O boxplot, também conhecido como “caixa de bigodes” (box-and-whiskers plot), é um dos gráficos mais poderosos e informativos da estatística. Ele sintetiza a distribuição de uma variável contínua usando apenas cinco números: o mínimo, o primeiro quartil, a mediana, o terceiro quartil e o máximo. Apesar dessa simplicidade aparente, o boxplot revela padrões, variabilidade e outliers que podem passar despercebidos em um simples resumo numérico.
Neste capítulo, você aprenderá não apenas a construir um boxplot, mas a interpretar cada detalhe dessa visualização elegante. Veremos como o boxplot se compara com outros gráficos de densidade, quando usar cada um, e como ajustar seus parâmetros para revelar a história nos dados.
História: John Tukey e a Análise Exploratória de Dados
NotaUm gigante da estatística
John Wilder Tukey (1915–2000) foi um matemático e estatístico extraordinário. Durante os anos 1970, quando a maioria dos estatísticos ainda se preocupava apenas com testes de hipótese e modelos paramétricos, Tukey propôs uma abordagem revolucionária: a Análise Exploratória de Dados (EDA).
A filosofia de Tukey era simples mas radical: antes de fazer qualquer inferência estatística, você deve explorar seus dados visualmente. O boxplot foi uma das ferramentas principais dessa abordagem.
“The greatest value of a picture is when it forces us to notice what we never expected to see.” — John Tukey
Em seu livro seminal Exploratory Data Analysis(Tukey, 1977), Tukey apresentou uma versão inicial do boxplot — o chamado schematic plot —, onde os bigodes se estendiam simplesmente até os valores extremos. Foi no ano seguinte, em colaboração com Robert McGill e John Larsen (McGill; Tukey; Larsen, 1978), que o boxplot ganhou sua forma moderna: bigodes limitados a 1,5 × IQR, pontos individuais para outliers, e a possibilidade de entalhes (notches) para inferência visual sobre a mediana. Essa é a versão que usamos até hoje.
Tukey acreditava que os gráficos deveriam ser simples o suficiente para serem desenhados à mão durante uma análise preliminar (era a década de 1970, afinal), mas suficientemente informativos para guiar toda a análise seguinte. O boxplot encapsula perfeitamente essa filosofia. Hoje, quase 50 anos depois, continua sendo uma das primeiras visualizações que fazemos.
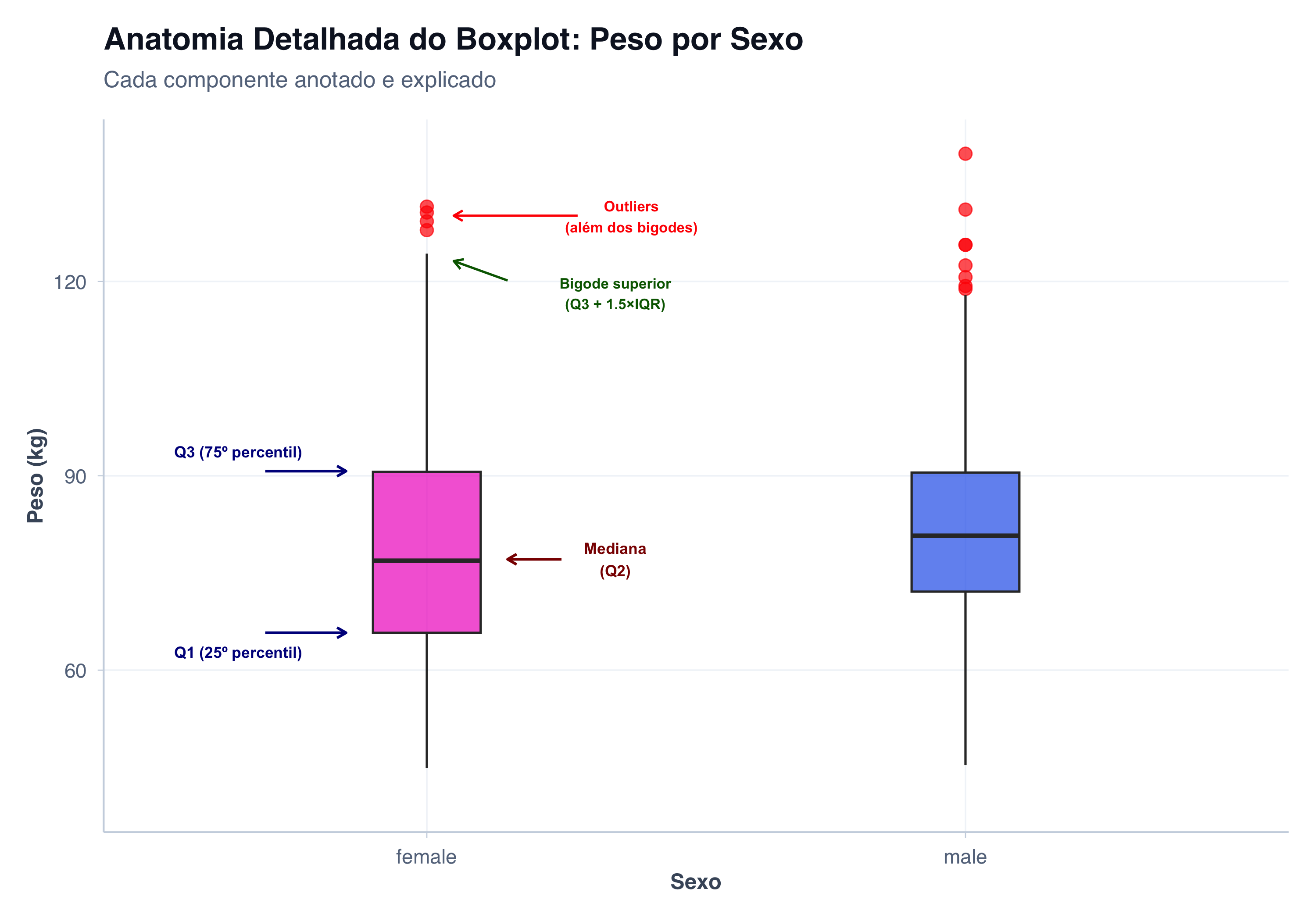
Anatomia Detalhada do Boxplot
Antes de desenhar um boxplot, é essencial entender o que cada componente representa. Vamos usar um dataset de dados médicos para ilustrar.
Os Cinco Números
O boxplot é baseado no que Tukey (Tukey, 1977) chamou de “resumo dos cinco números” (five-number summary):
Mínimo: o valor mais baixo (excluindo outliers)
Primeiro quartil (Q1): o valor que divide os 25% menores dados dos 75% maiores
Mediana (Q2): o valor central, dividindo a distribuição ao meio
Terceiro quartil (Q3): o valor que divide os 25% maiores dados dos 75% menores
Máximo: o valor mais alto (excluindo outliers)
Observe a seguir uma tabela com esses valores e o boxplot associado. Veja que a análise do gráfico é bem mais simples e rápida do que diversos números numa tabela.
Estatísticas descritivas do peso (kg) por sexo — componentes do boxplot
Sexo
Q1
Mediana (Q2)
Q3
IQR
Whisker Sup.
Whisker Inf.
Mínimo
Máximo
female
65.8
77.1
90.7
24.9
128.1
28.3
44.9
147.4
male
72.1
80.7
91.6
19.5
120.9
42.9
45.4
145.1
Ver código R
# Boxplot basep_boxplot_anotado <-ggplot(pacientes, aes(x = sexo, y = peso, fill = sexo)) +geom_boxplot(width =0.2, alpha =0.7, outlier.size =3, outlier.color ="red") +scale_fill_manual(values = paleta_sexo) +scale_y_continuous(limits =c(40, 140)) +tema_graficos() +labs(title ="Anatomia Detalhada do Boxplot: Peso por Sexo",subtitle ="Cada componente anotado e explicado",x ="Sexo",y ="Peso (kg)",fill ="Sexo" ) +theme(legend.position ="none")# Adicionar anotações para a distribuição Femininosexo_fem <- dados_estatistica %>%filter(sexo =="female")p_anotado <- p_boxplot_anotado +# Anotações para Femininoannotate("text", x =1.35, y = sexo_fem$q2, label ="Mediana\n(Q2)",size =3, color ="darkred", fontface ="bold") +annotate("segment", x =1.25, xend =1.15, y = sexo_fem$q2, yend = sexo_fem$q2,arrow =arrow(length =unit(0.2, "cm")), color ="darkred", linewidth =0.7) +annotate("text", x =0.65, y = sexo_fem$q1 -3, label ="Q1 (25º percentil)",size =3, color ="darkblue", fontface ="bold") +annotate("segment", x =0.7, xend =0.85, y = sexo_fem$q1, yend = sexo_fem$q1,arrow =arrow(length =unit(0.2, "cm")), color ="darkblue", linewidth =0.7) +annotate("text", x =0.65, y = sexo_fem$q3 +3, label ="Q3 (75º percentil)",size =3, color ="darkblue", fontface ="bold") +annotate("segment", x =0.7, xend =0.85, y = sexo_fem$q3, yend = sexo_fem$q3,arrow =arrow(length =unit(0.2, "cm")), color ="darkblue", linewidth =0.7) +annotate("text", x =1.35, y = sexo_fem$whisker_sup -10, label ="Bigode superior\n(Q3 + 1.5×IQR)",size =2.8, color ="darkgreen", fontface ="bold") +annotate("segment", x =1.15, xend =1.05, y = sexo_fem$whisker_sup-8, yend = sexo_fem$whisker_sup-5,arrow =arrow(length =unit(0.2, "cm")), color ="darkgreen", linewidth =0.6) +annotate("text", x =1.35, y = sexo_fem$whisker_inf -3, label ="Bigode inferior\n(Q1 - 1.5×IQR)",size =2.8, color ="darkgreen", fontface ="bold") +annotate("segment", x =1.25, xend =1.05, y = sexo_fem$whisker_inf, yend = sexo_fem$whisker_inf,arrow =arrow(length =unit(0.2, "cm")), color ="darkgreen", linewidth =0.6) +annotate("text", x =1.38, y =130, label ="Outliers\n(além dos bigodes)",size =2.8, color ="red", fontface ="bold") +annotate("segment", x =1.28, xend =1.05, y = sexo_fem$whisker_sup+2, yend = sexo_fem$whisker_sup+2,arrow =arrow(length =unit(0.2, "cm")), color ="red", linewidth =0.6)print(p_anotado)
O Intervalo Interquartílico (IQR)
A distância entre Q1 e Q3 é chamada de Intervalo Interquartílico (IQR):
\[\text{IQR} = Q3 - Q1\]
Este intervalo contém exatamente 50% dos dados — a metade “central” da distribuição.
Os Bigodes (Whiskers)
Os bigodes se estendem até:
Bigode superior: \(Q3 + 1.5 \times \text{IQR}\)
Bigode inferior: \(Q1 - 1.5 \times \text{IQR}\)
O fator 1,5 foi proposto originalmente por Tukey (Tukey, 1977) e refinado por McGill, Tukey e Larsen (McGill; Tukey; Larsen, 1978). Não é um valor arbitrário: para dados normais, esse limiar captura aproximadamente 99,3% das observações, fazendo com que outliers sejam genuinamente raros — cerca de 7 em cada 1.000 pontos (Frigge; Hoaglin; Iglewicz, 1989). Dados além dos bigodes são plotados como pontos individuais e considerados outliers.
DicaAtenção: nem todo software calcula igual
Um ponto sutil mas importante: diferentes softwares estatísticos implementam o boxplot de maneiras ligeiramente diferentes (Frigge; Hoaglin; Iglewicz, 1989). A principal variação está nos bigodes. Na definição original de Tukey, o bigode se estende até o valor observado mais extremo que ainda esteja dentro do limite de 1,5 × IQR — ou seja, o bigode termina num ponto real do dataset. Porém, alguns softwares (como certas versões do Excel) usam o limite teórico exato, mesmo que nenhuma observação esteja nesse ponto. O R (e o ggplot2) segue a definição de Tukey. Se você comparar boxplots gerados em diferentes ferramentas e notar pequenas discrepâncias nos bigodes, essa é a explicação.
Interpretando a Caixa
A caixa (box) é o elemento central do boxplot:
A altura da caixa é o IQR, contendo exatamente 50% dos dados
A linha dentro da caixa é a mediana
Se a mediana está próxima do topo da caixa (perto de Q3), o intervalo Q1–mediana é grande e o intervalo mediana–Q3 é pequeno — há mais dispersão nos valores baixos, indicando assimetria negativa (cauda à esquerda)
Se a mediana está próxima do fundo (perto de Q1), o intervalo mediana–Q3 é grande — há mais dispersão nos valores altos, indicando assimetria positiva (cauda à direita)
Se a mediana está aproximadamente no centro da caixa, a distribuição é aproximadamente simétrica
Para uma leitura mais completa, observe também os bigodes: se o bigode superior é muito mais longo que o inferior, isso reforça a assimetria positiva, e vice-versa. Quando a caixa sugere simetria mas os bigodes são muito desiguais, a assimetria pode estar concentrada nas caudas da distribuição.
AvisoHeurística visual, não prova matemática
Essa regra de leitura da posição da mediana é uma heurística útil, não uma demonstração formal de assimetria. Duas distribuições com formas internas bastante diferentes podem produzir boxplots visualmente semelhantes — lembre-se de que o boxplot resume toda a distribuição em apenas cinco números. Em análises mais rigorosas, especialmente em pesquisa clínica ou epidemiológica, é prudente complementar o boxplot com um histograma ou gráfico de densidade (como veremos adiante neste capítulo) e, se necessário, calcular uma medida numérica de assimetria (skewness).
No nosso exemplo, note que:
Feminino: a mediana está próxima ao centro da caixa (posição relativa ~0,46), mas o bigode superior é mais longo e há outliers acima — a distribuição tem assimetria positiva leve (skewness ≈ +0,68), com cauda puxada para valores altos de peso
Masculino: a mediana também está levemente abaixo do centro da caixa (~0,42), com assimetria positiva um pouco mais acentuada (skewness ≈ +0,88) — os bigodes e outliers superiores confirmam essa cauda à direita
Variações e Extensões do Boxplot
O boxplot clássico de Tukey é apenas o ponto de partida. Ao longo das décadas, pesquisadores propuseram diversas variações que enriquecem a visualização, cada uma resolvendo uma limitação específica do boxplot original. Vamos conhecer as principais antes de mergulhar na construção prática.
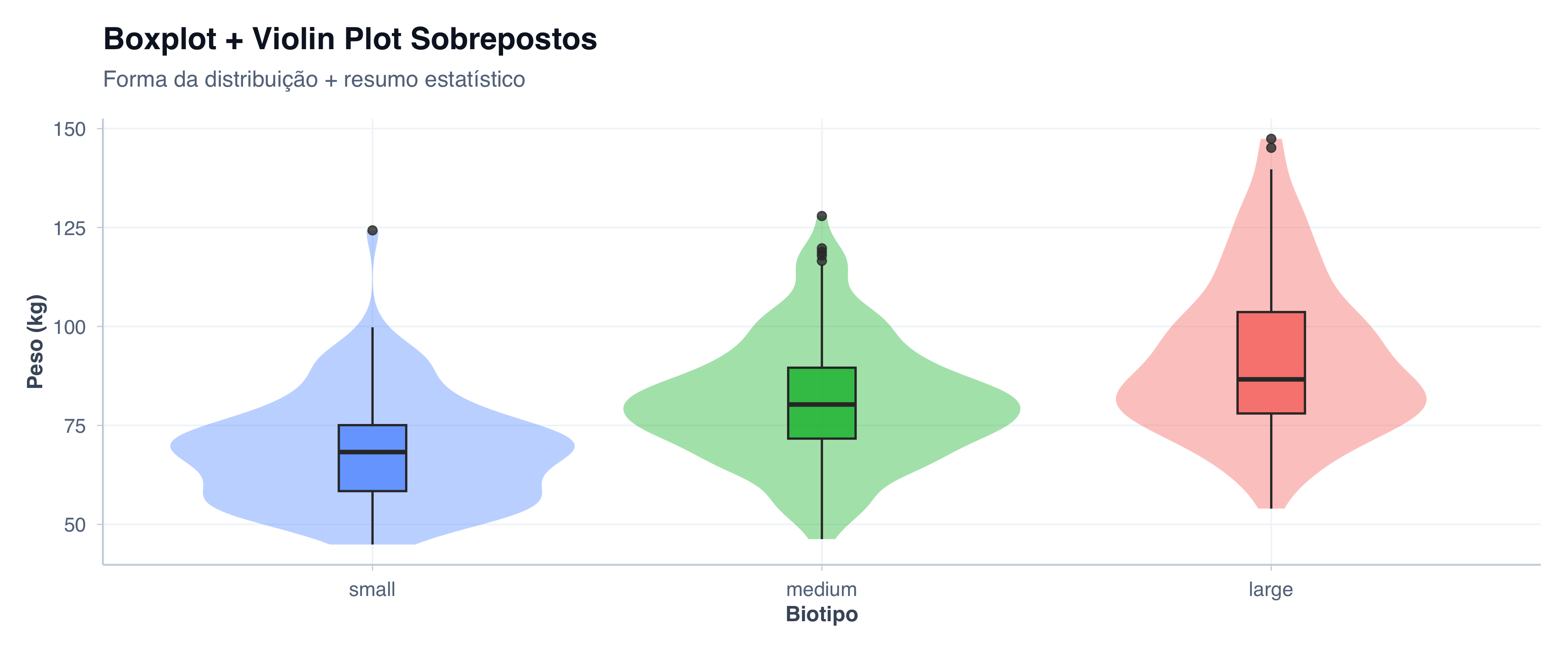
Violin Plot
O violin plot, proposto por Hintze e Nelson (Hintze; Nelson, 1998), combina a ideia do boxplot com uma estimativa de densidade kernel espelhada. O resultado é uma forma que lembra um violino: mais larga onde há mais dados e mais estreita onde há poucos.
A grande vantagem do violin plot é mostrar a forma completa da distribuição — algo que o boxplot, por natureza, esconde. Distribuições bimodais, lacunas nos dados e assimetrias complexas ficam imediatamente visíveis.
Na prática, o violin plot raramente aparece sozinho — quase sempre é sobreposto com um boxplot estreito, pois o violin não mostra mediana nem quartis por conta própria. Essa combinação une o melhor dos dois mundos: a forma da distribuição (violin) com os marcos estatísticos (boxplot).
AvisoCuidado com amostras pequenas
A estimativa de densidade kernel precisa de dados suficientes para ser confiável. Com n < 20 ou 30, o violin pode sugerir uma forma suave e contínua que não corresponde à realidade dos dados. Nesses casos, prefira o boxplot com jitter (pontos individuais), que mostra honestamente o que há nos dados sem interpolar.
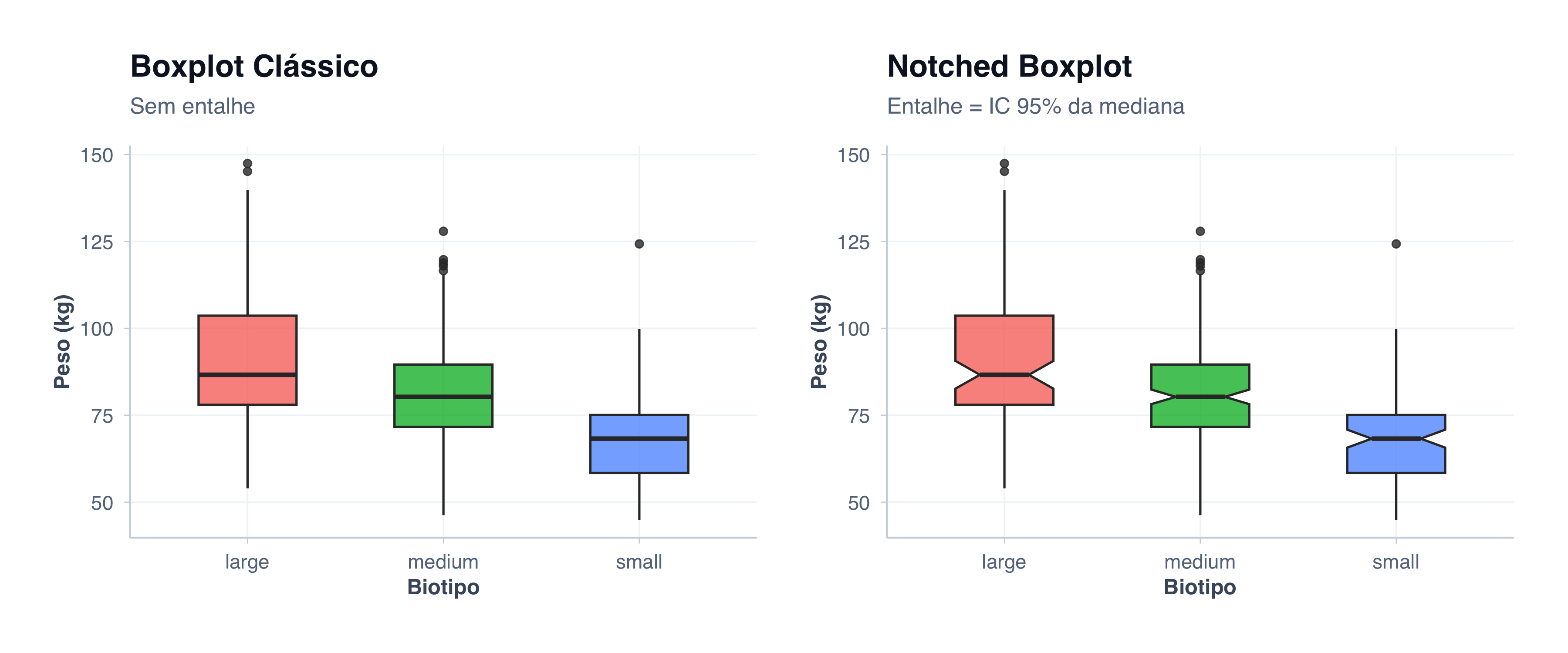
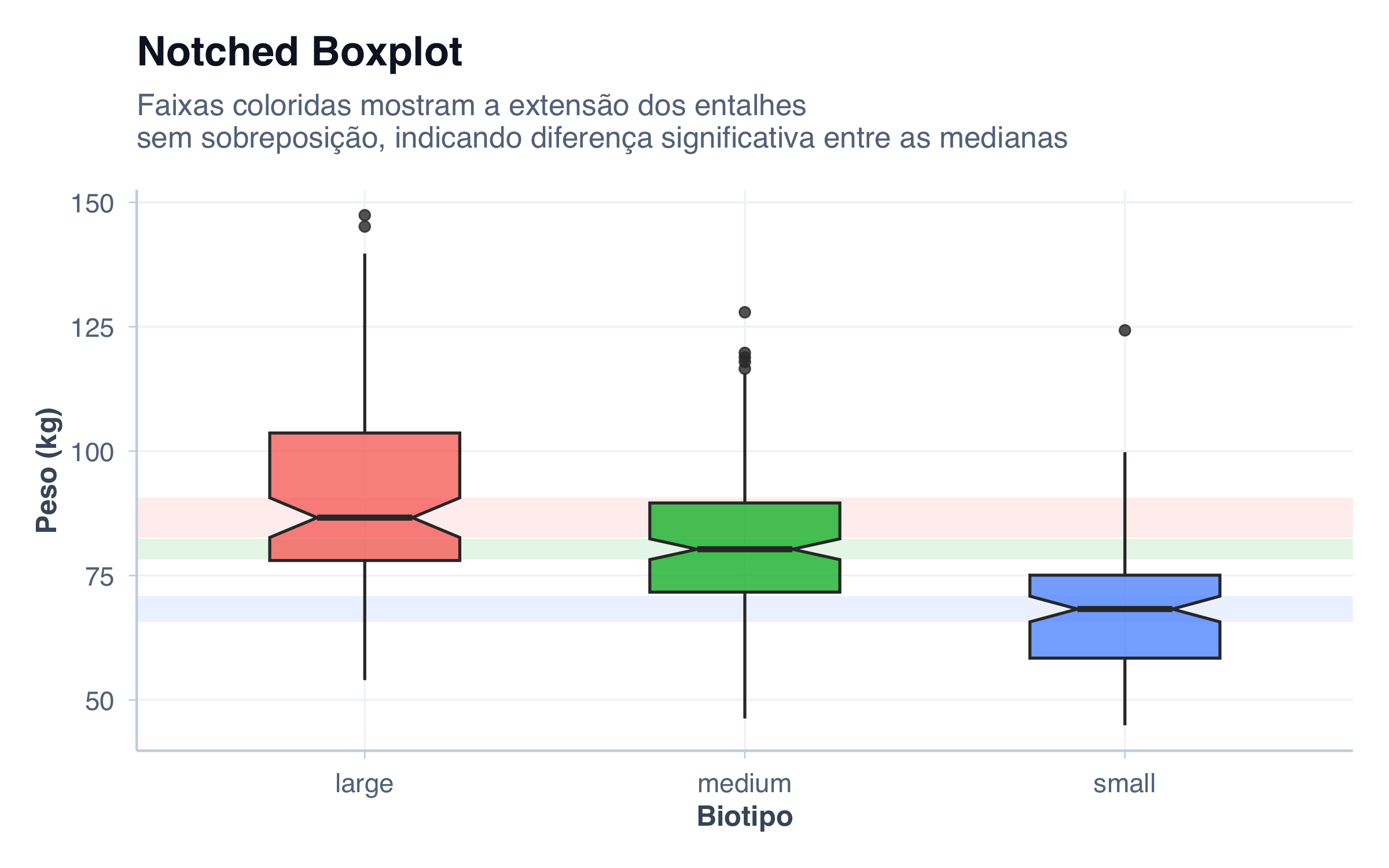
Notched Boxplot (Boxplot com Entalhe)
O boxplot com entalhe adiciona um estreitamento na região da mediana, representando um intervalo de confiança aproximado (~95%) para sua localização. Foi proposto por McGill, Tukey e Larsen (McGill; Tukey; Larsen, 1978) e tem uma regra de leitura simples: se os entalhes de dois boxplots não se sobrepõem, há evidência visual de que as medianas diferem significativamente.
No gráfico abaixo adicionei um retangulo demarcando os limites do entalhe, para facilitar a análise da sopreposição dos intervalos de confiança.
Ver código R
# Calcular limites dos entalhes por biotiponotch_data <- pacientes %>%group_by(biotipo) %>%summarise(mediana =median(peso),iqr =IQR(peso),n =n(),notch_lower = mediana -1.58* iqr /sqrt(n),notch_upper = mediana +1.58* iqr /sqrt(n),.groups ="drop" )ggplot(pacientes, aes(x =fct_relevel(biotipo, "Small", "Medium", "Large"),y = peso, fill = biotipo)) +# Faixas horizontais mostrando a extensão dos entalhesgeom_rect(data = notch_data,aes(xmin =-Inf, xmax =Inf,ymin = notch_lower, ymax = notch_upper,fill = biotipo),alpha =0.12, inherit.aes =FALSE) +# Boxplot por cimageom_boxplot(alpha =0.8, width =0.5, notch =TRUE, notchwidth =0.5) +tema_graficos() +labs(title ="Notched Boxplot",subtitle ="Faixas coloridas mostram a extensão dos entalhes\nsem sobreposição, indicando diferença significativa entre as medianas",x ="Biotipo",y ="Peso (kg)" ) +theme(legend.position ="none")
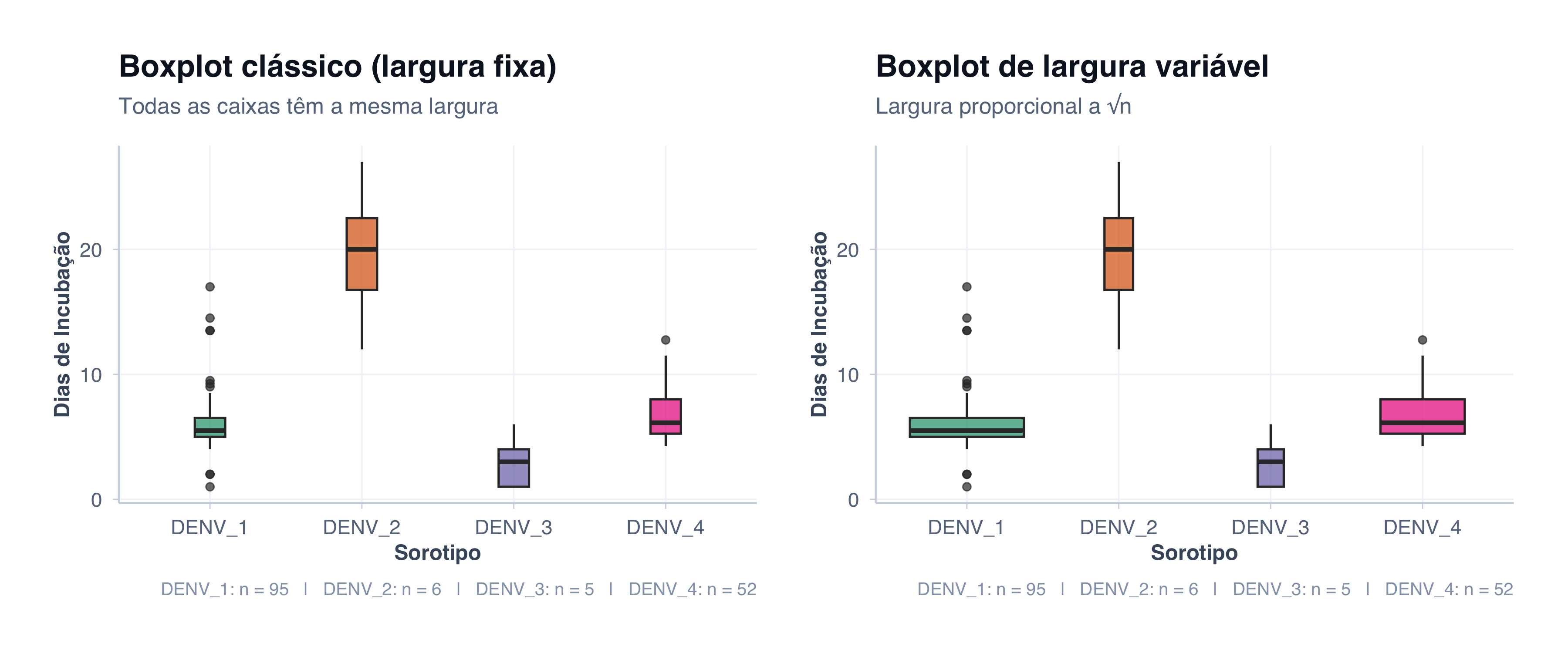
Variable-Width Boxplot (Boxplot de Largura Variável)
Uma limitação frequentemente esquecida do boxplot é que ele não mostra o tamanho amostral. Um grupo com 5 observações e outro com 500 produzem caixas visualmente idênticas, embora a confiança nas estimativas seja radicalmente diferente (Benjamini, 1988).
O boxplot de largura variável resolve isso tornando a largura de cada caixa proporcional a \(\sqrt{n}\). Grupos maiores ficam mais largos; grupos pequenos ficam estreitos — uma dica visual imediata sobre a confiabilidade de cada estimativa. Essa variação também foi proposta por McGill, Tukey e Larsen (McGill; Tukey; Larsen, 1978).
Veja como isso funciona com nossos dados de dengue, onde os tamanhos amostrais são muito desiguais:
Ver código R
# Carregar dados de denguedengue_var <-read_csv("data/dengue.csv", show_col_types =FALSE) %>%filter(!is.na(sorotipo))# Caption com n por sorotipocaption_n <- dengue_var %>%count(sorotipo) %>%mutate(label =paste0(sorotipo, ": n = ", n)) %>%pull(label) %>%paste(collapse =" | ")p1 <-ggplot(dengue_var, aes(x = sorotipo, y = dias, fill = sorotipo)) +geom_boxplot(alpha =0.7, width =0.2) +scale_fill_manual(values =c("DENV_1"="#1B9E77", "DENV_2"="#D95F02","DENV_3"="#7570B3", "DENV_4"="#E7298A")) +tema_graficos() +labs(title ="Boxplot clássico (largura fixa)",subtitle ="Todas as caixas têm a mesma largura",caption = caption_n,x ="Sorotipo",y ="Dias de Incubação" ) +theme(legend.position ="none")p2 <-ggplot(dengue_var, aes(x = sorotipo, y = dias, fill = sorotipo)) +geom_boxplot(alpha =0.7, varwidth =TRUE) +scale_fill_manual(values =c("DENV_1"="#1B9E77", "DENV_2"="#D95F02","DENV_3"="#7570B3", "DENV_4"="#E7298A")) +tema_graficos() +labs(title ="Boxplot de largura variável",subtitle ="Largura proporcional a √n",caption = caption_n,x ="Sorotipo",y ="Dias de Incubação" ) +theme(legend.position ="none")p1 | p2
No gráfico da direita, fica imediatamente visível que DENV_1 (n ≈ 95) domina o dataset, enquanto DENV_2 e DENV_3 (n = 5–6) são apenas amostras minúsculas. É uma informação crucial que o boxplot padrão simplesmente omite.
Para datasets muito grandes (milhares ou milhões de observações), Hofmann e colaboradores (2017) propuseram o letter-value plot, também chamado de boxenplot. Em vez de mostrar apenas Q1, mediana e Q3, ele exibe quantis progressivamente mais extremos — oitavos, dezesseis-avos, trinta-e-dois-avos — usando caixas cada vez mais estreitas. Isso revela detalhes nas caudas da distribuição que o boxplot clássico resume em apenas dois bigodes.
No R, está disponível via o pacote lvplot com a função geom_lv(). É uma ferramenta poderosa para big data, mas para os tamanhos amostrais típicos em pesquisa clínica (dezenas a centenas de observações), o boxplot clássico costuma ser suficiente.
Outras combinações
Além dessas variações do boxplot propriamente dito, existem combinações que sobrepõem o boxplot com outras camadas visuais — como o beeswarm plot (pontos organizados sem sobreposição) e o raincloud plot (violin + boxplot + jitter).
Visualizando os Dados Individuais no Boxplot (Jitter)
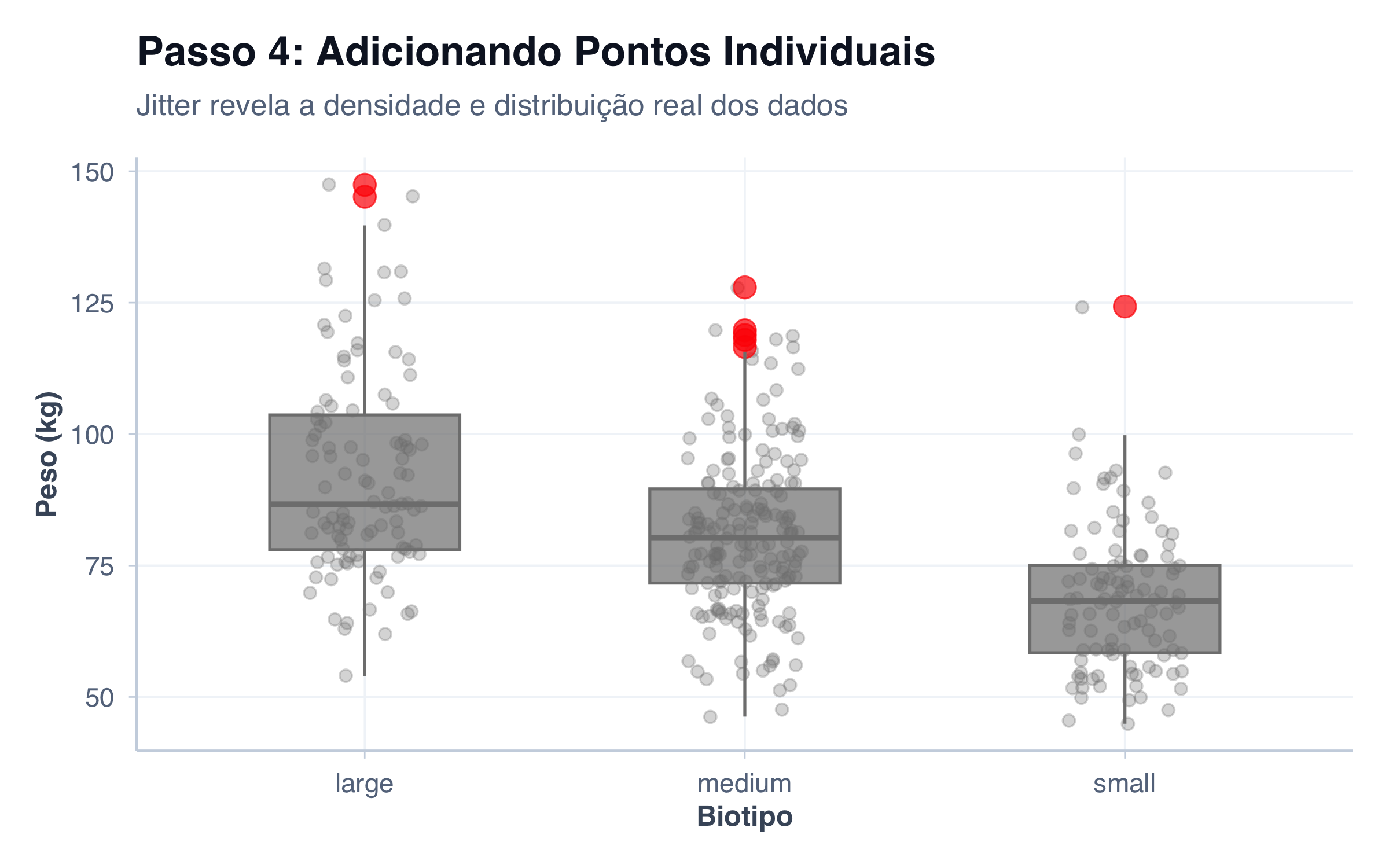
Observe no grafico abaixo que, além da caixa e dos bigodes, aparecem pontos espalhados ao redor de cada boxplot. Cada ponto representa uma observação real do dataset — ou seja, o peso de um paciente. Esses pontos estão ligeiramente deslocados para os lados (de forma aleatória) para que não fiquem empilhados uns sobre os outros e possam ser vistos individualmente. Repare onde os pontos se concentram: nas regiões mais densas da distribuição, há uma “nuvem” mais compacta de pontos; nas extremidades, os pontos ficam mais espaçados. Isso dá ao leitor algo que o boxplot sozinho não oferece — a quantidade real de dados em cada região. Um boxplot com 10 observações e outro com 500 têm a mesma aparência; mas ao ver os pontos, a diferença fica imediata.
Ver código R
ggplot(pacientes, aes(x = biotipo, y = peso, fill = biotipo, color = biotipo)) +geom_jitter(width =0.15, alpha =0.3, size =2) +geom_boxplot(width =0.5,alpha =0.7,outlier.size =4,outlier.color ="red" ) +scale_fill_manual(values =c("Small"="#8DD3C7", "Medium"="#FFFFB3", "Large"="#BEBADA")) +scale_color_manual(values =c("Small"="#8DD3C7", "Medium"="#FFFFB3", "Large"="#BEBADA")) +tema_graficos() +labs(title ="Passo 4: Adicionando Pontos Individuais",subtitle ="Jitter revela a densidade e distribuição real dos dados",x ="Biotipo",y ="Peso (kg)",fill ="Biotipo" ) +theme(legend.position ="bottom")
No R, essa técnica é chamada de jitter (do inglês, “tremor”) e consiste em adicionar um pequeno deslocamento horizontal aleatório a cada ponto antes de plotá-lo. Sem esse deslocamento, todos os pontos de um mesmo grupo cairiam exatamente na mesma posição do eixo X, empilhados uns sobre os outros — e veríamos apenas um único ponto onde na verdade há dezenas.
No ggplot2, basta adicionar uma camada geom_jitter() ao gráfico. O parâmetro width controla a amplitude do espalhamento — valores menores (como 0,05) mantêm os pontos bem agrupados junto ao boxplot, enquanto valores maiores (como 0,3) os espalham mais. O ideal é encontrar um equilíbrio: espalhar o suficiente para evitar sobreposição, mas não tanto que os pontos invadam o espaço de grupos vizinhos.
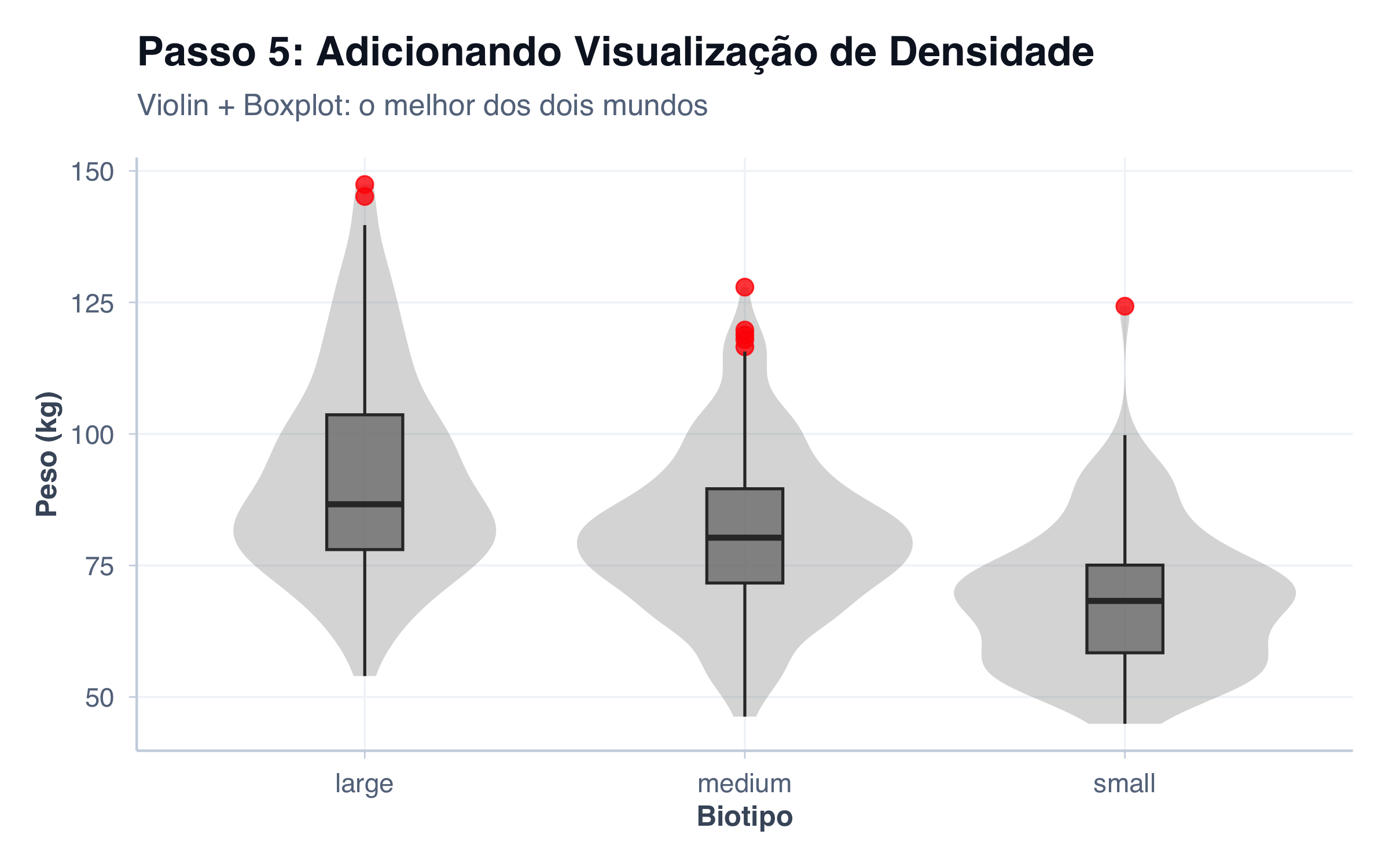
Sobrepondo um Violin Plot
Ver código R
ggplot(pacientes, aes(x = biotipo, y = peso, fill = biotipo)) +geom_violin(alpha =0.3, color =NA) +geom_boxplot(width =0.2,alpha =0.8,outlier.size =3,outlier.color ="red" ) +scale_fill_manual(values =c("Small"="#8DD3C7", "Medium"="#FFFFB3", "Large"="#BEBADA")) +tema_graficos() +labs(title ="Passo 5: Adicionando Visualização de Densidade",subtitle ="Violin + Boxplot: o melhor dos dois mundos",x ="Biotipo",y ="Peso (kg)",fill ="Biotipo" ) +theme(legend.position ="bottom")
Agora temos a forma da distribuição (violin) com o resumo dos cinco números (boxplot).
Múltiplas Facetas
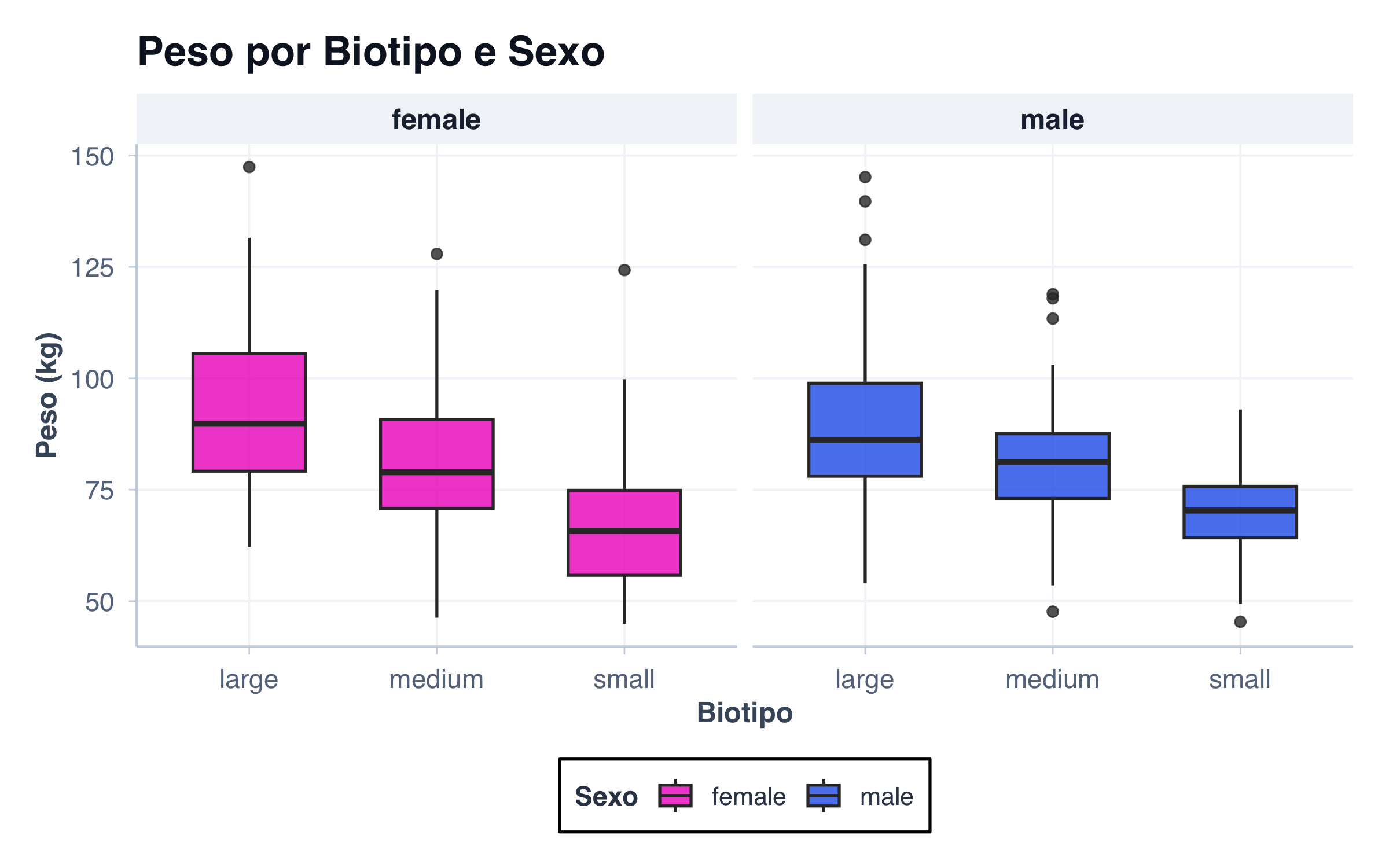
Quando queremos explorar como uma variável contínua se comporta em função de duas variáveis categóricas simultaneamente, agrupar todos os boxplots em um único painel pode gerar um gráfico poluído e difícil de ler. Uma alternativa elegante é usar facetas — painéis separados que dividem o gráfico por uma das variáveis, permitindo que a outra seja comparada dentro de cada painel. No exemplo a seguir, queremos entender como o peso varia por biotipo e por sexo. Em vez de colocar seis boxplots lado a lado (três biótipos × dois sexos), separamos os sexos em painéis distintos. Dentro de cada painel, comparamos os biótipos. O resultado é uma leitura muito mais limpa: primeiro você compara biótipos dentro de cada sexo, e depois compara os painéis entre si para ver se o padrão se repete.
Ver código R
ggplot(pacientes, aes(x = biotipo, y = peso, fill = sexo)) +geom_boxplot(alpha =0.8, width =0.6) +facet_wrap(~sexo) +scale_fill_manual(values = paleta_sexo) +tema_graficos() +labs(title ="Peso por Biotipo e Sexo",x ="Biotipo",y ="Peso (kg)",fill ="Sexo" ) +theme(legend.position ="bottom")
Boxplot Horizontal
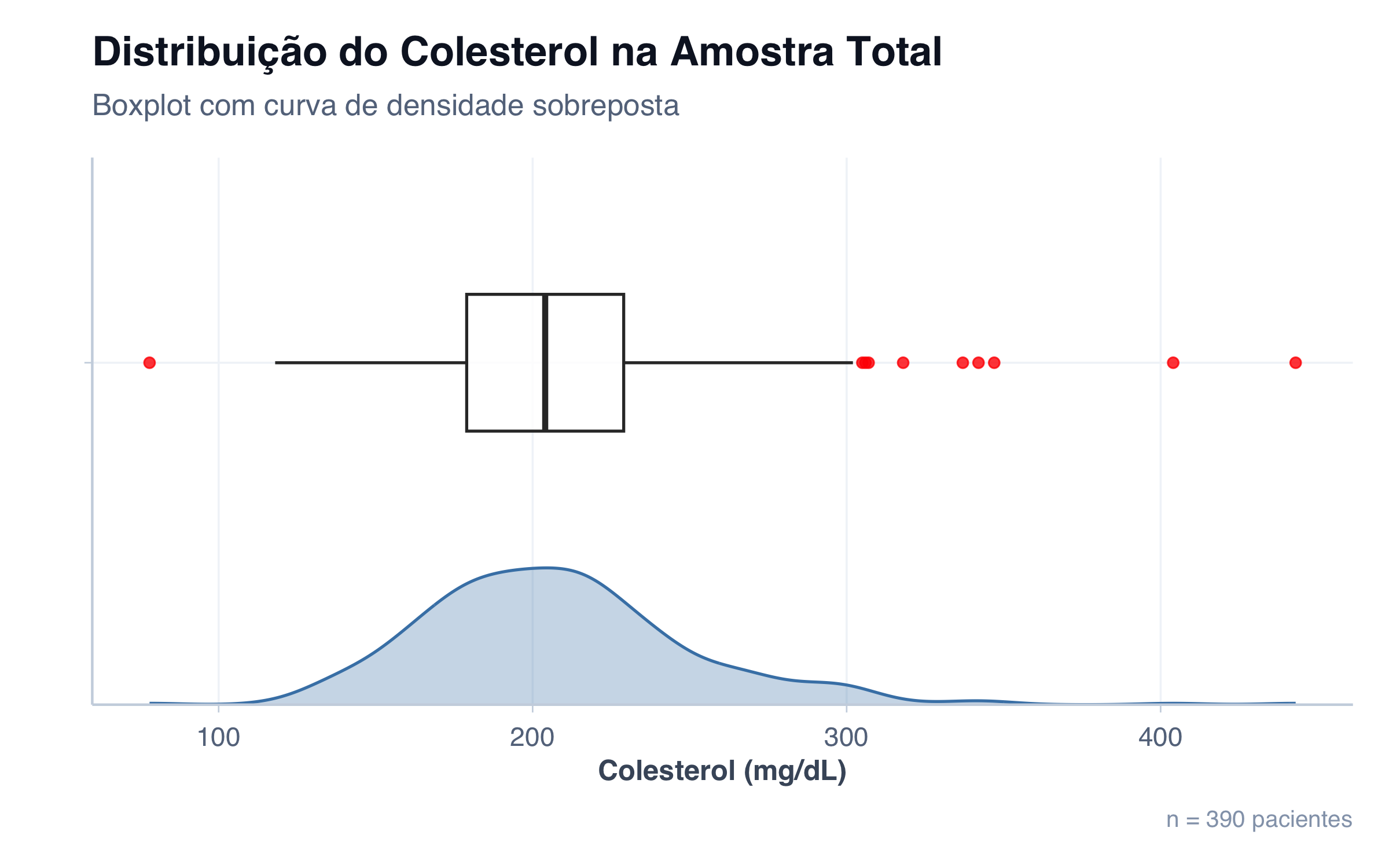
O boxplot pode ser orientado horizontalmente, com os valores da variável no eixo X e as categorias no eixo Y. Essa orientação é particularmente útil quando os nomes das categorias são longos, pois evita rótulos inclinados ou cortados. Mas há uma vantagem menos óbvia: na orientação horizontal, o boxplot compartilha o mesmo eixo que um gráfico de densidade. Como a curva de densidade é naturalmente plotada na horizontal (valores no eixo X, frequência no eixo Y), empilhar os dois verticalmente permite uma comparação direta — cada região do boxplot corresponde exatamente à mesma posição na curva de densidade. Essa combinação oferece uma das formas mais completas de examinar uma distribuição: o boxplot fornece os marcos estatísticos (mediana, quartis, outliers) e a densidade revela a forma completa, incluindo picos e assimetrias que a caixa sozinha não mostra.
Ver código R
# Total de pacientes para o captionn_total <-nrow(pacientes)ggplot(pacientes, aes(y ="", x = colesterol)) +geom_density(aes(x = colesterol, y =after_stat(scaled) *0.4),fill ="steelblue", alpha =0.3, color ="steelblue") +geom_boxplot(alpha =0.8, width =0.4, outlier.color ="red") +labs(title ="Distribuição do Colesterol na Amostra Total",subtitle ="Boxplot com curva de densidade sobreposta",caption =paste0("n = ", n_total, " pacientes"),x ="Colesterol (mg/dL)",y ="" ) +tema_graficos() +theme(legend.position ="none")
Densidade vs Boxplot: Qual é Melhor?
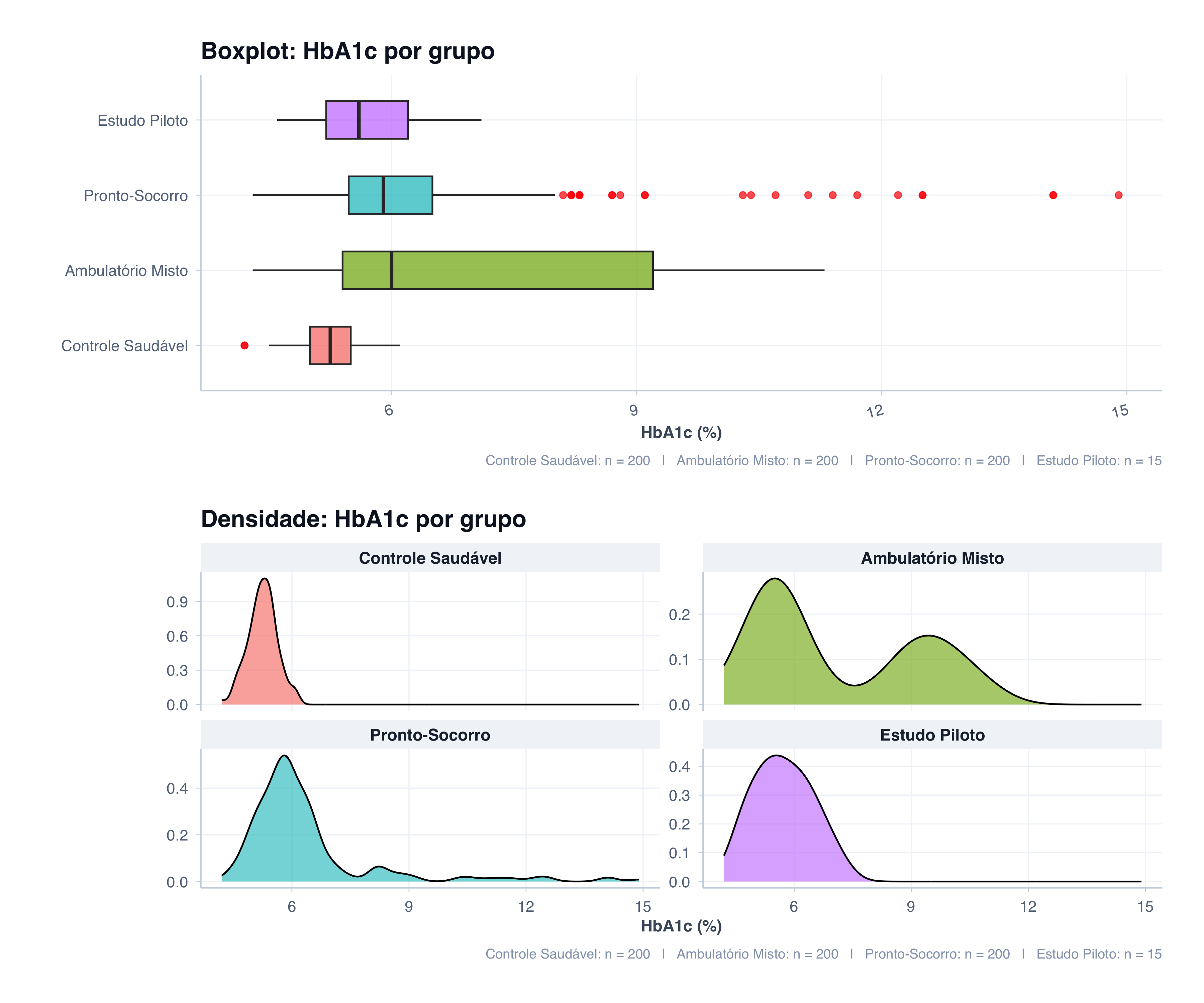
Para entender quando cada visualização é mais útil, criamos um dataset simulado com quatro cenários clínicos de hemoglobina glicada (HbA1c), cada um projetado para revelar uma situação diferente. Compare o boxplot (acima) com as curvas de densidade (abaixo) e observe o que cada um consegue — e não consegue — mostrar.
Controle Saudável (n=200): Este é o cenário mais simples. A distribuição é unimodal e aproximadamente simétrica, centrada em torno de 5,2%. Tanto o boxplot quanto a densidade contam a mesma história — uma caixa compacta e uma curva em forma de sino. Quando a distribuição é bem comportada, as duas visualizações concordam.
Ambulatório Misto (n=200): Aqui está a armadilha. Olhando apenas o boxplot, vemos uma caixa larga com grande variabilidade — a impressão é de um grupo com dados mais dispersos. Mas a curva de densidade revela a verdade: são dois subgrupos distintos misturados — pacientes com HbA1c controlada (~5,5%) e pacientes descompensados (~9,5%). Essa bimodalidade é completamente invisível no boxplot, que resume tudo em uma única caixa. Em um contexto clínico real, essa distinção entre aderentes e não-aderentes ao tratamento seria crucial — e o boxplot sozinho a esconderia.
Pronto-Socorro (n=200): Neste cenário, o boxplot brilha. A maioria dos pacientes tem valores normais (~5,8%), mas há casos de emergência hiperglicêmica com HbA1c acima de 10–12%. O boxplot identifica esses outliers automaticamente como pontos vermelhos, sinalizando que merecem atenção clínica. A curva de densidade, por sua vez, suaviza esses extremos — a cauda direita aparece como um afinamento gradual, sem o mesmo impacto visual. Para detectar valores atípicos individuais, o boxplot é superior.
Estudo Piloto (n=15): Com apenas 15 observações, o boxplot produz um resumo honesto, embora limitado — mostra os quartis e a mediana com os dados que tem. Já a curva de densidade cria uma ilusão perigosa: uma curva suave e contínua que sugere uma distribuição bem definida, quando na realidade temos pouquíssimos pontos. A densidade kernel precisa de dados suficientes para ser confiável; com n pequeno, ela inventa mais do que revela.
Ver código R
# Ler dados simulados de HbA1chba1c <-read_csv("data/hba1c.csv", show_col_types =FALSE)# Ordenar os grupos na sequência didáticahba1c <- hba1c %>%mutate(grupo =fct_relevel(grupo, "Controle Saudável", "Ambulatório Misto", "Pronto-Socorro", "Estudo Piloto"))# Caption com n por grupocaption_n <- hba1c %>%count(grupo) %>%mutate(label =paste0(grupo, ": n = ", n)) %>%pull(label) %>%paste(collapse =" | ")# Boxplotp1 <-ggplot(hba1c, aes(y = grupo, x = hba1c, fill = grupo)) +geom_boxplot(alpha =0.7, width =0.5, outlier.color ="red", outlier.size =2) +tema_graficos() +labs(title ="Boxplot: HbA1c por grupo",caption = caption_n,y ="",x ="HbA1c (%)" ) +theme(legend.position ="none",axis.text.x =element_text(angle =15, hjust =1))# Densidadep2 <-ggplot(hba1c, aes(x = hba1c, fill = grupo)) +geom_density(alpha =0.6) +facet_wrap(~grupo, scales ="free_y") +tema_graficos() +labs(title ="Densidade: HbA1c por grupo",caption = caption_n,x ="HbA1c (%)",y ="" ) +theme(legend.position ="none")p1 / p2
Quando Usar Cada Um?
Situação
Boxplot
Densidade
Comparar múltiplos grupos lado a lado
✓ Excelente
✗ Difícil com facetas
Identificar outliers
✓ Automático
✗ Subjetivo
Ver distribuição multimodal
✗ Não mostra picos
✓ Excelente
Dados com n pequeno
✓ Robusto
✗ Estimativa ruim
Dados discretos
✓ OK
✗ Problemático
Comparar uma variável entre 2-5 grupos
✓ Excelente
✓ Bom
Entender forma completa da distribuição
✗ Resumido
✓ Completo
Como observou Benjamini (Benjamini, 1988), o boxplot tem limitações importantes: ele pode mascarar distribuições bimodais (como vimos no exemplo do colesterol), não revela lacunas (gaps) nos dados, e sua interpretação depende do tamanho amostral — um boxplot com n = 5 e outro com n = 500 parecem visualmente idênticos, embora a confiança nas estimativas seja radicalmente diferente. Por isso, combinar o boxplot com outras visualizações é uma prática recomendada.
Conclusão: Use boxplot para comparação entre grupos e densidade para entender a forma de uma distribuição. Idealmente, use ambos!
Usando Boxplot com Variáveis Contínuas no Eixo X
Às vezes queremos explorar um boxplot onde o eixo X é uma variável contínua. Convertemos em grupos:
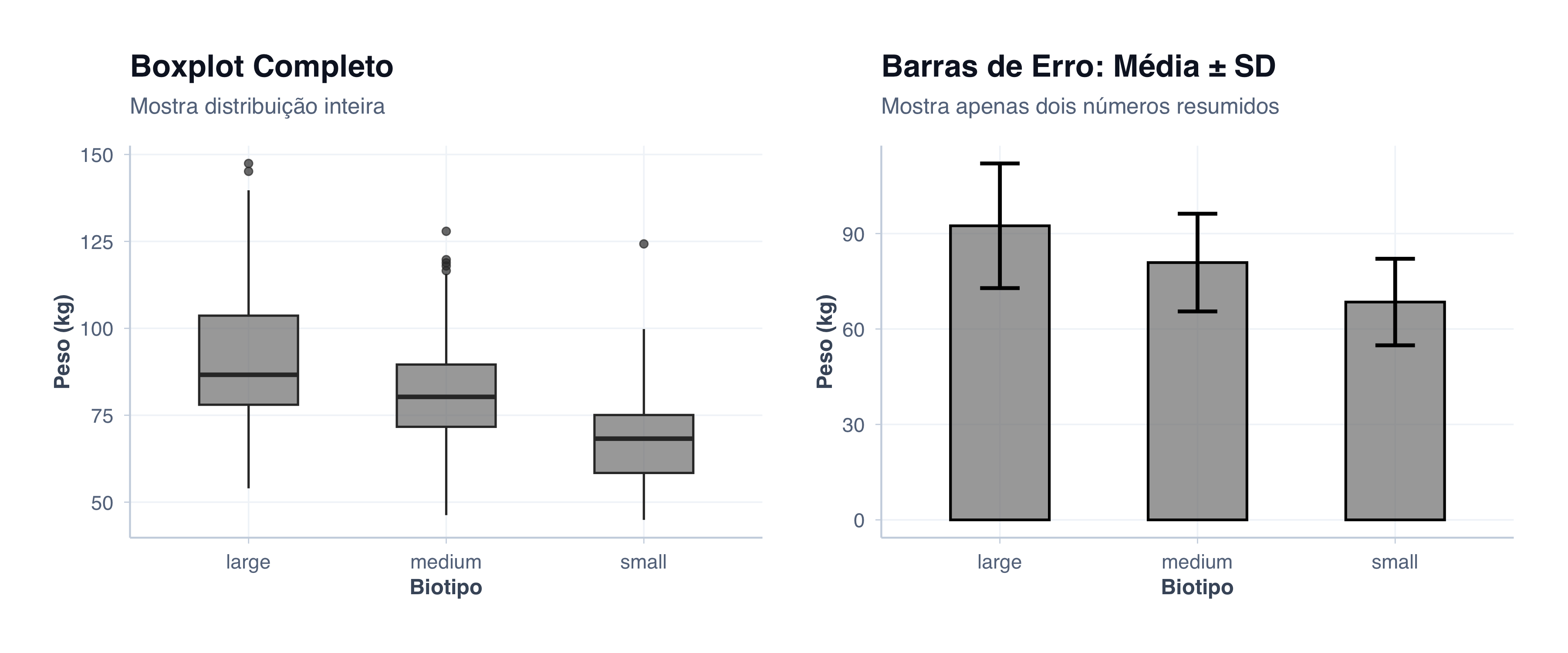
Alternativa: Plotando Apenas Médias com Barras de Erro
Em publicações biomédicas, é ainda muito comum ver dados resumidos apenas como média ± desvio padrão em gráficos de barras. Simpson e colaboradores (Simpson Jr.; Johnson; Amara, 1988) já argumentavam nos anos 1980 que o boxplot deveria ser preferido em artigos científicos, pois transmite muito mais informação no mesmo espaço. Vamos comparar:
Boxplot (esquerda): Mostra Q1, mediana, Q3, min, max, outliers. Muito informativo!
Barras de erro (direita): Mostra apenas média e desvio padrão. Muito mais simples, mas perde informação!
Conclusão: A menos que espaço seja muito limitado, o boxplot é superior. As barras de erro ocultam a forma da distribuição, a presença de outliers e a assimetria — informações cruciais para a interpretação clínica dos dados (Simpson Jr.; Johnson; Amara, 1988).
Dicas Práticas para Boxplots Efetivos
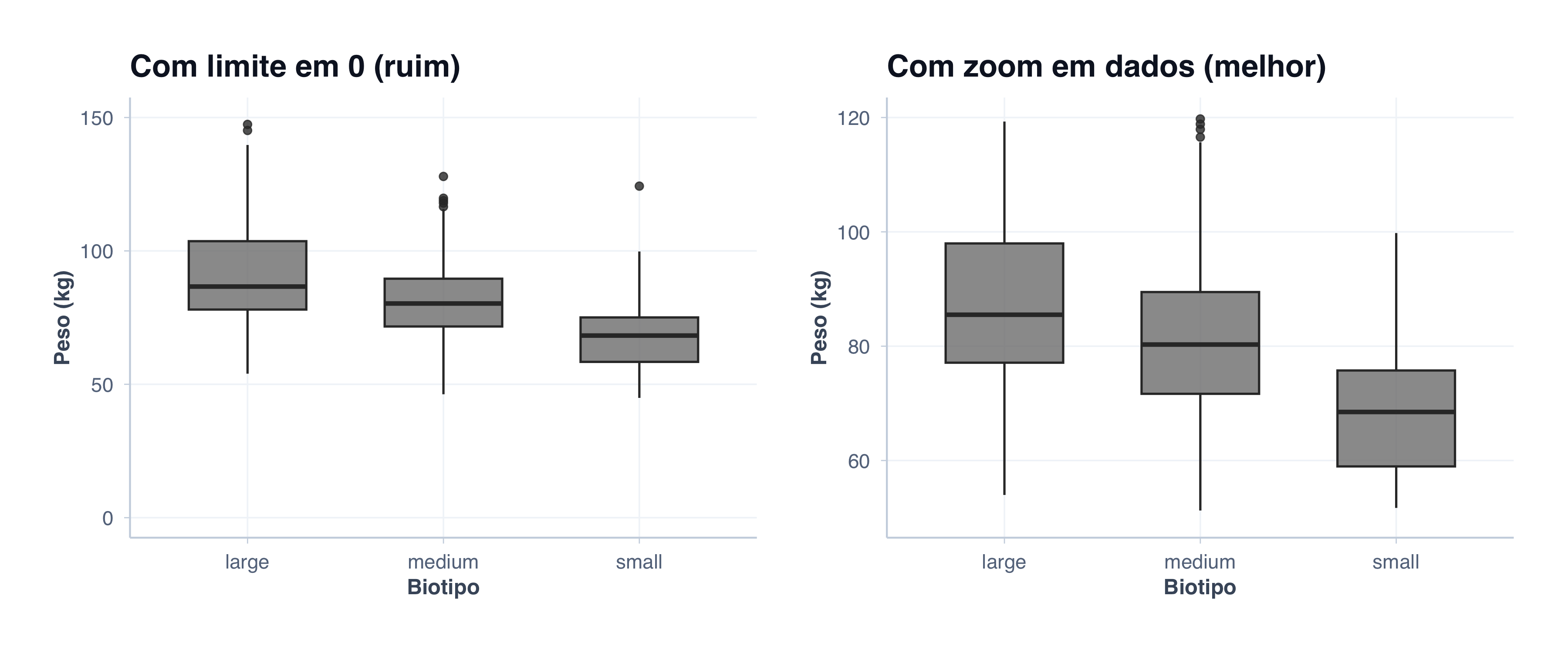
1. Ajustando os Limites do Eixo Y
Nem sempre começar em zero é melhor:
Ver código R
p1 <-ggplot(pacientes, aes(x = biotipo, y = peso, fill = biotipo)) +geom_boxplot(alpha =0.8, width =0.6) +scale_fill_manual(values =c("Small"="#8DD3C7", "Medium"="#FFFFB3", "Large"="#BEBADA")) +scale_y_continuous(limits =c(0, 150)) +# Começa em 0tema_graficos() +labs(title ="Com limite em 0 (ruim)",x ="Biotipo",y ="Peso (kg)" ) +theme(legend.position ="none")p2 <-ggplot(pacientes, aes(x = biotipo, y = peso, fill = biotipo)) +geom_boxplot(alpha =0.8, width =0.6) +scale_fill_manual(values =c("Small"="#8DD3C7", "Medium"="#FFFFB3", "Large"="#BEBADA")) +scale_y_continuous(limits =c(50, 120)) +# Zoom em dadostema_graficos() +labs(title ="Com zoom em dados (melhor)",x ="Biotipo",y ="Peso (kg)" ) +theme(legend.position ="none")p1 | p2
À direita, vemos muito mais claramente as diferenças! Para variáveis que não têm zero natural (peso, colesterol), é melhor não forçar o zero.
Resumo dos cinco números + estatísticas descritivas do peso (kg) por biotipo
biotipo
N
Mínimo
Q1 (25%)
Mediana (Q2)
Q3 (75%)
Máximo
IQR
Média
DP
large
103
53.98
78.02
86.64
103.65
147.42
25.63
92.44
19.59
medium
183
46.27
71.67
80.29
89.58
127.91
17.92
80.88
15.35
small
104
44.91
58.40
68.27
75.07
124.28
16.67
68.47
13.60
Aprofundamento: Variações Avançadas
Beeswarm Plot + Boxplot
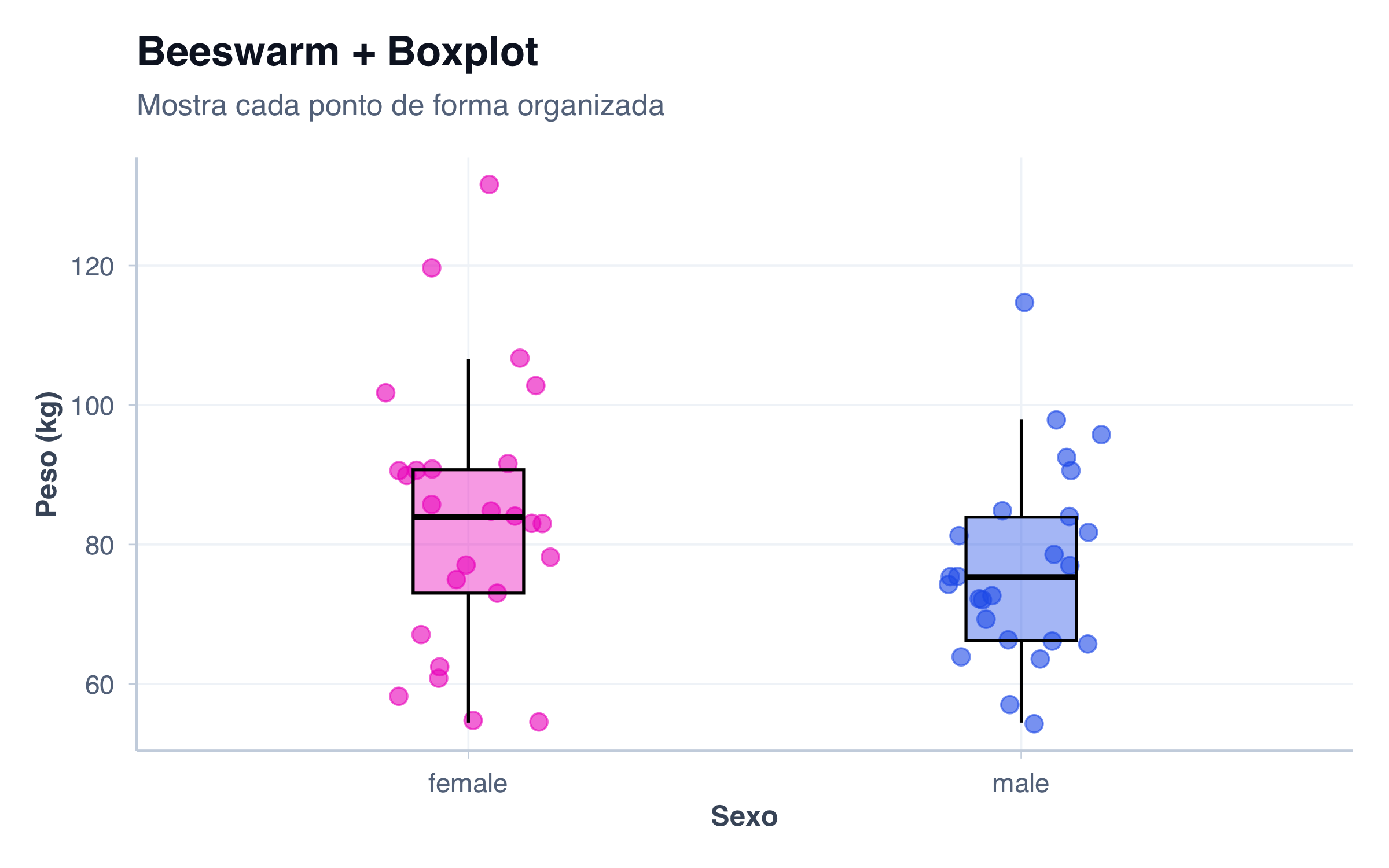
Para dados com tamanho amostral pequeno a médio, mostrar cada ponto com jitter pode ser melhor que densidade:
Ver código R
pacientes_pequeno <- pacientes %>%slice_sample(n =50)ggplot(pacientes_pequeno, aes(x = sexo, y = peso, fill = sexo, color = sexo)) +geom_jitter(size =3, alpha =0.6, width =0.15) +geom_boxplot(alpha =0.4, width =0.2, color ="black", outlier.shape =NA) +scale_fill_manual(values = paleta_sexo) +scale_color_manual(values = paleta_sexo) +tema_graficos() +labs(title ="Beeswarm + Boxplot",subtitle ="Mostra cada ponto de forma organizada",x ="Sexo",y ="Peso (kg)" ) +theme(legend.position ="none")
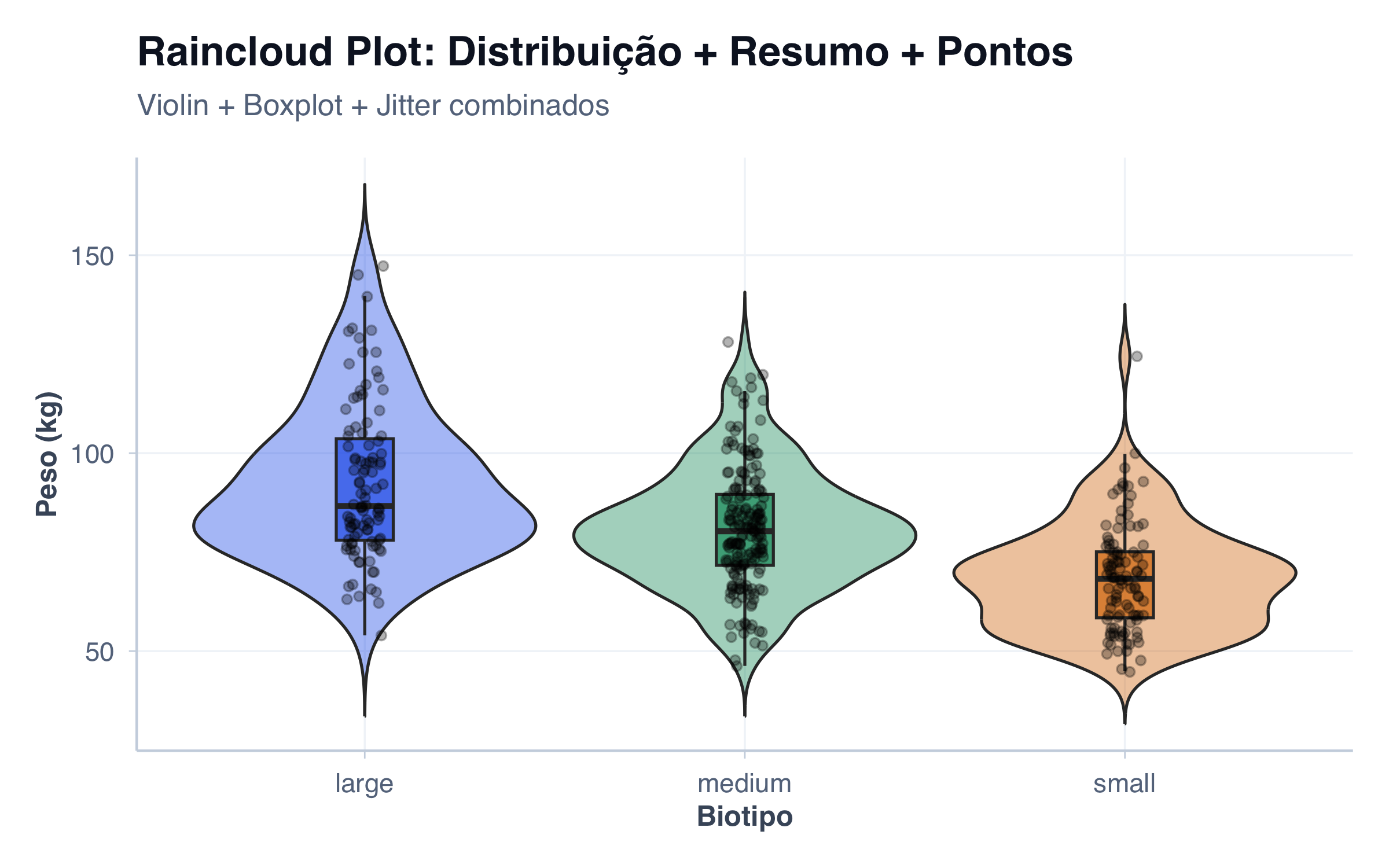
Raincloud Plot: O Melhor dos Três Mundos
Ver código R
pacientes_rain <- pacientes %>%filter(!is.na(peso), !is.na(biotipo))ggplot(pacientes_rain, aes(x = biotipo, y = peso, fill = biotipo)) +# Violin (metade) para simular a "nuvem"geom_violin(trim =FALSE, alpha =0.4, scale ="width") +# Boxplot estreito no centrogeom_boxplot(width =0.15, outlier.color =NA, alpha =0.7) +# Pontos com jittergeom_jitter(size =1.5, alpha =0.3, width =0.05) +scale_fill_manual(values = paleta_cat[1:3]) +tema_graficos() +labs(title ="Raincloud Plot: Distribuição + Resumo + Pontos",subtitle ="Violin + Boxplot + Jitter combinados",x ="Biotipo",y ="Peso (kg)",fill ="Biotipo" ) +theme(legend.position ="none")
O “raincloud plot” combina:
Nuvem de densidade (à esquerda): forma da distribuição.
Boxplot (no meio): cinco números.
Gotas de chuva (à direita): cada ponto.
É a visualização mais completa!
Conclusão
O boxplot, criado por John Tukey há mais de 50 anos, permanece uma das ferramentas mais poderosas para exploração de dados. Sua simplicidade — resumindo uma distribuição em apenas cinco números — não diminui sua utilidade. Ao contrário, essa simplicidade é sua força.
Neste capítulo, você aprendeu:
A anatomia detalhada do boxplot: mediana, quartis, IQR, whiskers, outliers
Variações e extensões: violin plot, notched boxplot, boxplot de largura variável, letter-value plot
Como construir um boxplot passo a passo com ggplot2
Comparação com densidade: quando usar cada um, com suas limitações (Benjamini, 1988)
Dicas para efetividade: ajuste de eixos, investigação de outliers
Lembre-se: o boxplot é uma ferramenta de exploração. Use-o para fazer perguntas, não necessariamente para responder. Quando seus dados mostram outliers inesperados ou padrões curiosos, o boxplot é seu aliado para investigação adicional.
Quiz
NotaQuizz
Questão 1: Interpretando a Mediana
Se em um boxplot a linha da mediana está muito próxima do topo da caixa (Q3), o que isso nos diz sobre a distribuição dos dados?
NotaResposta
A mediana estar próxima do Q3 indica que 50% dos dados estão comprimidos no topo (entre Q3 e máximo), enquanto a outra metade (Q1 a mediana) está espalhada em um intervalo maior. Isso significa a distribuição é assimétrica para baixo (cauda à esquerda). A maioria dos valores está alta, com alguns valores baixos.
Questão 2: O IQR e Variabilidade
Dois grupos têm o mesmo intervalo (mínimo ao máximo) de 40 a 100 kg, mas diferentes IQRs: Grupo A tem IQR = 8 kg, Grupo B tem IQR = 25 kg. Qual grupo é mais variável?
NotaResposta
O Grupo B é mais variável no seu centro (50% dos dados). Um IQR menor significa que a metade central dos dados está mais concentrada em um intervalo pequeno, indicando menos variabilidade. O Grupo A, com IQR pequeno, tem dados muito agrupados.
Questão 3: Calculando Whiskers
Se um grupo tem Q1 = 50 kg, Q3 = 70 kg, qual é o intervalo do whisker inferior?
Você tem dois boxplots lado a lado para colesterol em homens e mulheres. Os boxplots têm praticamente o mesmo tamanho (IQR similar) e mesma mediana, mas o boxplot dos homens tem muito mais outliers visíveis. O que isso sugere?
NotaResposta
O IQR e mediana similares sugerem que as duas populações têm distribuições centrais similares. Os outliers adicionais nos homens sugerem: 1. Há mais homens na amostra (mais chance estatística de outliers) 2. Há mais variabilidade nas extremidades para homens (cauda mais pesada) 3. Pode haver um subgrupo distinto de homens com colesterol muito alto Seria útil investigar se há fatores clínicos explicando esses outliers.
Questão 5: Boxplot vs Densidade
Para uma análise de períodos de incubação de dengue entre 4 sorotipos, com n = 300 observações, você deveria usar boxplot, densidade, ou ambos?
NotaResposta
Ambos, mas por razões diferentes:
- Boxplot: Excelente para comparar 4 grupos lado a lado. Mostra rapidamente se há diferenças nas medianas e IQRs. Identifica outliers.
- Densidade: Revela se algum sorotipo tem distribuição bimodal ou padrões que o boxplot não mostra.
Use boxplot como visualização principal para comparação entre grupos, e densidade como complemento se suspeitar de multimodalidade.
Referências
BENJAMINI, Yoav. Opening the Box of a Boxplot. The American Statistician, [s.l.], vol. 42, n.º 4, pp. 257–262, 1988.
FRIGGE, Michael L.; HOAGLIN, David C.; IGLEWICZ, Boris. Some Implementations of the Boxplot. The American Statistician, [s.l.], vol. 43, n.º 1, pp. 50–54, 1989.