A visualização de dados científicos sempre exigiu trabalho. Antes dos computadores pessoais, gráficos eram produzidos à mão: papel milimetrado, régua, tinta nanquim. Um pesquisador que desejasse apresentar a distribuição de pressão arterial em uma amostra de pacientes desenhava cada ponto manualmente, calculava médias com tabelas logarítmicas e reproduzia a figura por decalque ou fotografia. O processo era lento, caro e tecnicamente exigente.
Com a chegada dos computadores pessoais nos anos 1980 e 1990, esse processo migrou para a tela. Planilhas eletrônicas — o Lotus 1-2-3 primeiro, o Microsoft Excel depois — tornaram-se o ambiente padrão para análise de dados em praticamente todas as áreas, incluindo as ciências da saúde (Hesse; Hesse Scerno, 2009). O Excel democratizou o acesso aos dados: qualquer profissional com um computador podia calcular médias, construir tabelas e gerar gráficos de barras em minutos. Era uma ruptura real em relação ao papel milimetrado.
Mas o Excel tinha limites sérios para a ciência. Os gráficos produzidos eram visualmente pobres e difíceis de personalizar com precisão. A reprodutibilidade era frágil — refazer exatamente o mesmo gráfico com dados atualizados exigia repetir manualmente cada etapa. A capacidade estatística era limitada. E, sobretudo, o Excel não foi projetado para comunicação científica: faltavam controle tipográfico, suporte a múltiplas camadas estatísticas e integração com os padrões de publicação acadêmica.
Foi nesse contexto que R e Python emergiram como alternativas. Não eram ferramentas de escritório, mas linguagens de programação científica — abertas, gratuitas, construídas pela e para a comunidade acadêmica. Com elas, um pesquisador podia descrever com precisão cada elemento de uma visualização, integrar análise estatística e gráfico no mesmo fluxo de trabalho, e garantir que qualquer colega pudesse reproduzir o resultado exato a partir do mesmo código. A qualidade e o rigor que o Excel não oferecia estavam ali — mas a um preço: era necessário aprender a programar.
Esse custo excluiu sistematicamente uma parcela enorme de pesquisadores na área da saúde. Profissionais tecnicamente sólidos em raciocínio clínico e metodologia, mas sem formação em programação, permaneceram dependentes de colaboradores especializados ou confinados às limitações das planilhas.
R, Python e a Gramática dos Gráficos
R foi criado em 1993 por Ross Ihaka e Robert Gentleman, na Universidade de Auckland (Ihaka; Gentleman, 1996), como uma implementação livre da linguagem S, desenvolvida nos Bell Labs nos anos 1970 (Becker, 1994). Desde o início, seu propósito era explicitamente científico: uma linguagem projetada para análise estatística, não para desenvolvimento de software comercial. Python, criado por Guido van Rossum em 1991 (Severance, 2015), tinha origens mais generalistas, mas ao longo dos anos 2000 foi progressivamente adotado pela comunidade científica, especialmente após o desenvolvimento de bibliotecas como NumPy (Harris et al., 2020), pandas e matplotlib. As duas linguagens convergiram, por caminhos distintos, para o mesmo papel: o padrão de fato da ciência de dados moderna.
No campo específico da visualização, R produziu uma contribuição que merece atenção particular. Em 1999, o estatístico Leland Wilkinson publicou The Grammar of Graphics(Wilkinson, 2005), obra em que propôs uma teoria formal para descrever visualizações de dados. A ideia central era elegante: assim como a gramática de uma língua define regras para combinar palavras em frases com significado, uma gramática dos gráficos definiria regras para combinar elementos visuais — dados, geometrias, escalas, coordenadas, anotações — em representações coerentes e precisas. Um gráfico deixava de ser um objeto monolítico escolhido de um menu e passava a ser uma composição descritível em camadas.
Em 2005, Hadley Wickham, então doutorando na Universidade de Iowa, traduziu essa teoria em código (Wickham, 2010). O pacote ggplot2, publicado para R (Wickham, 2016), implementava a gramática de Wilkinson de forma que qualquer pesquisador pudesse construir visualizações complexas descrevendo seus componentes em linguagem quase declarativa. Em vez de escolher “gráfico de barras” em um menu, o usuário especificava: estes são os dados, esta é a geometria, este é o mapeamento entre variáveis e elementos visuais, esta é a escala, este é o tema. A lógica era consistente e generalizável — aprendida uma vez, aplicava-se a qualquer tipo de gráfico.
O impacto foi significativo. O ggplot2 tornou-se um dos pacotes mais baixados do repositório CRAN (Hornik, 2012) e estabeleceu-se como referência em publicações científicas de alto impacto, especialmente nas ciências biológicas e da saúde. Em Python, bibliotecas como Seaborn e Plotly seguiram princípios similares, expandindo o alcance da abordagem para a comunidade que trabalhava nessa linguagem.
O resultado foi um novo padrão. Pesquisadores que dominavam essas ferramentas produziam visualizações mais precisas, mais reproduzíveis e mais adequadas à comunicação científica do que qualquer alternativa baseada em planilhas. A distância entre o Excel e o ggplot2 não era apenas estética — era epistemológica. Um gráfico produzido em código podia ser auditado, replicado e modificado por qualquer pesquisador com acesso ao mesmo arquivo. Um gráfico produzido em planilha raramente oferecia essa garantia.
Mas a exigência permanecia: era necessário aprender a programar. E para um estudante de medicina com grade curricular já saturada, esse requisito continuava sendo, na prática, uma barreira bastante difícil.
Inteligência Artificial
Em novembro de 2022, a OpenAI lançou publicamente o ChatGPT. Em poucas semanas, o sistema havia sido adotado por milhões de usuários em contextos que seus criadores mal haviam antecipado — entre eles, a geração de código (Nejjar et al., 2025). Pesquisadores, estudantes e profissionais sem formação em programação — incluindo na área da saúde (Cascella et al., 2023; Mesko, 2023) — descobriram que podiam descrever em linguagem natural o que desejavam fazer computacionalmente e receber, em segundos, código funcional. A barreira que separava a intenção da execução havia mudado de natureza.
Para a visualização de dados científicos, as implicações foram imediatas. Um estudante que nunca havia escrito uma linha de R podia agora descrever um gráfico em português — “quero um boxplot comparando a pressão sistólica entre homens e mulheres, com tema limpo e eixos em português” — e receber código ggplot2 pronto para executar. Não era necessário conhecer a sintaxe do pacote, entender a lógica de camadas ou saber instalar dependências. A IA funcionava como uma intermediária entre a intenção do pesquisador e a linguagem que a ferramenta compreendia.
Três Formas de Trabalhar com IA para Gráficos
Nem todas as ferramentas de inteligência artificial para visualização de dados funcionam da mesma forma, nem se destinam aos mesmos contextos. Antes de apresentar as opções disponíveis, é útil estabelecer uma distinção fundamental que orientará a escolha do pesquisador em cada situação.
Existem três modos distintos de trabalhar com IA para produzir gráficos científicos, e compreender a diferença entre eles é mais importante do que conhecer qualquer ferramenta específica. O primeiro é a conversa direta com os dados, em que o pesquisador envia sua planilha para uma plataforma online e recebe o gráfico como resultado, sem ver código e sem instalar nada. O segundo é a assistência dentro do ambiente de desenvolvimento, em que a IA opera dentro de um editor de código especializado, gerando código R ou Python visível e reproduzível enquanto o pesquisador trabalha. O terceiro — e mais recente — é o trabalho autônomo sobre o projeto, em que a IA recebe acesso a uma pasta de trabalho e age como um colaborador que lê arquivos, cria estruturas, edita documentos e executa tarefas encadeadas, enquanto o pesquisador dirige o processo por conversa.
A distinção entre os três modos não é hierárquica. São instrumentos diferentes para momentos diferentes do trabalho científico. A pergunta relevante para escolher entre eles é simples: o que você vai fazer com o gráfico depois, e quanto controle precisa ter sobre o processo?
Modo 1 — Conversa Direta: você envia os dados, recebe o gráfico
Neste modo, o pesquisador não escreve código em nenhum momento. O fluxo de trabalho é direto: carregar a planilha ou arquivo de dados em uma plataforma, descrever o gráfico desejado em linguagem natural e baixar o resultado. Toda a execução técnica — escolha de bibliotecas, escrita do código, geração da figura — ocorre de forma invisível, intermediada pela plataforma.
Este modo é particularmente adequado para pesquisadores sem qualquer familiaridade com programação, para situações em que o tempo disponível é limitado ou para a fase inicial de exploração de um conjunto de dados, quando o objetivo é ter uma visão geral antes de decidir quais análises aprofundar. O resultado, neste caso, é uma imagem — um arquivo estático que não documenta como foi produzido e que, portanto, não oferece garantias de reprodutibilidade para fins de publicação científica.
As principais plataformas disponíveis para este modo são as seguintes.
ChatGPT com Análise de Dados Avançada é provavelmente o ponto de entrada mais acessível, dado que a maioria dos estudantes já possui conta na plataforma. Nas versões pagas mais recentes, é possível carregar arquivos nos formatos CSV, Excel e PDF diretamente na conversa e solicitar gráficos em linguagem natural. Os gráficos gerados podem ser baixados como imagem. A limitação principal é que o ambiente é efêmero — os dados e o código não persistem entre sessões.
Julius AI (julius.ai) é uma plataforma especializada em análise de dados conversacional, construída sobre modelos de linguagem de grande porte. Diferentemente do ChatGPT, que é uma ferramenta generalista, o Julius foi projetado especificamente para análise de dados e oferece suporte tanto a Python quanto a R. A plataforma executa as análises em etapas visíveis, exibindo o raciocínio intermediário antes do resultado final — comportamento que facilita a identificação de eventuais erros de interpretação. Oferece plano gratuito com limitações de uso mensal.
Google Gemini integra-se naturalmente ao ecossistema Google e permite análise de planilhas diretamente do Google Sheets. Para pesquisadores que já utilizam o Google Drive como repositório de dados, esta integração elimina a necessidade de exportar e importar arquivos.
Microsoft Copilot no Excel incorpora IA diretamente no ambiente de planilhas mais utilizado no mundo. Para pesquisadores cujos dados já residem em arquivos Excel, esta opção elimina completamente a necessidade de migração para outra plataforma. A disponibilidade desta funcionalidade depende da versão do Microsoft 365 utilizada pela instituição.
Powerdrill AI é uma alternativa ao Julius com foco em conjuntos de dados de maior volume, suportando arquivos que excedem os limites das demais plataformas.
Modo 2 — IA dentro do Editor: o código aparece enquanto você trabalha
Neste modo, a IA opera como um assistente dentro de um ambiente de desenvolvimento integrado. O pesquisador não precisa conhecer a sintaxe de R ou Python previamente, mas o código gerado pela IA é visível, editável e, sobretudo, reproduzível. Este modo produz resultados que podem ser auditados, compartilhados e integrados a documentos científicos com garantia de reprodutibilidade.
A reprodutibilidade merece ênfase. Um gráfico gerado no Modo 1 existe como imagem — um arquivo estático que não documenta como foi produzido. Um gráfico gerado no Modo 2 existe como código: qualquer pesquisador com acesso ao mesmo arquivo pode reproduzir exatamente o mesmo resultado, modificar parâmetros e verificar cada decisão metodológica. Para publicação científica, esta diferença é fundamental.
As principais ferramentas disponíveis para este modo são as seguintes.
Positron é o ambiente de desenvolvimento lançado pela Posit — a mesma empresa responsável pelo RStudio — e representa a evolução mais relevante para pesquisadores que trabalham com R e Python. Gratuito e de código aberto, o Positron incorpora nativamente o Positron Assistant, um assistente de IA com acesso ao estado real da sessão de trabalho: os dados carregados na memória, as variáveis criadas, os gráficos já gerados. Esta consciência contextual diferencia o Positron Assistant de assistentes genéricos — ao solicitar um gráfico, o assistente já sabe quais colunas existem no conjunto de dados, quais são seus tipos e o que já foi produzido anteriormente na mesma sessão. O assistente utiliza os modelos Claude, da Anthropic, e requer uma chave de API para funcionamento. O Positron suporta nativamente documentos Quarto, o que o torna o ambiente natural para pesquisadores que produzem artigos, relatórios e livros neste formato.
RStudio com GitHub Copilot é a opção para pesquisadores que já utilizam o RStudio e preferem não migrar de ambiente. O GitHub Copilot pode ser integrado como assistente, oferecendo sugestões de código em linha e respostas em linguagem natural, embora com acesso menos profundo ao estado da sessão R do que o Positron Assistant.
Visual Studio Code com GitHub Copilot é a combinação mais utilizada entre desenvolvedores em geral e funciona adequadamente para análise de dados em R e Python, com extensões maduras para ambas as linguagens.
Cursor é um editor construído sobre a base do VS Code, mas com integração de IA substancialmente mais profunda. Diferentemente do Copilot, que opera principalmente sobre o arquivo aberto, o Cursor indexa todo o projeto e mantém contexto sobre múltiplos arquivos simultaneamente — uma vantagem para projetos de análise com estrutura complexa.
Modo 3 — IA como Colaborador Autônomo: você entrega o projeto, ela trabalha
Este é o modo mais recente e, para muitos fluxos de trabalho científicos, o mais transformador. Aqui, a IA não opera dentro de um editor aberto pelo pesquisador — ela recebe acesso a uma pasta de trabalho e age com autonomia sobre o sistema de arquivos: lê os arquivos existentes, cria novos, organiza estruturas de pastas, edita documentos específicos e executa tarefas encadeadas. O pesquisador não precisa estar dentro de nenhum ambiente de desenvolvimento. Ele dirige o processo por conversa e revisa os resultados produzidos.
A distinção fundamental em relação ao Modo 2 está na natureza da interação. No Modo 2, a IA sugere e o pesquisador aceita ou rejeita cada sugestão dentro do editor. No Modo 3, o pesquisador descreve o que quer — “crie a estrutura de um projeto Quarto com pastas para imagens, scripts e referências BibTeX” — e encontra o resultado já materializado na pasta, pronto para ser revisado e continuado.
Para pesquisadores que trabalham com projetos Quarto de maior complexidade — livros, relatórios encadeados, artigos com múltiplas figuras e referências bibliográficas gerenciadas por BibTeX —, este modo oferece uma capacidade que os modos anteriores não alcançam: a possibilidade de delegar não apenas a geração de um gráfico, mas a organização e o desenvolvimento progressivo de um projeto inteiro.
A ferramenta que atualmente oferece esta modalidade de forma mais completa é o Claude Cowork, da Anthropic. Na prática, o fluxo de trabalho típico combina o Modo 3 com o Modo 2: o Cowork é utilizado para estruturar o projeto, criar e editar arquivos específicos e executar tarefas que envolvem múltiplos componentes simultaneamente; o Positron é utilizado para edição direta de arquivos individuais quando o pesquisador prefere intervir manualmente em um ponto específico do código ou do documento. Os dois ambientes coexistem e se complementam — o Cowork cuida da arquitetura e da delegação, o Positron cuida da edição de precisão.
Este fluxo híbrido representa, até onde se sabe, uma das fronteiras mais avançadas do trabalho científico assistido por IA atualmente disponíveis ao pesquisador individual. Não exige formação em programação, mas exige clareza sobre o que se quer produzir — o que, no fundo, sempre foi a competência central do bom pesquisador.
Exemplos
O melhor modo de compreender como esses três modos se articulam na prática é acompanhar um cenário realista. O exemplo a seguir não é um tutorial passo a passo — é uma narrativa de como um estudante de medicina sem qualquer formação em programação poderia, hoje, produzir visualizações de qualidade científica a partir de dados reais.
O Cenário
Carolina é estudante de medicina no quarto período. Durante o internato eletivo no ambulatório de cardiologia, coletou dados de 80 pacientes hipertensos acompanhados pela equipe: idade, sexo, pressão sistólica, pressão diastólica, IMC, tabagismo e classe de medicamento anti-hipertensivo em uso. Os dados estão organizados em uma planilha Excel. Seu orientador pediu uma análise descritiva para discutir na reunião de sexta-feira — e mencionou, de passagem, que gostaria de incluir as figuras em um artigo que está escrevendo.
Carolina nunca usou R. Nunca usou Python. Conhece o Excel razoavelmente bem.
Primeira Etapa — Exploração Rápida (Modo 1)
A reunião é na sexta. É quarta-feira à noite. Carolina não tem tempo para aprender uma linguagem de programação.
Ela abre o Julius AI, cria uma conta gratuita e faz o upload da planilha Excel. Em seguida, digita na caixa de conversa:
“Quero um boxplot comparando a pressão sistólica entre homens e mulheres. Eixos em português, tema limpo.”
Em menos de um minuto, o Julius executa o código internamente, exibe o raciocínio intermediário — qual biblioteca utilizou, como tratou os dados — e apresenta o gráfico. Carolina examina o resultado. A distribuição faz sentido com o que observou clinicamente: homens com mediana ligeiramente mais alta, maior dispersão nas mulheres. Ela pede um ajuste:
“Adiciona o número de pacientes em cada grupo no subtítulo.”
O gráfico é atualizado. Ela baixa a imagem e leva para a reunião.
Na sexta, o orientador aprova a análise e confirma: quer incluir as figuras no artigo. Um gráfico gerado como imagem pelo Julius não é suficiente para isso — não há código, não há reprodutibilidade, não há como o revisor da revista verificar como a figura foi produzida. Carolina precisa de algo diferente para a etapa seguinte.
Segunda Etapa — Estruturar o Projeto (Modo 3)
De volta ao computador, Carolina abre o Claude Cowork. Ela não sabe como organizar um projeto científico em Quarto — nunca usou a ferramenta. Mas sabe descrever o que precisa:
“Preciso criar um projeto Quarto para um artigo científico. Quero uma pasta para as imagens geradas, uma pasta para os scripts R, uma pasta para as referências em formato BibTeX, e um arquivo principal .qmd já configurado com título, autor e seções básicas de um artigo de medicina.”
O Cowork lê o pedido, cria a estrutura de pastas e arquivos diretamente no diretório de trabalho de Carolina. Quando ela abre o explorador de arquivos, encontra o projeto já organizado: manuscript.qmd, references/bibliography.bib, scripts/analysis.R, figures/. O arquivo .qmd principal já contém o cabeçalho YAML configurado, as seções Introdução, Métodos, Resultados e Discussão, e as instruções de importação do BibTeX.
Carolina não escreveu uma linha de código. Não precisou.
Ao longo dos dias seguintes, ela usa o Cowork para tarefas que envolvem múltiplos arquivos: pede que o script de análise seja atualizado para incluir uma nova variável, solicita que uma referência específica seja adicionada ao arquivo BibTeX, pede que uma figura seja movida para a pasta correta e referenciada no documento principal. O Cowork executa cada uma dessas tarefas diretamente nos arquivos — Carolina revisa o resultado e decide se aprova ou pede ajuste.
Terceira Etapa — Produzir os Gráficos para Publicação (Modo 2)
Com o projeto estruturado, Carolina abre o Positron. O arquivo analysis.R já existe na pasta, criado pelo Cowork com a estrutura básica. Ela clica no painel do Positron Assistant e escreve:
“Tenho um dataframe chamado ‘pacientes’ com as colunas: idade, sexo, pas, pad, imc, tabagismo, medicamento. Quero um boxplot de pressão sistólica por sexo, com tema minimalista, eixos em português e paleta de cores adequada para publicação científica.”
O Positron Assistant responde com código ggplot2. Diferentemente de um assistente genérico, ele já sabe que o dataframe pacientes está carregado na sessão — vê as colunas, os tipos de variável, os valores presentes. O código gerado é imediatamente executável. Carolina clica em executar. O gráfico aparece no painel de visualização do Positron.
Ela examina o resultado com olhar clínico, não técnico. A escala do eixo Y está adequada para os valores de pressão arterial? A distinção entre os grupos está visualmente clara? A figura comunica o que precisa comunicar para um leitor da área? Ela identifica um ponto: quer adicionar os valores medianos explicitamente sobre cada boxplot. Digita para o assistente:
“Adiciona a mediana como valor numérico sobre cada boxplot.”
O código é atualizado. Ela executa novamente. Aprova. Salva a figura na pasta figures/ e a referencia no documento .qmd.
O processo se repete para as demais figuras do artigo. Em nenhum momento Carolina precisou memorizar a sintaxe do ggplot2, entender o funcionamento interno das camadas ou consultar a documentação do pacote. Precisou, no entanto, de algo que nenhuma IA substitui: saber o que estava olhando, reconhecer quando o resultado fazia sentido clínico e estatístico, e formular perguntas precisas sobre seus próprios dados.
O que Este Exemplo Ilustra
O percurso de Carolina não é linear nem hierárquico. Ela transitou entre três modos conforme a necessidade de cada momento: o Modo 1 para exploração rápida quando o tempo era o fator limitante; o Modo 3 para estruturar e delegar tarefas que envolviam múltiplos arquivos; o Modo 2 para produzir código reproduzível quando o destino era a publicação científica. As ferramentas não competem entre si — complementam-se.
O elemento constante em todas as etapas não foi técnico. Foi a capacidade de Carolina de formular perguntas clínicas precisas, reconhecer quando os resultados faziam sentido com o que ela sabia sobre os dados e identificar o que precisava ser ajustado. Essa capacidade não foi fornecida pela IA. Foi construída ao longo da formação médica — e é exatamente ela que transforma o acesso às ferramentas em conhecimento útil.
Como Pedir Bem: a Lógica do Prompt Clínico
A qualidade do gráfico produzido pela IA depende, em larga medida, da qualidade do pedido que o pesquisador faz. Este é um ponto que merece atenção — não porque exija habilidade técnica especial, mas porque exige precisão conceitual.
Para ilustrar concretamente, vamos usar um dataset fictício de 80 pacientes hipertensos — o mesmo cenário de Carolina, que conhecemos na seção anterior. Considere os dois pedidos a seguir, feitos para o mesmo conjunto de dados:
Dataset fictício de pacientes hipertensos (primeiros 10 registros)
ID
Idade
Sexo
PAS (mmHg)
PAD (mmHg)
IMC (kg/m²)
Tabagismo
Medicamento
1
70
Masculino
140
88
31.3
Não
Diurético
2
64
Feminino
139
94
29.5
Não
Betabloqueador
3
57
Feminino
122
79
34.2
Não
BRA
4
55
Masculino
141
90
29.4
Sim
Betabloqueador
5
72
Feminino
132
100
31.1
Não
Inibidor da ECA
6
74
Feminino
146
76
26.9
Não
Inibidor da ECA
7
64
Masculino
126
79
25.2
Não
Betabloqueador
8
56
Feminino
125
90
28.8
Sim
Inibidor da ECA
9
43
Feminino
135
99
33.1
Não
BRA
10
45
Masculino
154
93
39.1
Não
Betabloqueador
Agora, observe a diferença entre um pedido vago e um pedido preciso — e o que cada um produz.
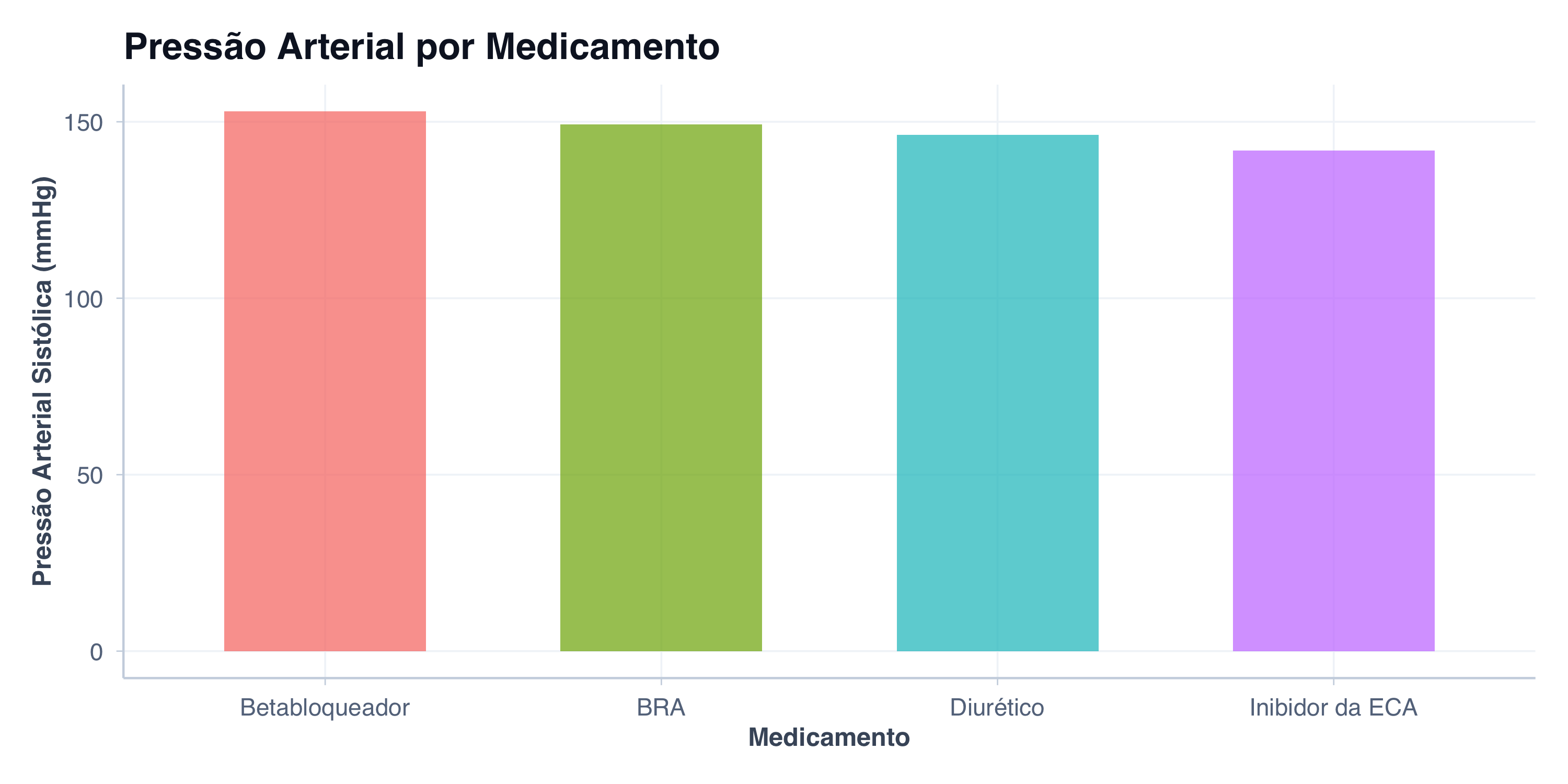
“Faça um gráfico de pressão arterial.”
Ver código R
# Resultado provável de um prompt vagoggplot(hipertensos, aes(x = medicamento, y = pas, fill = medicamento)) +geom_bar(stat ="summary", fun = mean, alpha =0.7, width =0.6) +tema_graficos() +labs(title ="Pressão Arterial por Medicamento",x ="Medicamento",y ="Pressão Arterial Sistólica (mmHg)" ) +theme(legend.position ="none")
O resultado é um gráfico genérico: barras com médias, sem medida de dispersão, sem foco em nenhuma comparação clínica específica. A IA fez algo — mas não fez o que o pesquisador precisava.
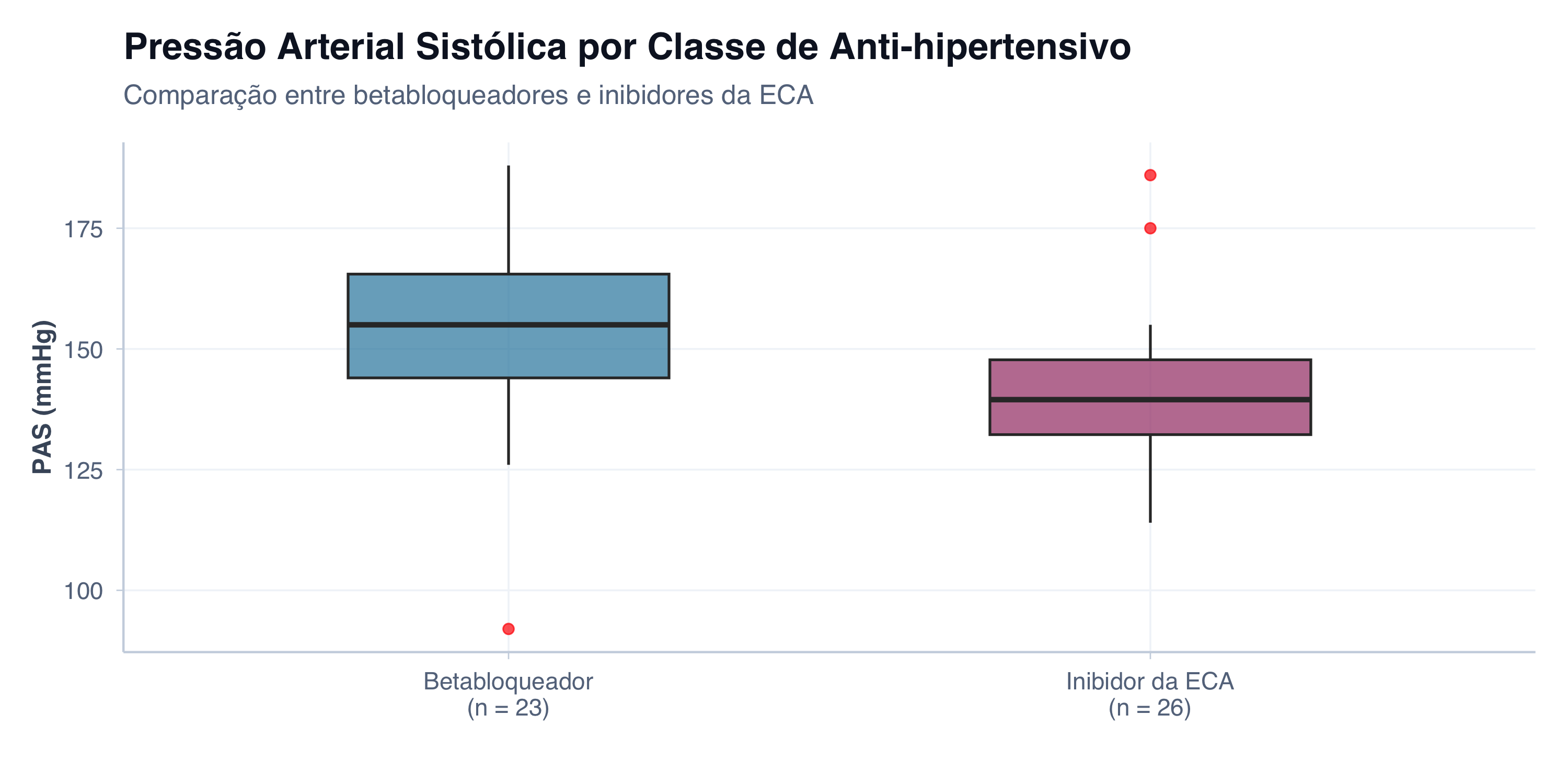
Agora, o mesmo dataset com um pedido preciso:
“Quero um boxplot comparando a pressão arterial sistólica entre pacientes em uso de betabloqueadores e pacientes em uso de inibidores da ECA. Os dados estão na coluna ‘pas’ e a classe do medicamento está na coluna ‘medicamento’. Usa tema minimalista, eixos em português, sem legenda. Inclui o número de pacientes em cada grupo abaixo do rótulo do eixo X.”
Ver código R
# Resultado de um prompt precisohipertensos_filtrado <- hipertensos |>filter(medicamento %in%c("Betabloqueador", "Inibidor da ECA"))# Calcular n por grupo para rótulos do eixo Xn_por_grupo <- hipertensos_filtrado |>count(medicamento) |>mutate(label =paste0(medicamento, "\n(n = ", n, ")"))rotulos <-setNames(n_por_grupo$label, n_por_grupo$medicamento)ggplot(hipertensos_filtrado, aes(x = medicamento, y = pas, fill = medicamento)) +geom_boxplot(alpha =0.7, width =0.5, outlier.color ="red", outlier.size =2) +scale_x_discrete(labels = rotulos) +scale_fill_manual(values =c("Betabloqueador"="#2E86AB", "Inibidor da ECA"="#A23B72")) +tema_graficos() +labs(title ="Pressão Arterial Sistólica por Classe de Anti-hipertensivo",subtitle ="Comparação entre betabloqueadores e inibidores da ECA",x ="",y ="PAS (mmHg)" ) +theme(legend.position ="none")
A diferença é evidente. O primeiro pedido deixa para a IA todas as decisões relevantes: que variável usar, que tipo de gráfico, que comparação fazer, que estética adotar. O resultado é um gráfico — mas não o gráfico que o pesquisador precisava. O segundo pedido especifica a pergunta clínica subjacente, as variáveis envolvidas, o tipo de visualização adequado e as exigências de apresentação. O resultado é exatamente o que o pesquisador queria.
A estrutura de um bom pedido para geração de gráficos pode ser organizada em quatro elementos, que correspondem a quatro perguntas que o pesquisador deve ser capaz de responder antes de abrir qualquer ferramenta.
Qual é a pergunta clínica ou científica que o gráfico responde? Esta é a pergunta mais importante — e a que a IA menos consegue responder sozinha. Um gráfico não é uma decoração; é um argumento visual. Antes de pedir qualquer visualização, o pesquisador deve saber exatamente o que quer demonstrar ou explorar. “A pressão sistólica difere entre as classes de medicamento?” é uma pergunta. “Fazer um gráfico de pressão arterial” não é.
Que variáveis estão envolvidas, e de que tipo são? A escolha do tipo de gráfico mais adequado depende da natureza das variáveis. Uma variável contínua comparada entre grupos categóricos sugere boxplot ou violin plot. Duas variáveis contínuas sugerem diagrama de dispersão. Uma variável categórica com frequências sugere gráfico de barras. A IA pode fazer essa escolha automaticamente — mas frequentemente erra quando o pedido é ambíguo. Especificar as variáveis pelo nome exato que aparecem na planilha, e informar seu tipo, elimina grande parte dos erros.
Para que contexto é o gráfico? Um gráfico para uma apresentação em reunião de equipe tem exigências diferentes de um gráfico para submissão a um periódico científico. O primeiro pode ser mais informal, com cores mais vivas e menos precisão nos detalhes. O segundo precisa atender a padrões tipográficos, ter resolução adequada para impressão e documentar as escolhas metodológicas em código reproduzível. Informar o contexto ao assistente melhora significativamente a adequação do resultado.
Há alguma exigência específica de apresentação? Idioma dos rótulos, paleta de cores, presença ou ausência de legenda, inclusão de valores estatísticos sobre o gráfico, número de pacientes por grupo — esses detalhes fazem a diferença entre um gráfico funcional e um gráfico publicável. Quanto mais desses elementos forem especificados no pedido inicial, menos ciclos de refinamento serão necessários.
Esses quatro elementos não precisam ser apresentados em formato de lista no pedido — podem ser incorporados naturalmente em um parágrafo de linguagem corrente. O que importa é que o pesquisador tenha as respostas antes de começar. Um pedido bem formulado para a IA é, antes de tudo, evidência de que o pesquisador entende seus próprios dados.
Vale registrar uma observação sobre idioma. As ferramentas de IA contemporâneas compreendem e respondem adequadamente em português. Não é necessário formular pedidos em inglês para obter melhores resultados — e formular em português tem a vantagem de produzir rótulos, títulos e legendas já no idioma correto, sem necessidade de tradução posterior. Para pesquisadores que produzem em português, esta é a abordagem mais eficiente.
A IA Ainda Erra
A apresentação das ferramentas nas seções anteriores pode criar uma impressão equivocada: a de que a IA é um sistema confiável que produz resultados corretos desde que receba pedidos bem formulados. Essa impressão precisa ser corrigida antes de encerrar o capítulo.
A IA erra. Erra com frequência, erra de formas específicas e previsíveis, e — o que é mais relevante — erra silenciosamente. Diferentemente de um erro de sintaxe em R, que interrompe a execução e exibe uma mensagem de aviso, um erro conceitual da IA produz um gráfico visualmente impecável que está estatisticamente ou clinicamente errado. O pesquisador que não sabe o que está olhando não tem como detectar o problema.
Esta seção não tem o objetivo de desencorajar o uso das ferramentas. Tem o objetivo de calibrar as expectativas e tornar explícita a responsabilidade que permanece intransferível: a do pesquisador que conhece seus dados, seu contexto clínico e sua pergunta científica.
A IA não Conhece o Contexto Clínico dos Dados
As ferramentas de IA trabalham com estrutura — colunas, tipos de variável, distribuições numéricas. Não trabalham com significado clínico. Isso cria uma categoria de erros que nenhum refinamento de prompt elimina completamente.
Se uma coluna chamada “glicose” contém o valor 340 mg/dL em um registro, a IA não sabe se esse é um valor real de um paciente diabético descompensado, um erro de digitação ou um outlier que deve ser excluído antes da análise. Se uma coluna chamada “sexo” contém as entradas “M”, “masculino” e “Masculino”, a IA pode tratar essas como três categorias distintas — e produzir um gráfico com três grupos onde deveriam existir dois, sem qualquer aviso. Se os dados incluem medidas repetidas do mesmo paciente em momentos diferentes, a IA não sabe que comparar esses grupos como amostras independentes seria metodologicamente inadequado.
Esses erros não são falhas das ferramentas — são consequências inevitáveis da ausência de contexto clínico. A solução não é técnica: é o pesquisador examinar seus dados antes de pedir qualquer gráfico, verificar inconsistências, confirmar que os valores estão dentro de limites biologicamente plausíveis e entender a estrutura do conjunto de dados que está analisando.
A IA não Escolhe o Tipo de Gráfico Correto por Você
A escolha do tipo de visualização mais adequado para uma determinada pergunta científica é uma decisão metodológica, não estética. A IA tende a produzir o gráfico mais comum para o tipo de variável que detecta — o que frequentemente é adequado, mas nem sempre.
Um exemplo recorrente: ao receber uma variável categórica no eixo X e uma variável contínua no eixo Y, sem instruções adicionais, alguns modelos de linguagem geram gráficos de linha conectando as categorias. Isso está errado. Linhas implicam continuidade e ordenação — adequadas para séries temporais ou variáveis ordinais com progressão clara, não para categorias nominais como tipos de medicamento, diagnósticos ou especialidades médicas. O gráfico resultante é visualmente fluente e analiticamente incorreto.
O pesquisador que compreende minimamente os princípios de visualização de dados — apresentados nos capítulos anteriores deste livro — está equipado para identificar esse tipo de erro imediatamente. O pesquisador que delega também a decisão sobre o tipo de gráfico à IA está vulnerável a erros que não saberá detectar.
A IA não Verifica Pressupostos Estatísticos
Quando solicitada a adicionar uma linha de regressão linear a um diagrama de dispersão, a IA adiciona. Se não for explicitamente solicitado, a IA não verifica se a relação entre as variáveis é de fato linear; não testa a normalidade dos resíduos, não identifica pontos influentes que distorcem a estimativa; não avisa que, com aquela distribuição específica, uma transformação logarítmica seria mais apropriada.
O mesmo vale para outros elementos estatísticos que a IA incorpora automaticamente em gráficos: intervalos de confiança calculados sem verificação de pressupostos, barras de erro que podem representar desvio padrão ou erro padrão sem distinção clara, testes de significância aplicados sem consideração sobre o poder estatístico da amostra.
A IA executa o que foi pedido — e frequentemente executa bem. Mas a responsabilidade de verificar se o que foi pedido é estatisticamente adequado para os dados em questão continua sendo do pesquisador.
A IA Alucina
Modelos de linguagem de grande porte produzem, ocasionalmente, código que contém referências a funções inexistentes, argumentos inválidos ou pacotes que não existem. Este fenômeno — denominado alucinação no vocabulário técnico da área (Ji et al., 2023) — ocorre com frequência suficiente para merecer atenção sistemática.
Na prática, isso significa que nem todo código gerado pela IA executa sem erros. Antes de incorporar qualquer figura produzida por IA em um documento científico, o pesquisador deve executar o código em seu ambiente local e verificar que o resultado corresponde ao esperado.
A verificação não exige expertise em programação. Exige o hábito de testar antes de confiar — o mesmo hábito que a medicina clínica desenvolve em relação a qualquer resultado de exame complementar.
A Responsabilidade como Competência
Seria possível apresentar esses limites como uma lista de advertências — um conjunto de ressalvas que o pesquisador deve memorizar antes de usar as ferramentas. Esta não é, no entanto, a perspectiva mais útil.
Os limites descritos acima não são peculiaridades das ferramentas de IA. São, em sua maioria, os mesmos limites que existiam quando o pesquisador dependia de um colaborador humano para produzir seus gráficos: o colaborador também não conhecia o contexto clínico dos dados, também podia escolher o tipo errado de visualização, também podia aplicar uma regressão sem verificar os pressupostos. A diferença é que o colaborador humano estava presente para receber perguntas e oferecer justificativas — e essa presença criava um circuito de verificação que a IA não reproduz automaticamente.
O que a IA exige do pesquisador é, portanto, o mesmo que qualquer ferramenta poderosa exige: que quem a utiliza saiba o suficiente para avaliar o resultado. Não é necessário saber construir a ferramenta. É necessário saber julgar o que ela produziu.
Esta é, no fundo, a competência que distingue o pesquisador do usuário passivo — e é uma competência que a formação médica, com sua ênfase em raciocínio diagnóstico, avaliação crítica de evidências e responsabilidade sobre decisões com consequências reais, está particularmente bem posicionada para desenvolver.
O Momento Atual: uma Janela que se Abriu
Durante décadas, produzir visualizações científicas de qualidade exigiu um investimento técnico que a maioria dos pesquisadores na área da saúde simplesmente não tinha condições de fazer. O papel milimetrado cedeu lugar ao Excel, o Excel cedeu lugar ao R e ao Python — mas cada transição manteve, de formas diferentes, uma barreira de entrada que separava quem sabia programar de quem não sabia. A qualidade estava disponível, mas não era acessível.
Essa barreira não foi gradualmente reduzida. Foi removida de forma abrupta, em um período de menos de três anos, por ferramentas que transformaram linguagem natural em código executável. O estudante de medicina que hoje descreve em português o gráfico que precisa e recebe código ggplot2 funcional em segundos não está usando um atalho — está usando o estado atual da tecnologia disponível. A exigência de que pesquisadores clínicos internalizassem sintaxe de programação antes de produzir ciência de qualidade nunca foi uma necessidade intrínseca à boa pesquisa. Era um custo de acesso. Esse custo desapareceu.
O que permanece — e o que este capítulo buscou tornar explícito — é que o desaparecimento da barreira técnica não eliminou a necessidade de competência intelectual. Pelo contrário: ao remover o obstáculo da sintaxe, as ferramentas de IA tornaram mais visível o que sempre foi o núcleo do trabalho científico. Formular a pergunta certa. Conhecer os dados com suficiente profundidade para reconhecer quando um resultado não faz sentido. Escolher a representação visual que comunica com honestidade o que os dados dizem — nem mais, nem menos. Assumir responsabilidade sobre cada decisão metodológica, mesmo quando a execução foi delegada a uma ferramenta.
Essas competências não são técnicas. São intelectuais. E são exatamente as que a formação médica desenvolve ao longo de anos de treinamento em raciocínio diagnóstico, avaliação crítica de evidências e tomada de decisão sob incerteza.
Há uma ironia produtiva nessa convergência. As ferramentas de IA foram desenvolvidas, em sua maioria, por engenheiros e cientistas da computação — não por médicos ou pesquisadores clínicos. Mas ao democratizar o acesso à visualização de dados científicos, essas ferramentas acabaram por valorizar precisamente o tipo de raciocínio que a medicina cultiva. O médico que sabe formular uma pergunta clínica precisa, que reconhece um resultado biologicamente implausível e que assume responsabilidade sobre suas conclusões está, sem perceber, bem preparado para trabalhar com IA de forma competente.
O ecossistema de ferramentas continuará evoluindo. As plataformas descritas neste capítulo serão substituídas ou transformadas por versões mais capazes. Os modelos de linguagem que hoje geram código ggplot2 a partir de descrições em português gerarão, em breve, análises estatísticas completas (Hoerl, 2025), documentos Quarto estruturados e figuras prontas para submissão — com ainda menos fricção técnica. Essa evolução não torna o conhecimento metodológico obsoleto. Torna-o mais necessário: quanto mais poderosa a ferramenta, maior a responsabilidade de quem a dirige.
A janela que se abriu nos últimos anos é real e significativa. Aproveitá-la bem não exige que o pesquisador clínico se torne um programador. Exige que ele continue sendo o que a formação médica o preparou para ser: alguém que pensa com rigor sobre perguntas difíceis e assume responsabilidade sobre as respostas que oferece.