Ver código R
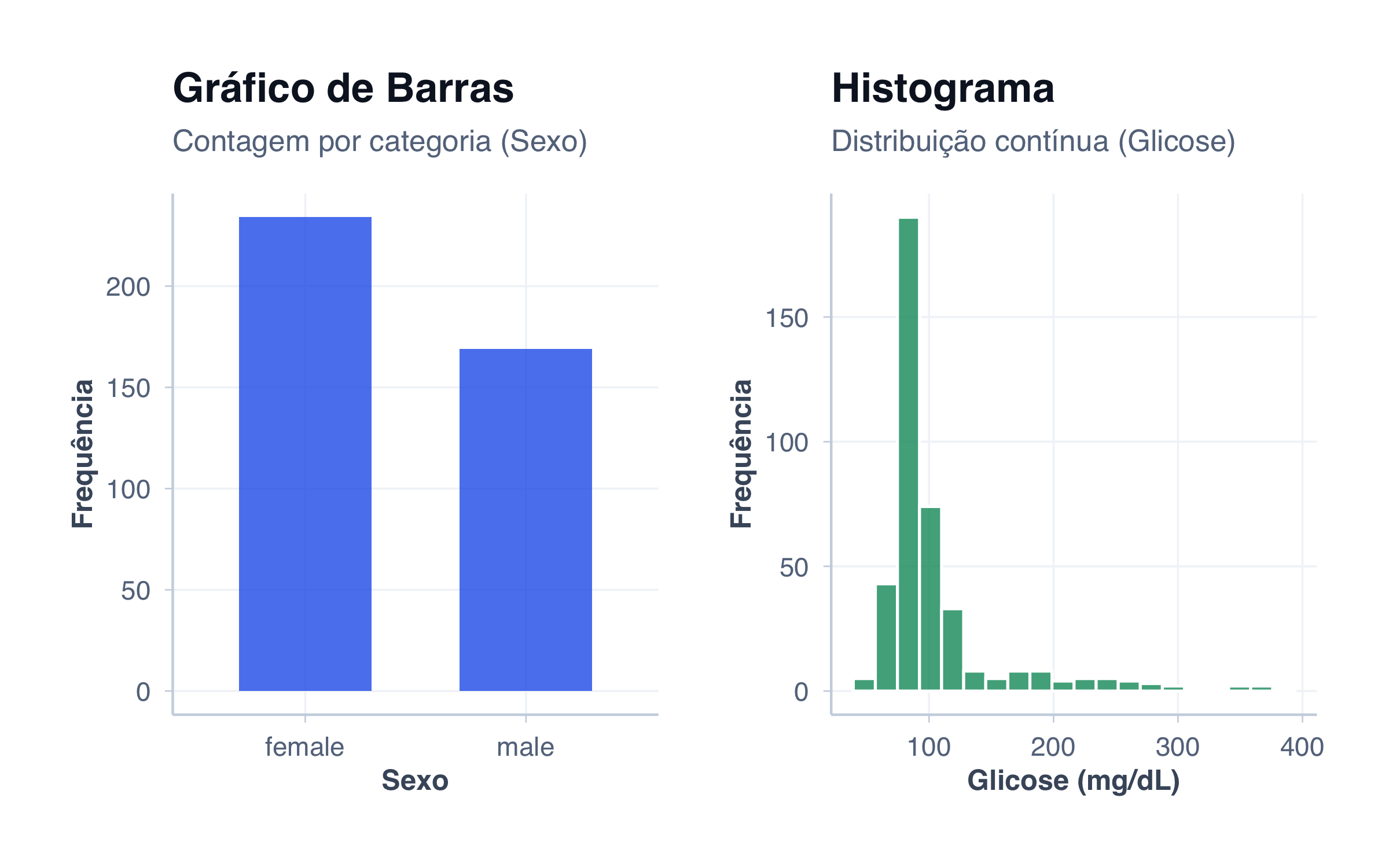
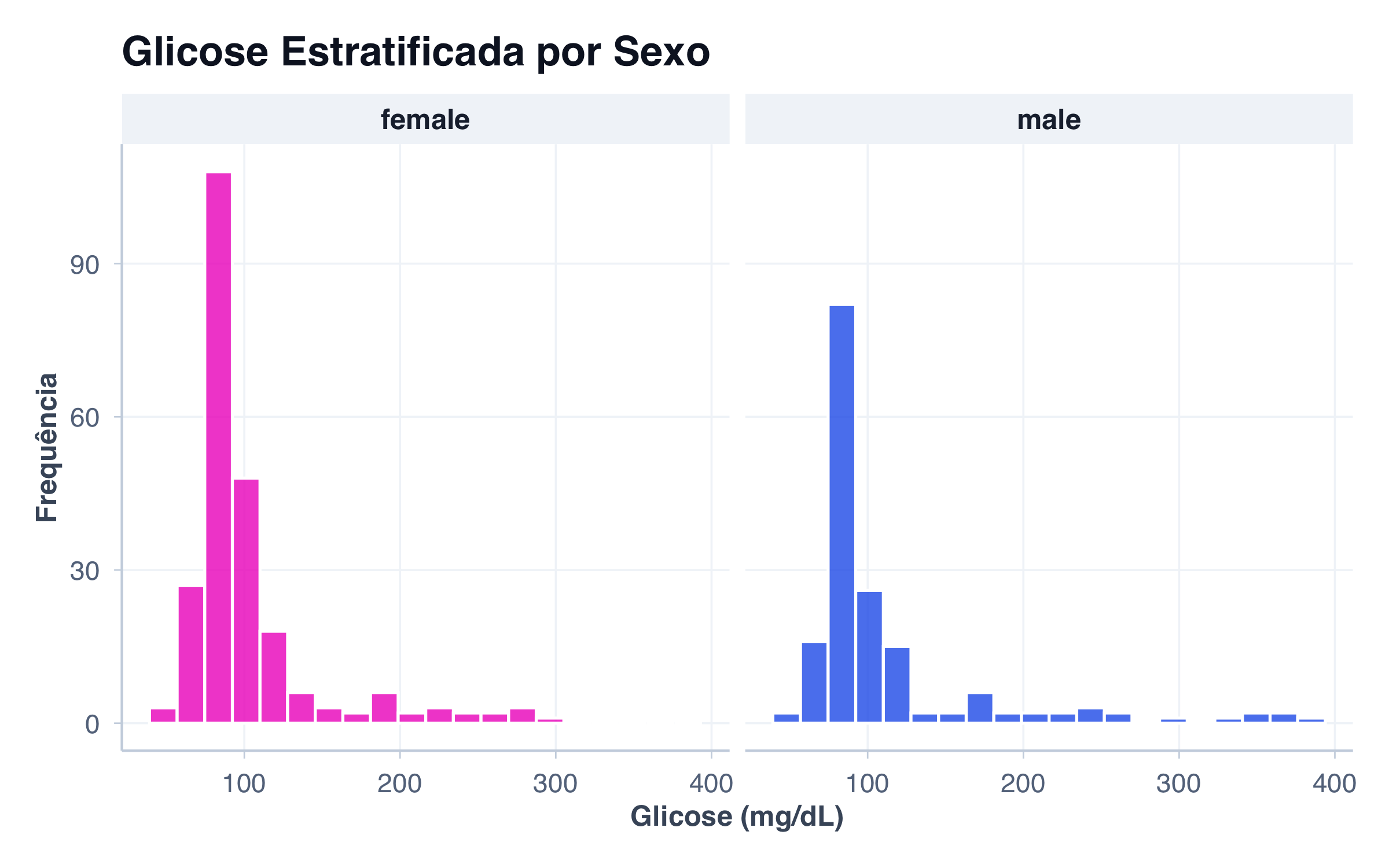
# Gráfico de barras: contagem de pacientes por sexo (variável categórica)
p1 <- ggplot(pacientes, aes(x = sexo)) +
geom_bar(fill = paleta_cat[1], alpha = 0.8, width = 0.6) +
labs(
title = "Gráfico de Barras",
subtitle = "Contagem por categoria (Sexo)",
x = "Sexo",
y = "Frequência"
) +
tema_graficos()
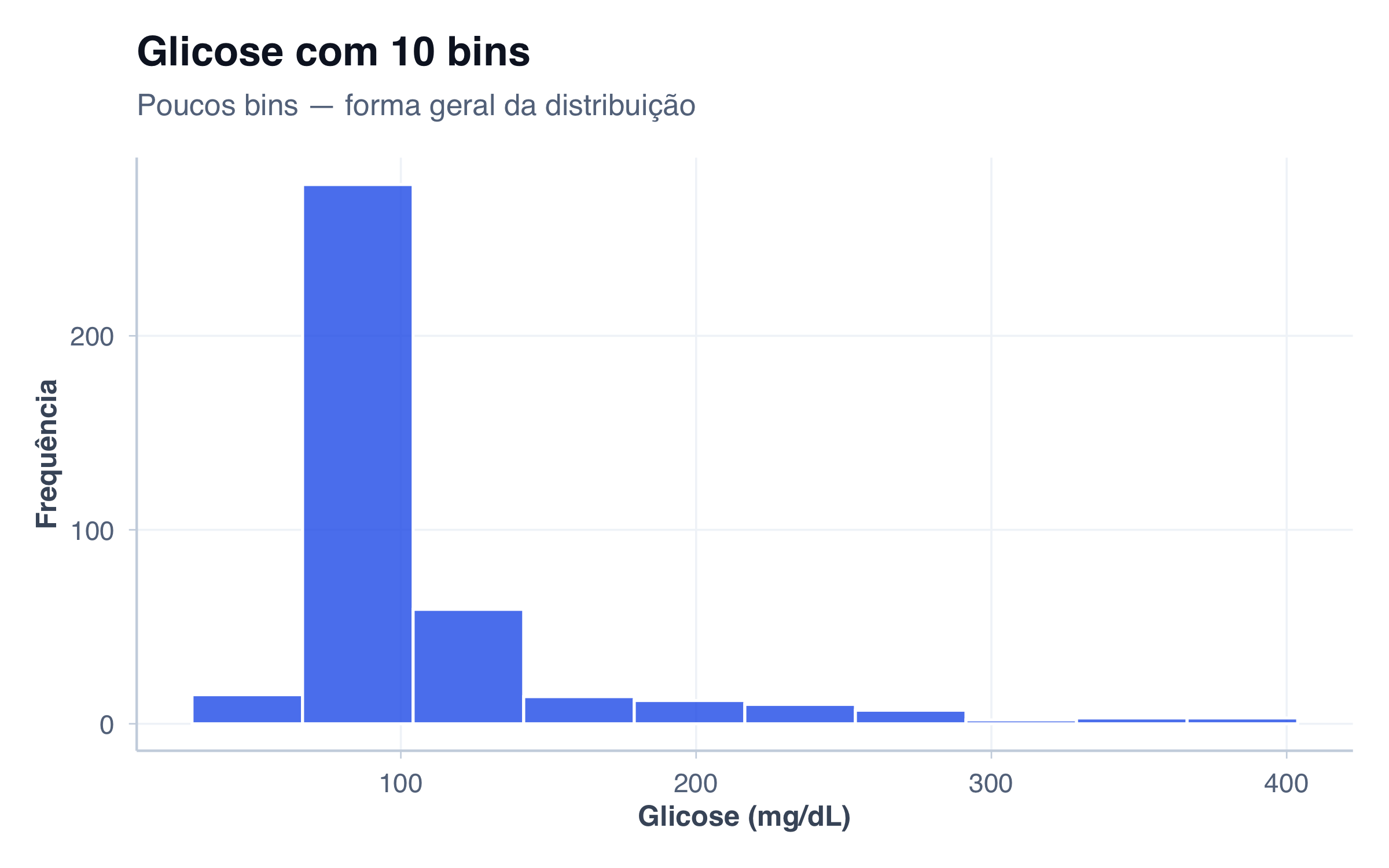
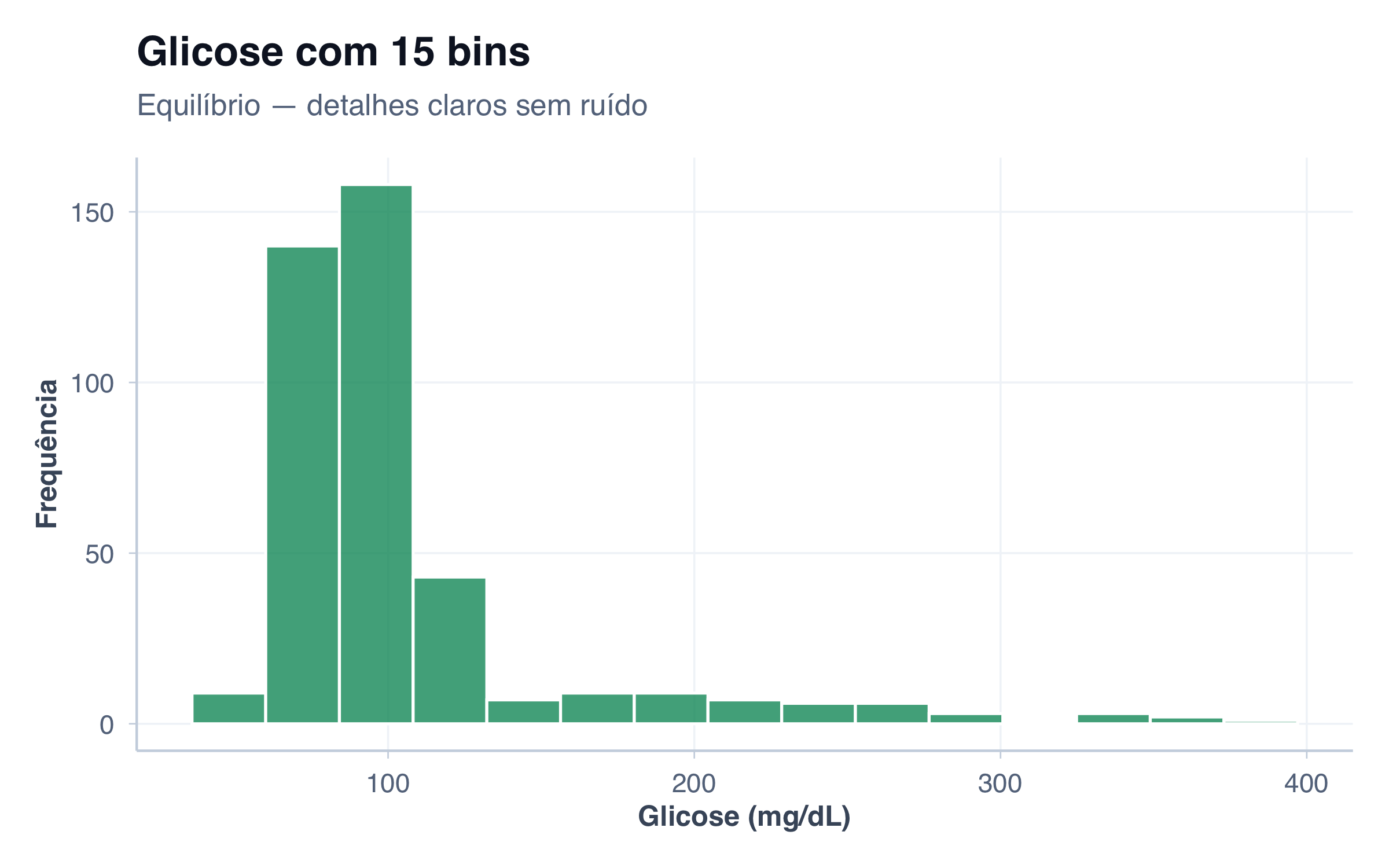
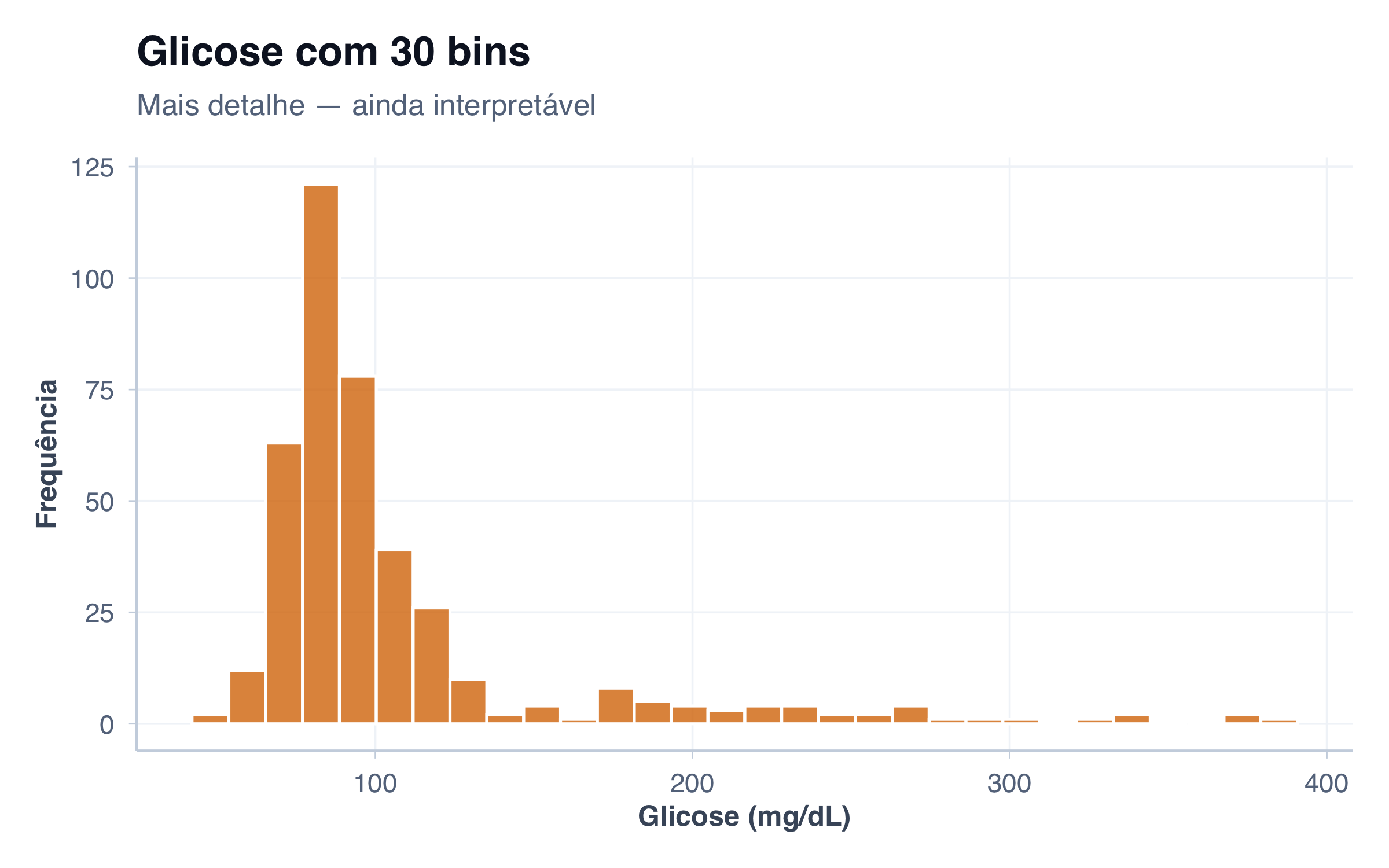
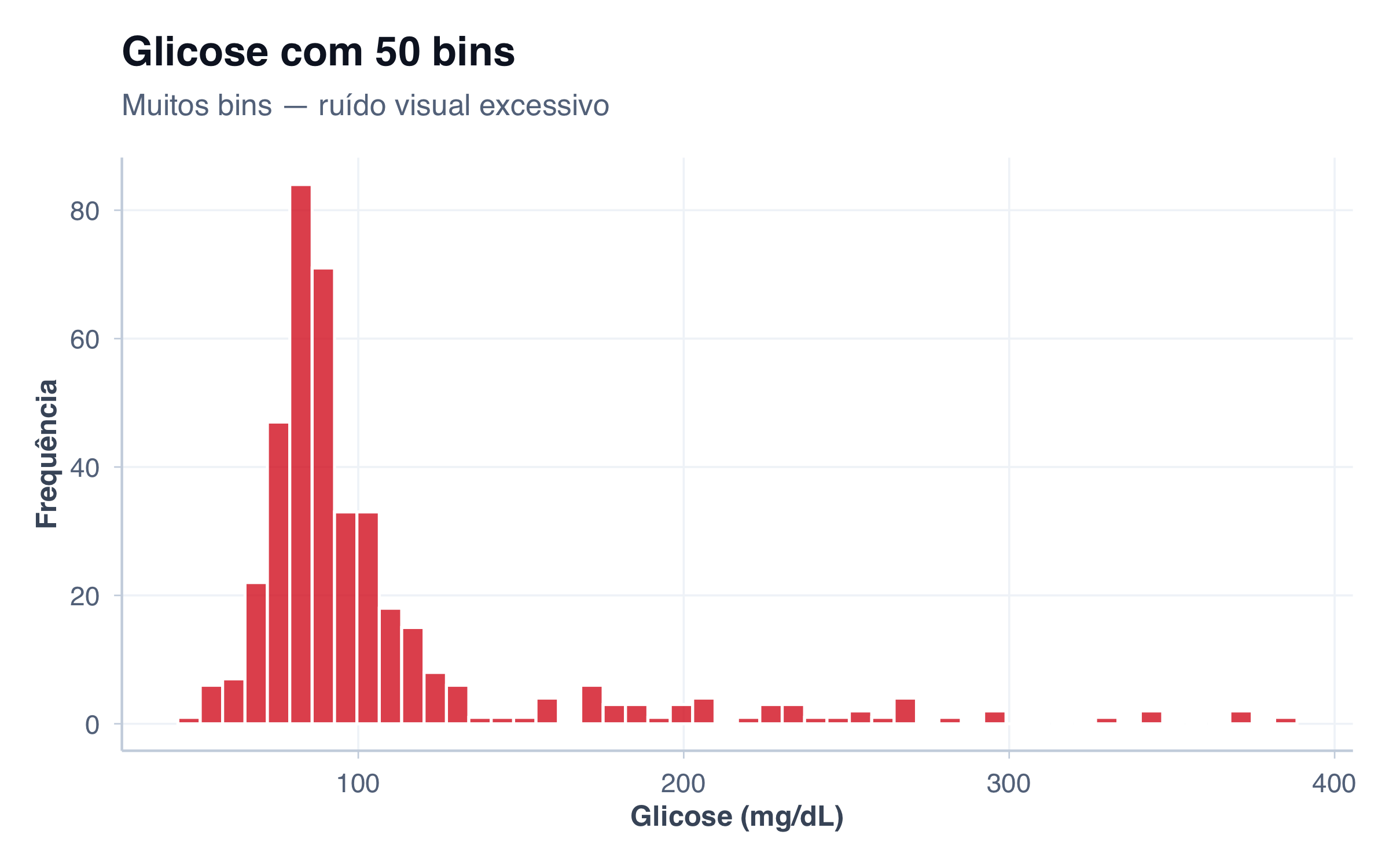
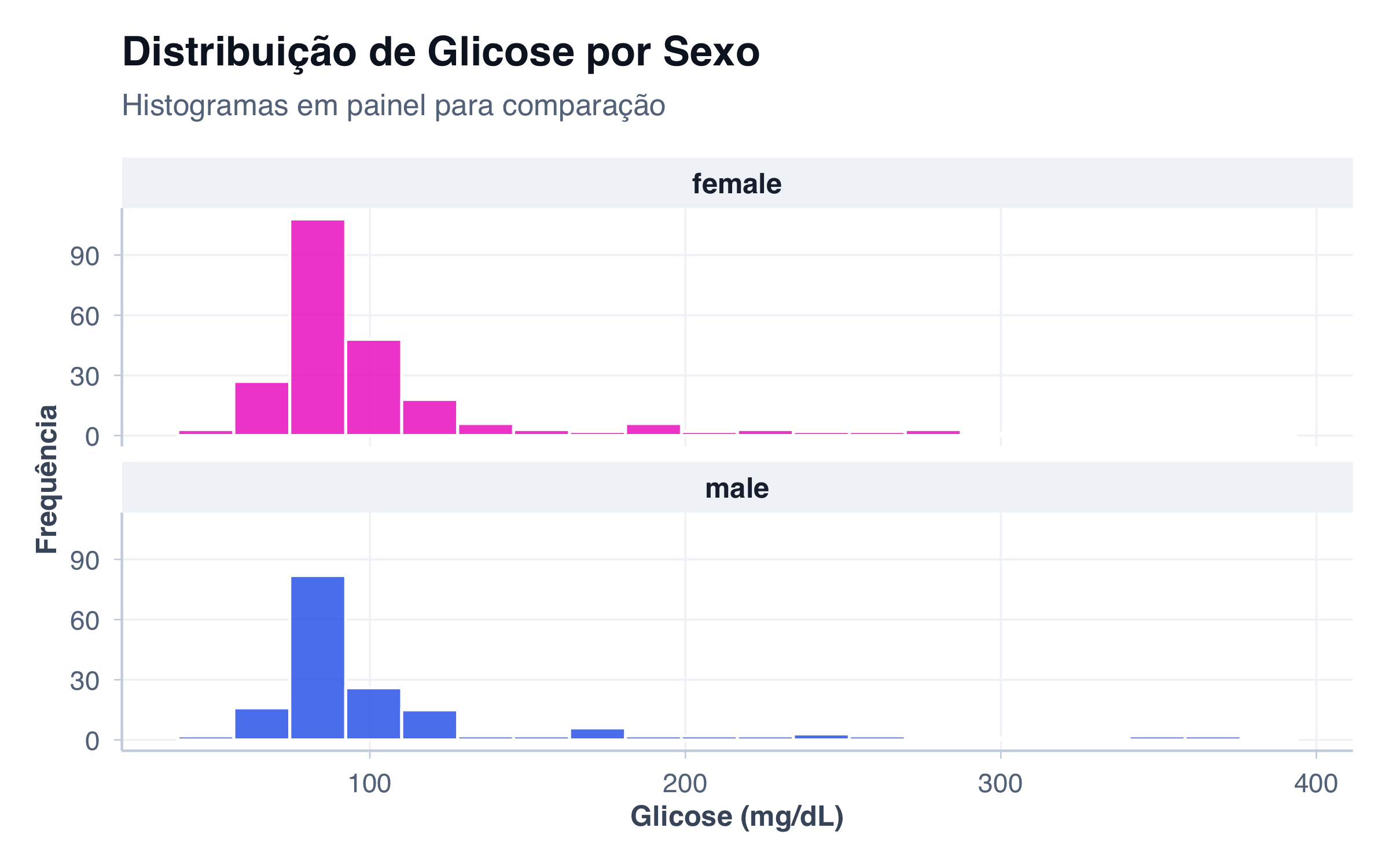
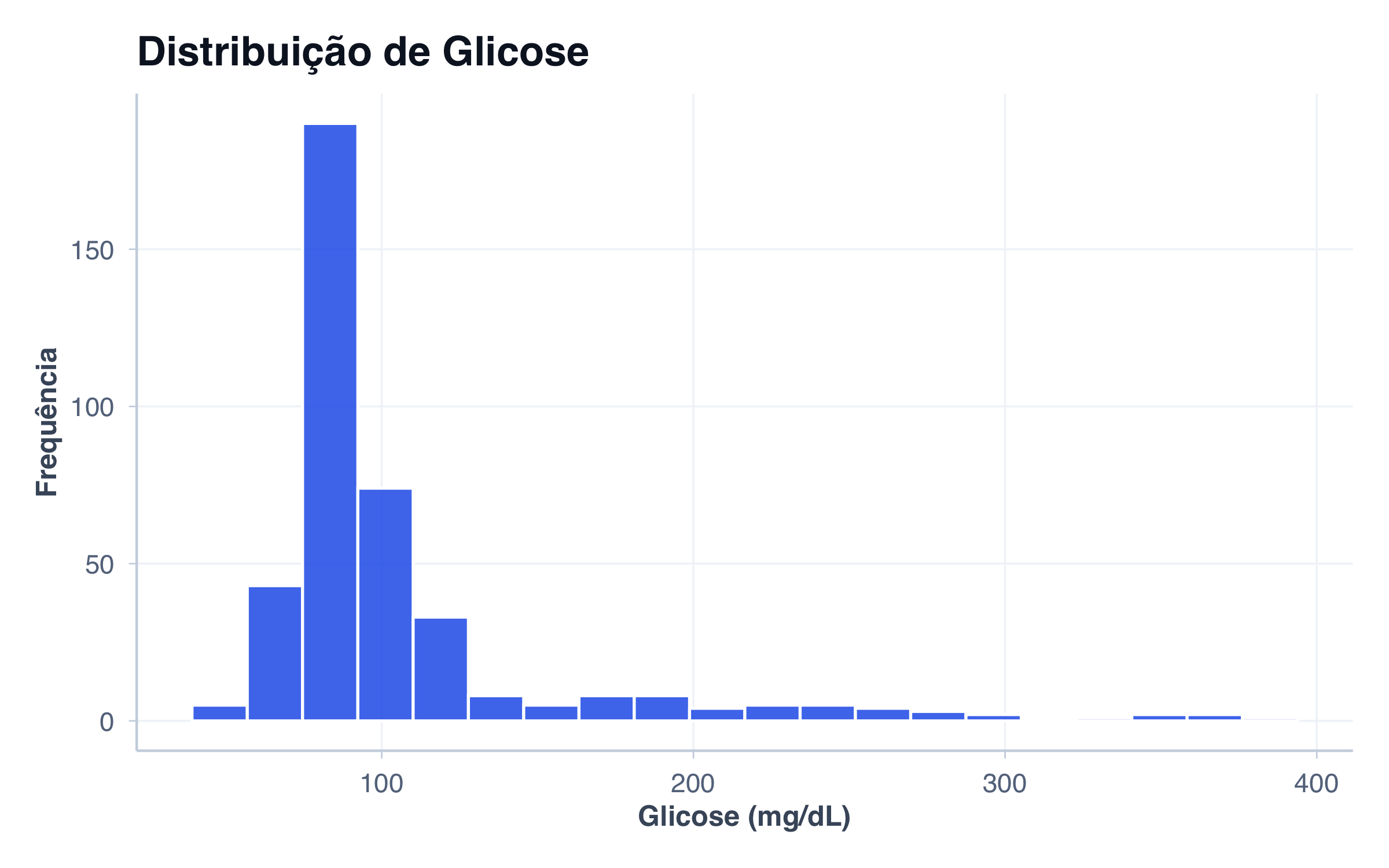
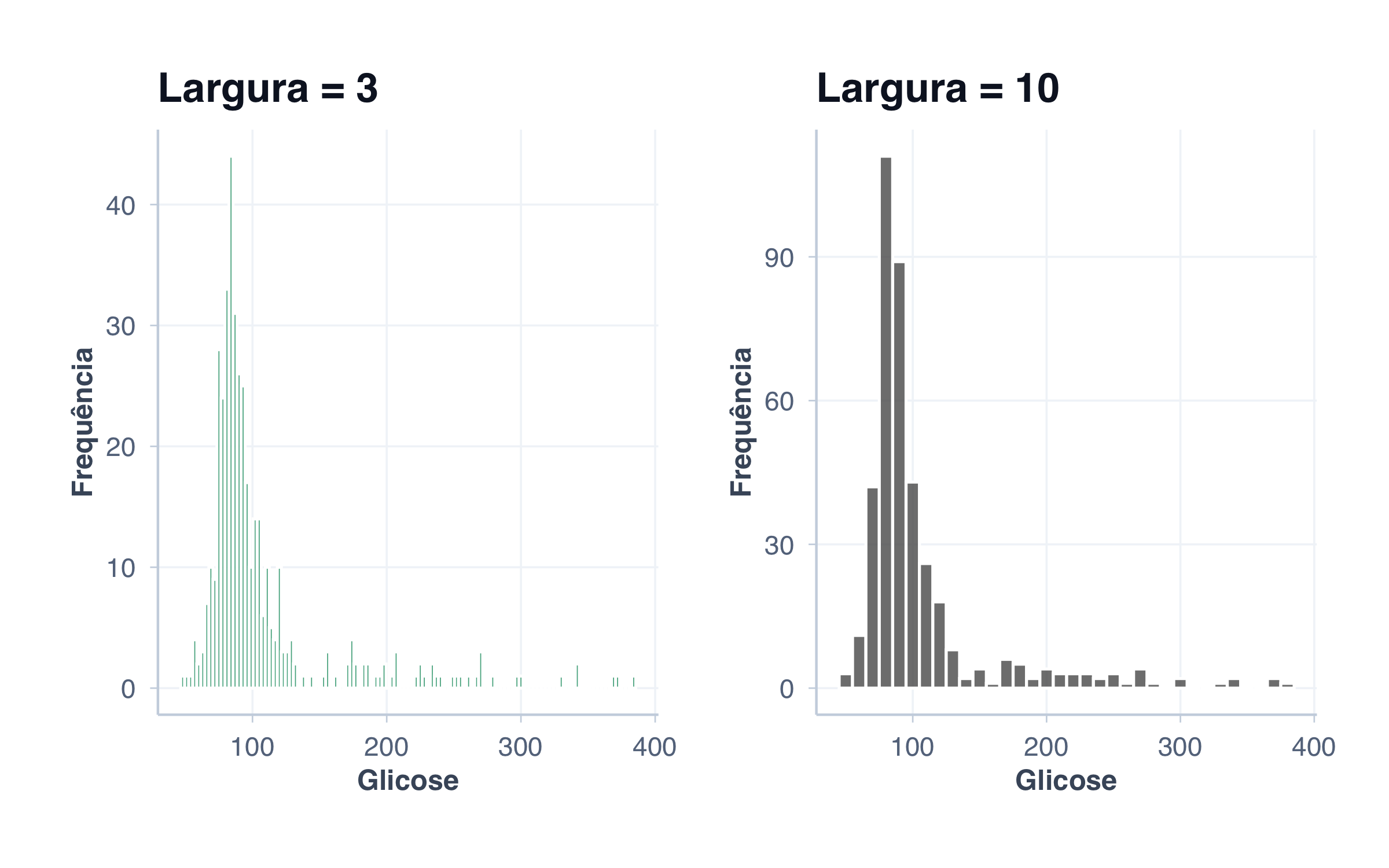
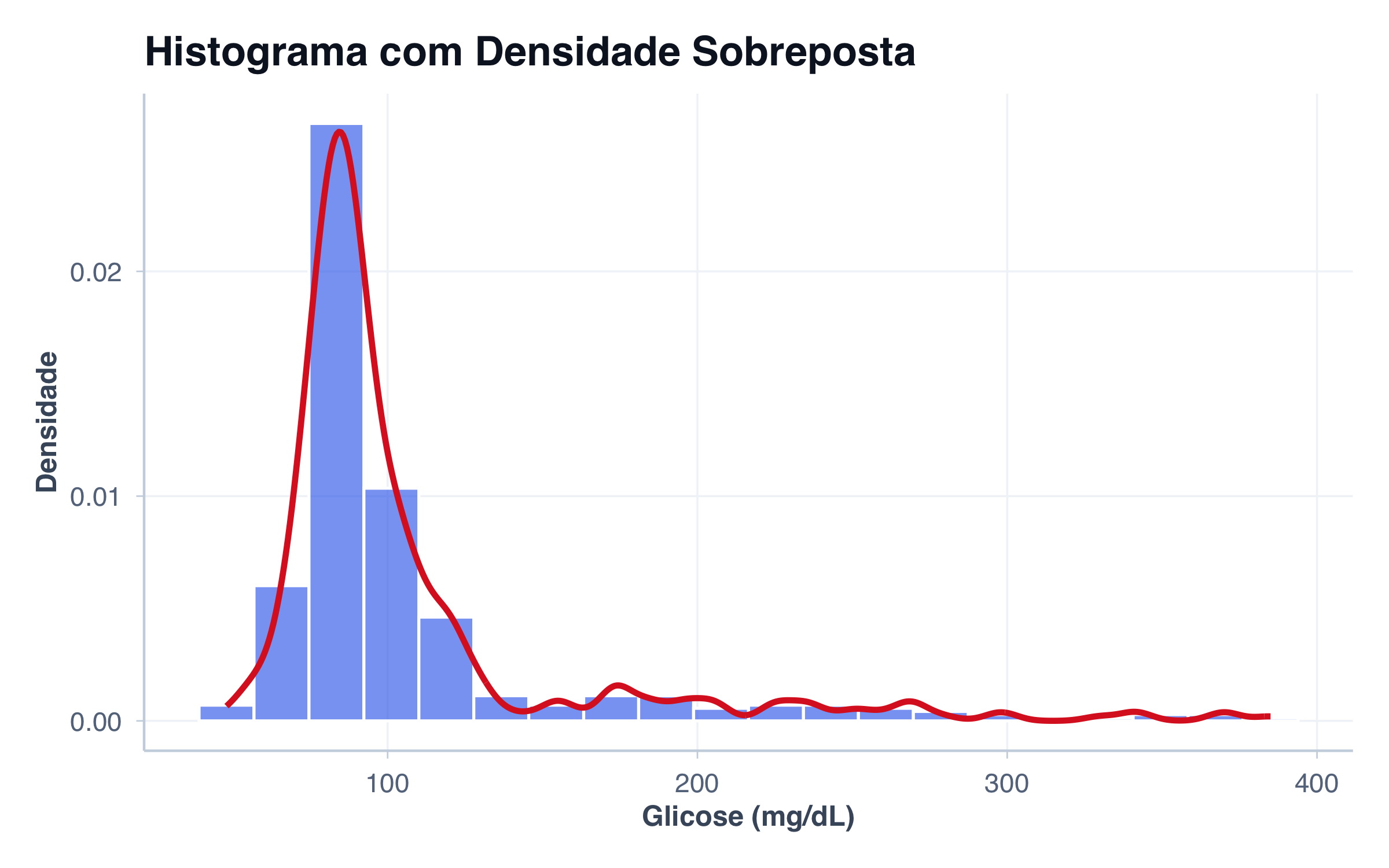
# Histograma: distribuição de glicose (variável numérica contínua)
p2 <- ggplot(pacientes, aes(x = glicose)) +
geom_histogram(fill = paleta_cat[2], alpha = 0.8, bins = 20, color = "white") +
labs(
title = "Histograma",
subtitle = "Distribuição contínua (Glicose)",
x = "Glicose (mg/dL)",
y = "Frequência"
) +
tema_graficos()
p1 + p2