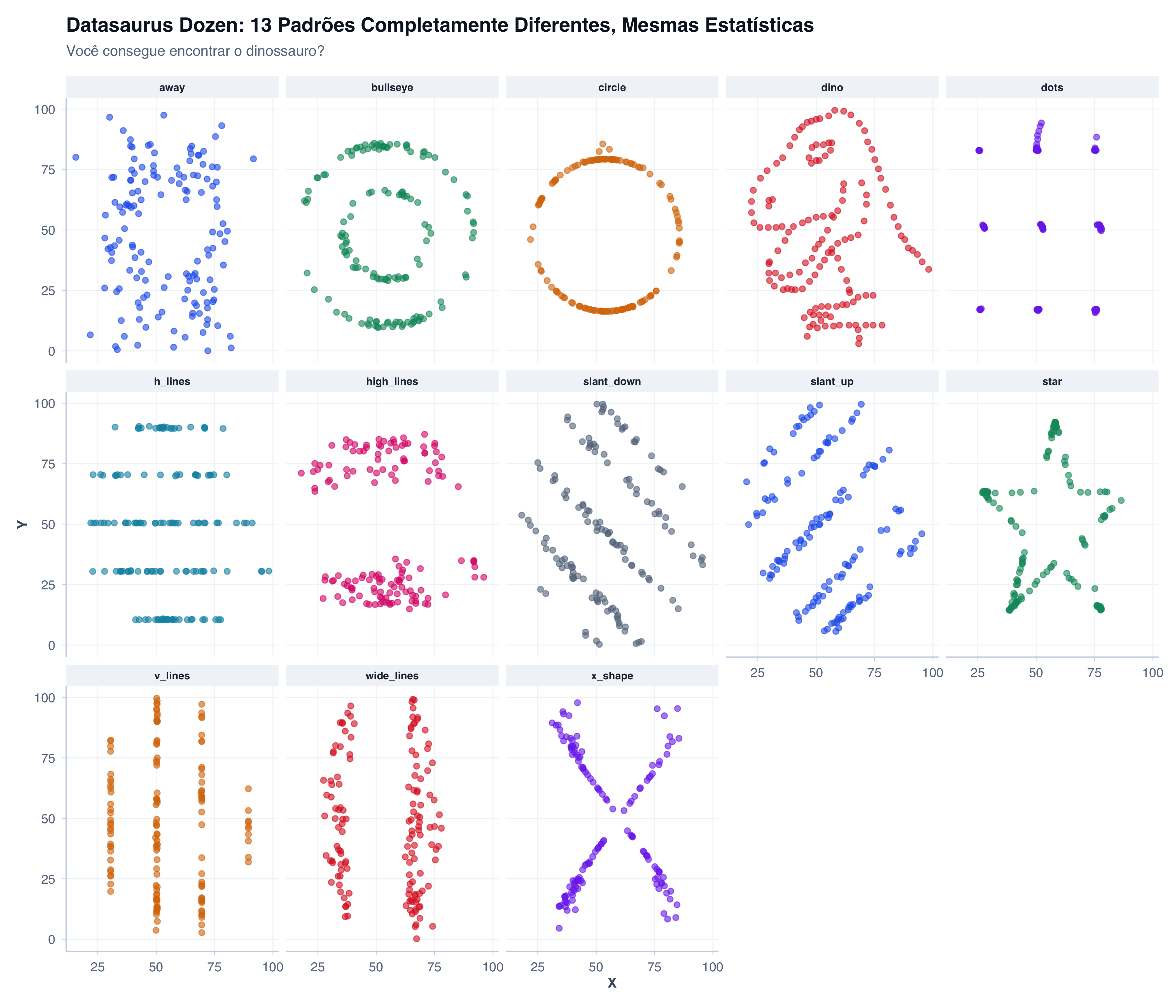
Olhe para o painel dino — É um T-Rex! É claro. Mas tecnicamente, ele tem a mesma média, variância e correlação que todos os outros.
Nunca, jamais, confie em números sozinhos. SEMPRE visualize seus dados.
Essa não é uma sugestão. É uma regra ouro da prática estatística em medicina e pesquisa científica. Quantos erros já foram publicados porque alguém olhou apenas para p-valores e tabelas, sem nunca desenhar um gráfico?
Vamos criar uma versão interativa para você explorar cada dataset individualmente. Selecione um dataset no menu e veja como dados com as mesmas estatísticas formam desenhos completamente diferentes:
library(plotly)
todos_datasets <- unique(datasaurus_dozen$dataset)
# Criar figura plotly com um trace por dataset
fig_dino <- plot_ly()
for (i in seq_along(todos_datasets)) {
ds <- todos_datasets[i]
dados_ds <- filter(datasaurus_dozen, dataset == ds)
# Calcular estatísticas
r_val <- cor(dados_ds$x, dados_ds$y)
media_x <- mean(dados_ds$x)
media_y <- mean(dados_ds$y)
fig_dino <- fig_dino %>%
add_trace(
data = dados_ds,
x = ~x, y = ~y,
type = "scatter", mode = "markers",
name = ds,
marker = list(size = 6, opacity = 0.7, color = paleta_cat[(i %% 8) + 1]),
hovertemplate = paste0(
"<b>", ds, "</b><br>",
"x: %{x:.1f}<br>y: %{y:.1f}<extra></extra>"
),
visible = (i == 1) # Só o primeiro visível
)
}
# Criar botões de dropdown para selecionar dataset
buttons <- lapply(seq_along(todos_datasets), function(i) {
ds <- todos_datasets[i]
dados_ds <- filter(datasaurus_dozen, dataset == ds)
r_val <- round(cor(dados_ds$x, dados_ds$y), 3)
visibility <- rep(FALSE, length(todos_datasets))
visibility[i] <- TRUE
list(
method = "update",
args = list(
list(visible = visibility),
list(title = list(
text = paste0(
"<b>Datasaurus Dozen: ", ds, "</b><br>",
"<span style='font-size:12px; color:gray'>",
"Média X ≈ 54.3 | Média Y ≈ 47.8 | r = ", r_val,
"</span>"
)
))
),
label = ds
)
})
fig_dino %>%
layout(
title = list(
text = paste0(
"<b>Datasaurus Dozen: ", todos_datasets[1], "</b><br>",
"<span style='font-size:12px; color:gray'>",
"Média X ≈ 54.3 | Média Y ≈ 47.8 | r = ",
round(cor(filter(datasaurus_dozen, dataset == todos_datasets[1])$x,
filter(datasaurus_dozen, dataset == todos_datasets[1])$y), 3),
"</span>"
)
),
xaxis = list(title = "X", range = c(10, 100)),
yaxis = list(title = "Y", range = c(0, 100), scaleanchor = "x"),
updatemenus = list(
list(
type = "dropdown",
active = 0,
buttons = buttons,
x = 0.0, y = 1.15,
xanchor = "left",
bgcolor = "#DBEAFE",
font = list(size = 12)
)
),
template = "plotly_white"
) %>%
config(displayModeBar = TRUE, displaylogo = FALSE)Datasaurus Dozen — Selecione cada dataset para explorar
Chegamos ao final desta provação inicial com algumas conclusões:
Nem toda visualização é uma melhoria. Tabelas simples ganham quando os dados são simples.
Gráficos revelam o que números escondem. O Anscombe e o Datasaurus provam isso de forma irrefutável.
No contexto médico e científico, visualizar é obrigatório. Você precisa saber se seus dados fazem sentido antes de fazer qualquer afirmação.
Use gráficos quando eles contam uma história que números não conseguem. Caso contrário, uma tabela com média ± DP é mais honesto e ocupa menos espaço.
Desconfie de correlações, regressões e testes estatísticos que você nunca visualizou. Eles podem estar descrevendo um dinossauro.
Clique para revelar a resposta:
Uma tabela é melhor que um gráfico quando:
Exemplo: “A amostra consistiu de 234 mulheres (58,1%) e 169 homens (41,9%).” — isso é melhor em tabela, ou até em texto, do que em um gráfico de pizza.
Clique para revelar a resposta:
O Quarteto de Anscombe nos ensina a lição fundamental da visualização de dados:
Números idênticos podem descrever realidades completamente diferentes.
Até dados com mesma média, variância, correlação e regressão podem ter:
A consequência: você não pode confiar em estatísticas descritivas sozinhas. Sempre visualize.
Clique para revelar a resposta:
Ambos fazem o mesmo ponto (sempre visualize), mas:
Quarteto de Anscombe (1973): 4 datasets diferentes que parecem iguais estatisticamente. Criado para alertar estatísticos sobre o perigo de confiar em números.
Datasaurus Dozen (2017): 13 datasets, incluindo um com formato de dinossauro real. Criado como versão “moderna e viralável” da mesma lição, mostrando que mesmo com computadores mais poderosos, ainda cometemos o mesmo erro.
O Datasaurus é mais divertido, mais compartilhável nas redes sociais, e igualmente importante educacionalmente.
Clique para revelar a resposta:
Absolutamente não. A correlação, média e desvio padrão do dataset “dino” são indistinguíveis dos outros 12. Você olharia para uma tabela de 142 pares de números (x, y) e nunca, jamais, veria um T-Rex.
Mas quando você plota os pontos em um gráfico, é óbvio.
Essa é uma metáfora perfeita para a vida científica: padrões importantes, anomalias críticas e estruturas fundamentais ficam invisíveis em tabelas numéricas. Apenas a visualização as revela.
Clique para revelar a resposta:
Não. Alguns exemplos assustadores na literatura:
O protocolo correto é:
Em medicina e pesquisa, um bom gráfico pode salvar vidas. Um teste estatístico sem visualização pode enganá-lo para conclusões perigosas.
Agora que você entendeu quando usar gráficos e por que são tão críticos, estamos prontos para aprender como fazer gráficos bem feitos.
No próximo capítulo, entraremos no universo de Gramática de Gráficos — o sistema que nos permite construir qualquer visualização de forma organizada e poderosa usando ggplot2.
Prepare-se para nunca mais ver gráficos da mesma forma.