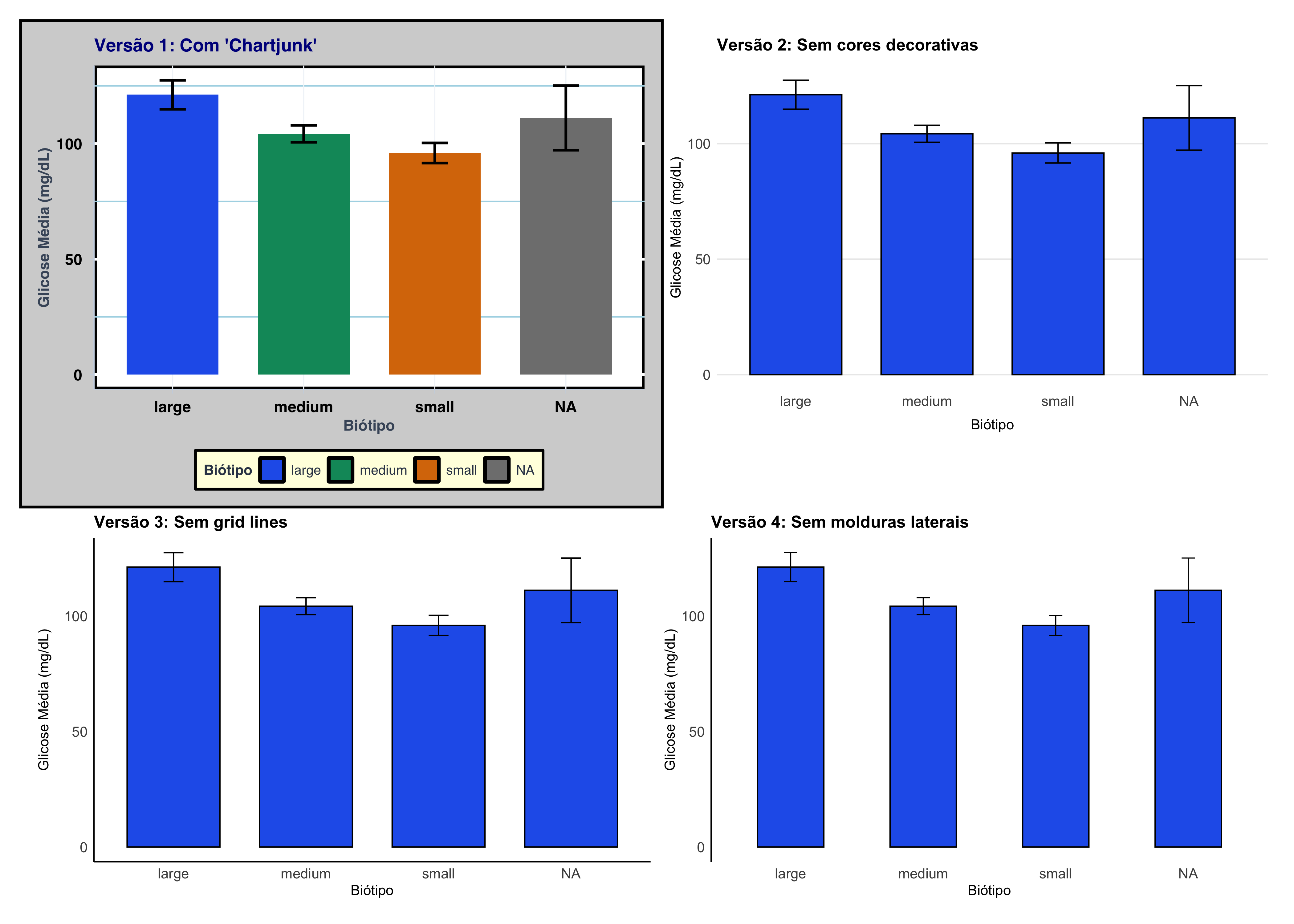
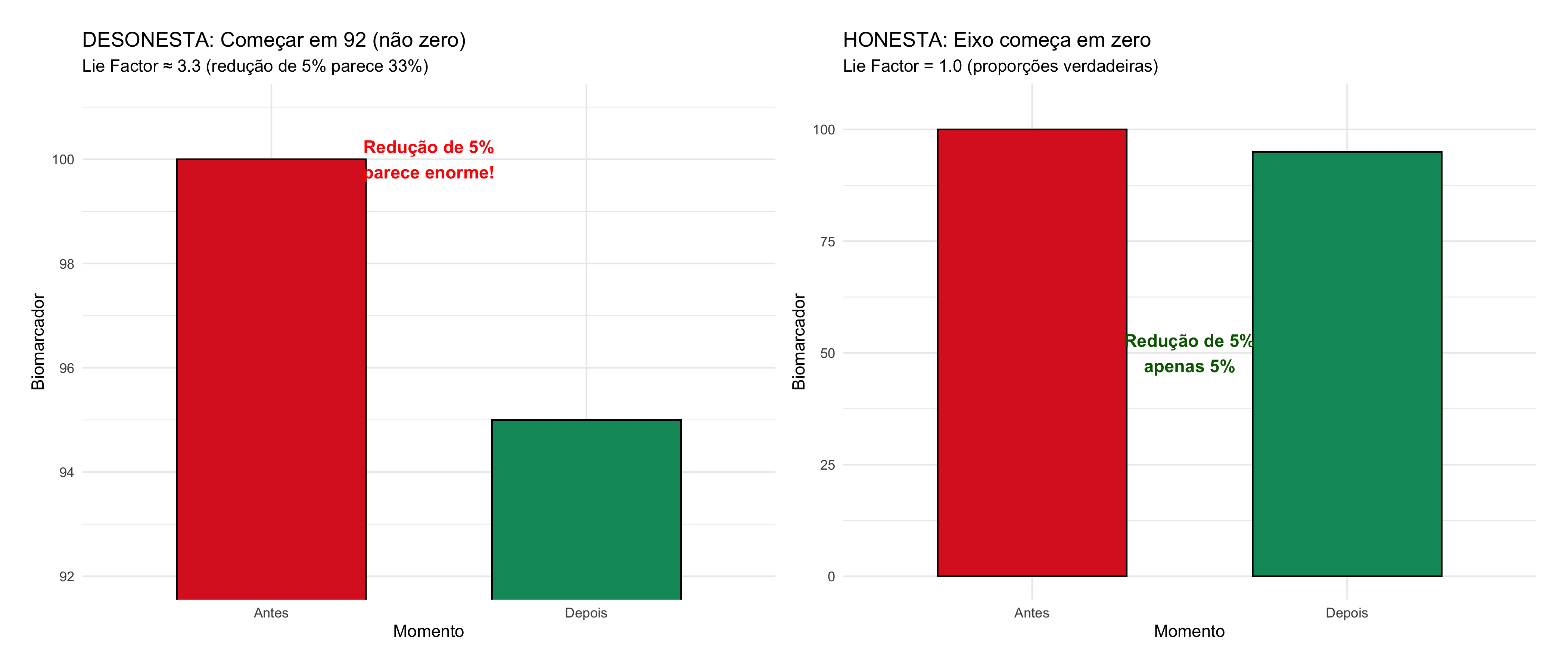
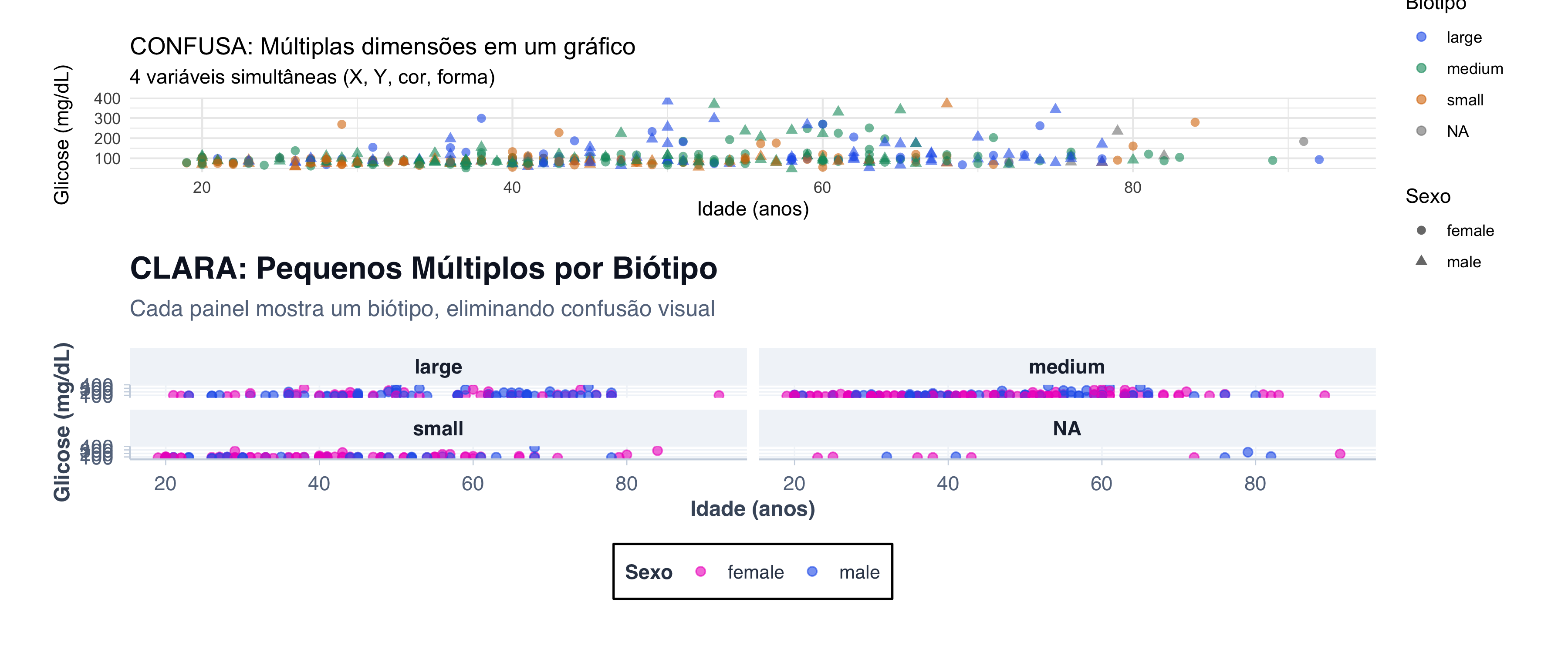
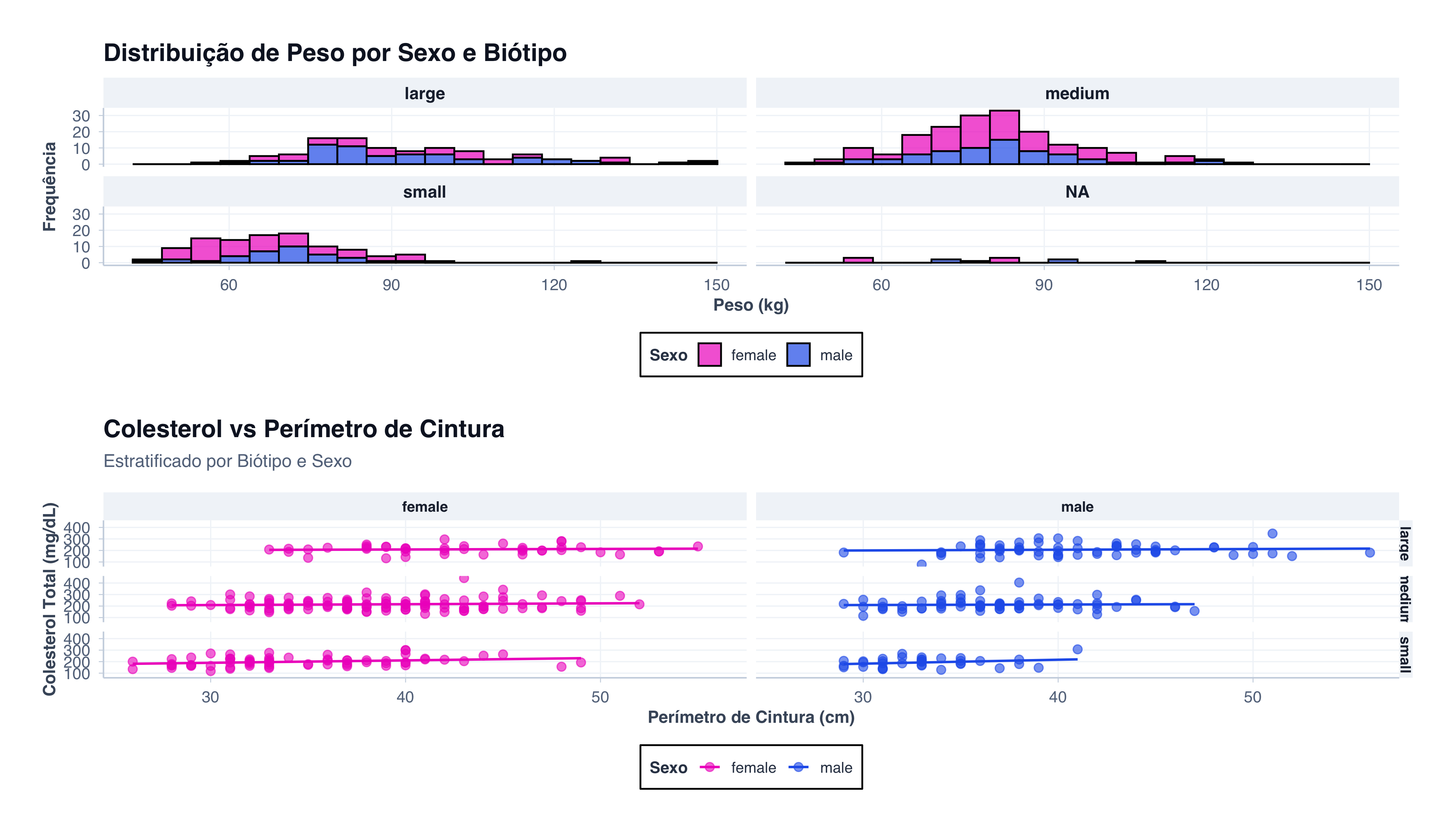
# Preparar dados agregados
glicose_por_biotipo <- pacientes |>
group_by(biotipo) |>
summarise(
media_glicose = mean(glicose, na.rm = TRUE),
desvio = sd(glicose, na.rm = TRUE),
n = n(),
.groups = 'drop'
) |>
mutate(se = desvio / sqrt(n))
# Versão 1: Padrão (com muito chartjunk)
p1 <- glicose_por_biotipo |>
ggplot(aes(x = biotipo, y = media_glicose, fill = biotipo)) +
geom_col(width = 0.7) +
geom_errorbar(aes(ymin = media_glicose - se, ymax = media_glicose + se),
width = 0.2, color = "black", size = 1) +
scale_fill_manual(values = paleta_cat) +
theme(
plot.background = element_rect(fill = "lightgray", color = "black", size = 2),
panel.background = element_rect(fill = "white", color = "black", size = 2),
panel.grid.major.y = element_line(color = "white", size = 1),
panel.grid.minor.y = element_line(color = "lightblue", size = 0.5),
legend.background = element_rect(fill = "lightyellow", color = "black", size = 1),
axis.text = element_text(size = 12, color = "black", face = "bold"),
plot.title = element_text(size = 14, face = "bold", color = "darkblue")
) +
labs(
title = "Versão 1: Com 'Chartjunk'",
x = "Biótipo",
y = "Glicose Média (mg/dL)",
fill = "Biótipo"
)
# Versão 2: Remover cores decorativas (manter cor funcional)
p2 <- glicose_por_biotipo |>
ggplot(aes(x = biotipo, y = media_glicose)) +
geom_col(fill = cores$azul, width = 0.7, color = "black", size = 0.5) +
geom_errorbar(aes(ymin = media_glicose - se, ymax = media_glicose + se),
width = 0.2, color = "black", size = 0.5) +
theme_minimal() +
theme(
panel.grid.major.x = element_blank(),
panel.grid.minor = element_blank(),
axis.text = element_text(size = 11),
plot.title = element_text(size = 13, face = "bold")
) +
labs(
title = "Versão 2: Sem cores decorativas",
x = "Biótipo",
y = "Glicose Média (mg/dL)"
)
# Versão 3: Remover grid lines (dados já são lidos pelo eixo Y)
p3 <- glicose_por_biotipo |>
ggplot(aes(x = biotipo, y = media_glicose)) +
geom_col(fill = cores$azul, width = 0.7, color = "black", size = 0.5) +
geom_errorbar(aes(ymin = media_glicose - se, ymax = media_glicose + se),
width = 0.15, color = "black", size = 0.5) +
theme_minimal() +
theme(
panel.grid = element_blank(),
axis.line = element_line(color = "black", size = 0.5),
axis.text = element_text(size = 11),
plot.title = element_text(size = 13, face = "bold")
) +
labs(
title = "Versão 3: Sem grid lines",
x = "Biótipo",
y = "Glicose Média (mg/dL)"
)
# Versão 4: Remover molduras (spines)
p4 <- glicose_por_biotipo |>
ggplot(aes(x = biotipo, y = media_glicose)) +
geom_col(fill = cores$azul, width = 0.5, color = "black", size = 0.4) +
geom_errorbar(aes(ymin = media_glicose - se, ymax = media_glicose + se),
width = 0.1, color = "black", size = 0.4) +
theme_minimal() +
theme(
panel.grid = element_blank(),
axis.line.y = element_line(color = "black", size = 0.5),
axis.line.x = element_blank(),
axis.text = element_text(size = 11),
axis.ticks.x = element_blank(),
plot.title = element_text(size = 13, face = "bold")
) +
labs(
title = "Versão 4: Sem molduras laterais",
x = "Biótipo",
y = "Glicose Média (mg/dL)"
)
# Montar em grid
(p1 + p2) / (p3 + p4)