Quando queremos entender como duas variáveis numéricas se relacionam, o scatter plot (gráfico de dispersão) é nossa ferramenta mais poderosa. Ele nos permite visualizar padrões, tendências e associações que seriam invisíveis em tabelas de números.
Neste capítulo, exploraremos em profundidade como criar, interpretar e aproveitar scatter plots para investigar relações entre variáveis em dados médicos.
Um Pouco de História
DicaA Origem do Scatter Plot
O scatter plot foi desenvolvido no século XIX por Francis Galton, um estatístico e polímata britânico que estava estudando a relação entre a altura dos pais e a altura dos filhos. Galton percebeu que os filhos de pais muito altos tendiam a ser altos, mas não tão altos quanto seus pais — um fenômeno que chamou de “regressão à média”.
Seu aluno, Karl Pearson, então formalizou o conceito da correlação e desenvolveu o coeficiente de correlação de Pearson (r) que usamos até hoje. O trabalho deles estabeleceu a base para toda a análise de regressão moderna.
O termo “regressão” é, na verdade, um acidente histórico. Galton cunhou a expressão regression towards mediocrity para descrever um fenômeno biológico específico: filhos de pais muito altos tendiam a ser mais baixos que seus pais, “regredindo” em direção à média da população (Galton, 1886). O nome acabou associado à técnica estatística de ajustar uma reta aos dados, mesmo que o método matemático dos mínimos quadrados já existisse desde Legendre e Gauss, décadas antes de Galton (Stanton, 2001). Hoje, seria mais preciso falar em reta de melhor ajuste (best fit line) do que em “regressão” — mas o termo original permaneceu por tradição.
O que é um Scatter Plot?
Um scatter plot é um gráfico que mostra a relação entre duas variáveis numéricas, onde:
Eixo X (horizontal): Representa a primeira variável numérica
Eixo Y (vertical): Representa a segunda variável numérica
Cada ponto: Representa uma observação individual (um paciente, neste caso)
Por exemplo, podemos perguntar: “Existe uma relação entre a medida do quadril e o peso dos pacientes?”
Vamos começar com nosso exemplo principal:
Ver código R
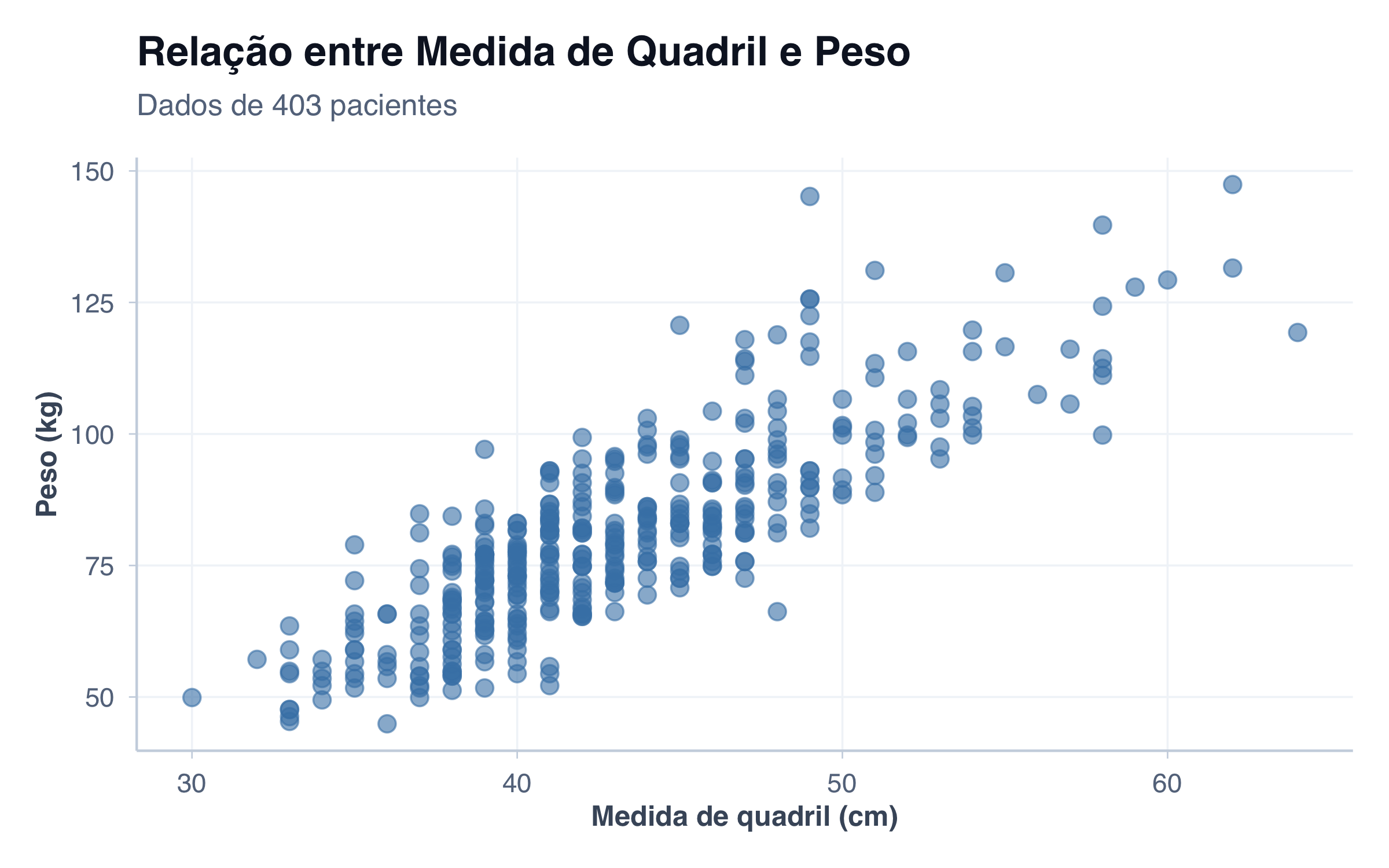
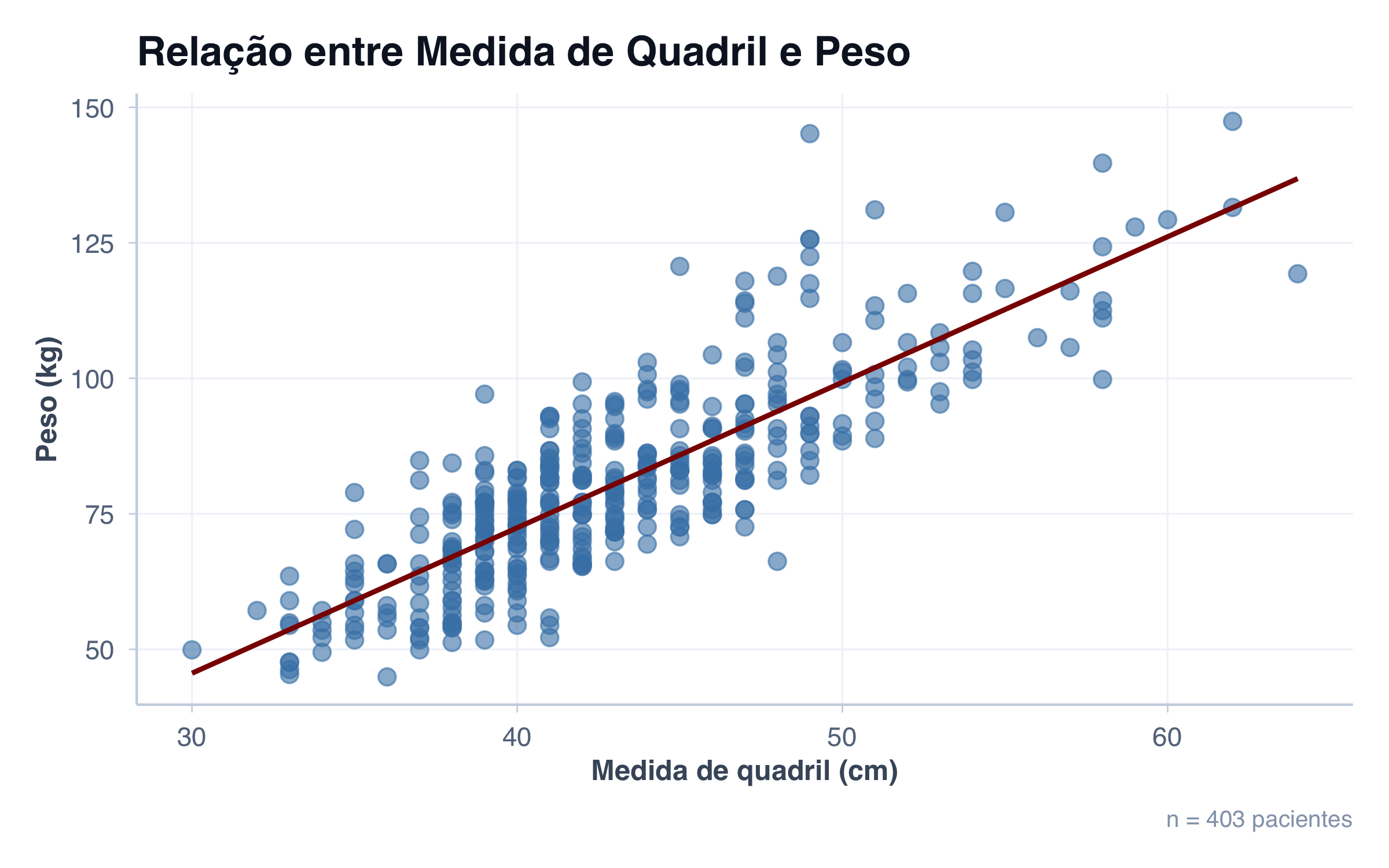
# Scatter plot básico: Quadril × Pesoggplot(pacientes, aes(x = quadril, y = peso)) +geom_point(size =3, alpha =0.6, color ="steelblue") +tema_graficos() +labs(title ="Relação entre Medida de Quadril e Peso",subtitle ="Dados de 403 pacientes",x ="Medida de quadril (cm)",y ="Peso (kg)" )
Apenas observando este gráfico, você pode ver claramente que existe uma relação positiva entre essas variáveis: conforme o quadril aumenta, o peso também tende a aumentar.
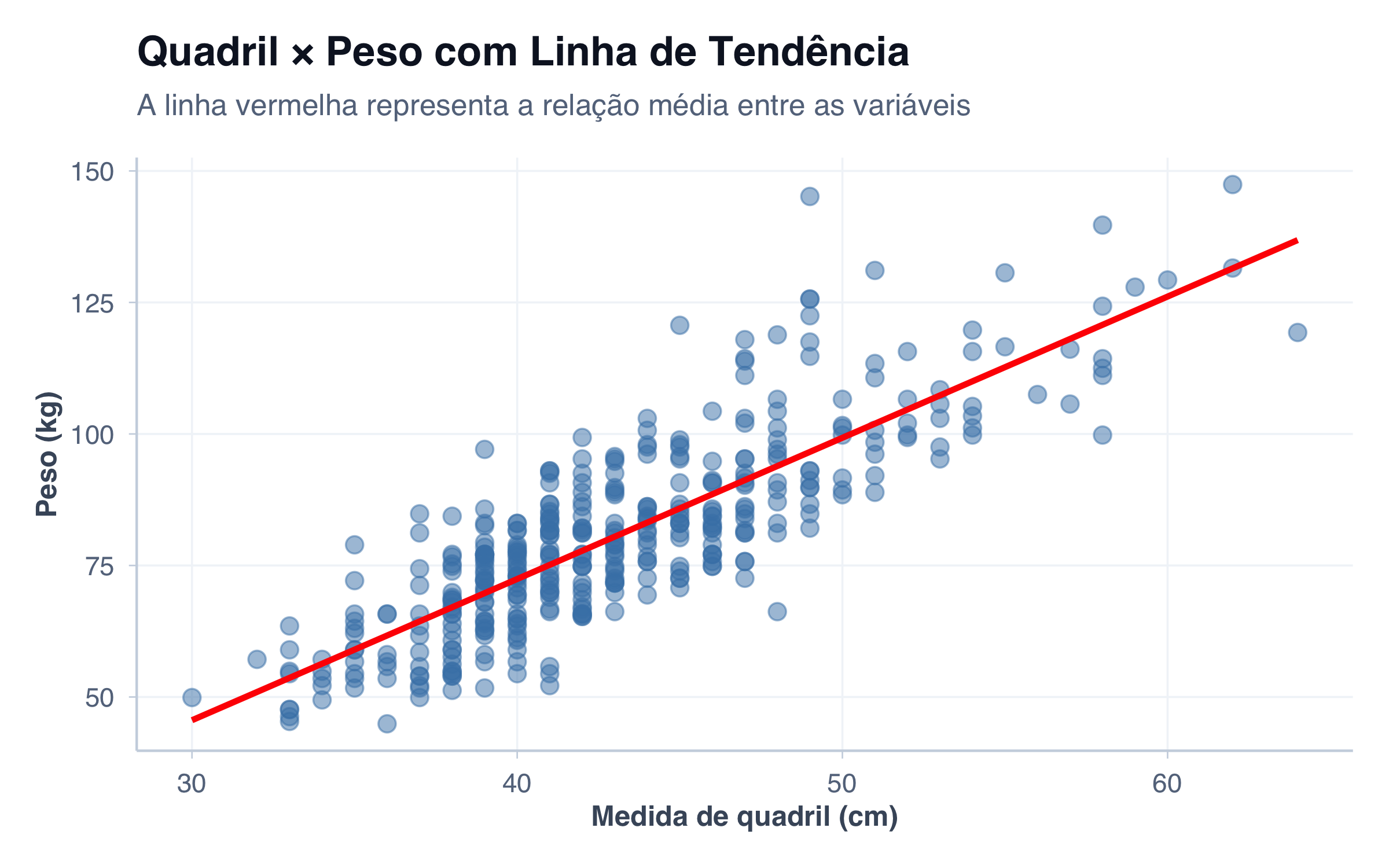
A Linha de Tendência (Best Fit Line)
Uma das ferramentas mais úteis no scatter plot é a linha de tendência, ou best fit line, também chamada de linha de regressão. Esta linha passa pelos dados de forma que minimiza a distância total entre os pontos e a linha.
Como a Linha é Calculada?
Matematicamente, a linha é encontrada usando o método dos mínimos quadrados. A ideia é simples (intuitivamentente):
Imagine uma linha passando pelos pontos
Meça a distância vertical de cada ponto até a linha
Eleve essas distâncias ao quadrado
Some todas essas distâncias ao quadrado
Encontre a linha que minimiza esse somatório
Visualmente, é como se estivéssemos procurando a linha que “melhor se ajusta” aos dados, minimizando os “resíduos” (as diferenças entre os valores observados e os valores previstos pela linha).
A Linha como Modelo Preditivo
O poder real da linha de tendência é que ela nos permite fazer previsões.
Por exemplo: “Se um paciente tem quadril de 100 cm, qual seria seu peso esperado?”
Olhando para a linha no gráfico abaixo, podemos estimar essa previsão:
Ver código R
# Scatter plot com linha de regressãoggplot(pacientes, aes(x = quadril, y = peso)) +geom_point(size =3, alpha =0.5, color ="steelblue") +geom_smooth(method ="lm", se =FALSE, color ="red", linewidth =1.2) +tema_graficos() +labs(title ="Quadril × Peso com Linha de Tendência",subtitle ="A linha vermelha representa a relação média entre as variáveis",x ="Medida de quadril (cm)",y ="Peso (kg)" )
A Imprecisão da Previsão
Aqui está um ponto crucial: a linha não prevê perfeitamente. Há variação!
Observe os pontos com quadril entre 99-101 cm: eles têm pesos bastante diferentes (alguns ao redor de 70 kg, outros acima de 100 kg). A linha passa pelo “meio” dessa variação.
Isso significa que:
A linha nos diz a tendência geral
Mas há incerteza individual ao fazer uma previsão para um paciente específico
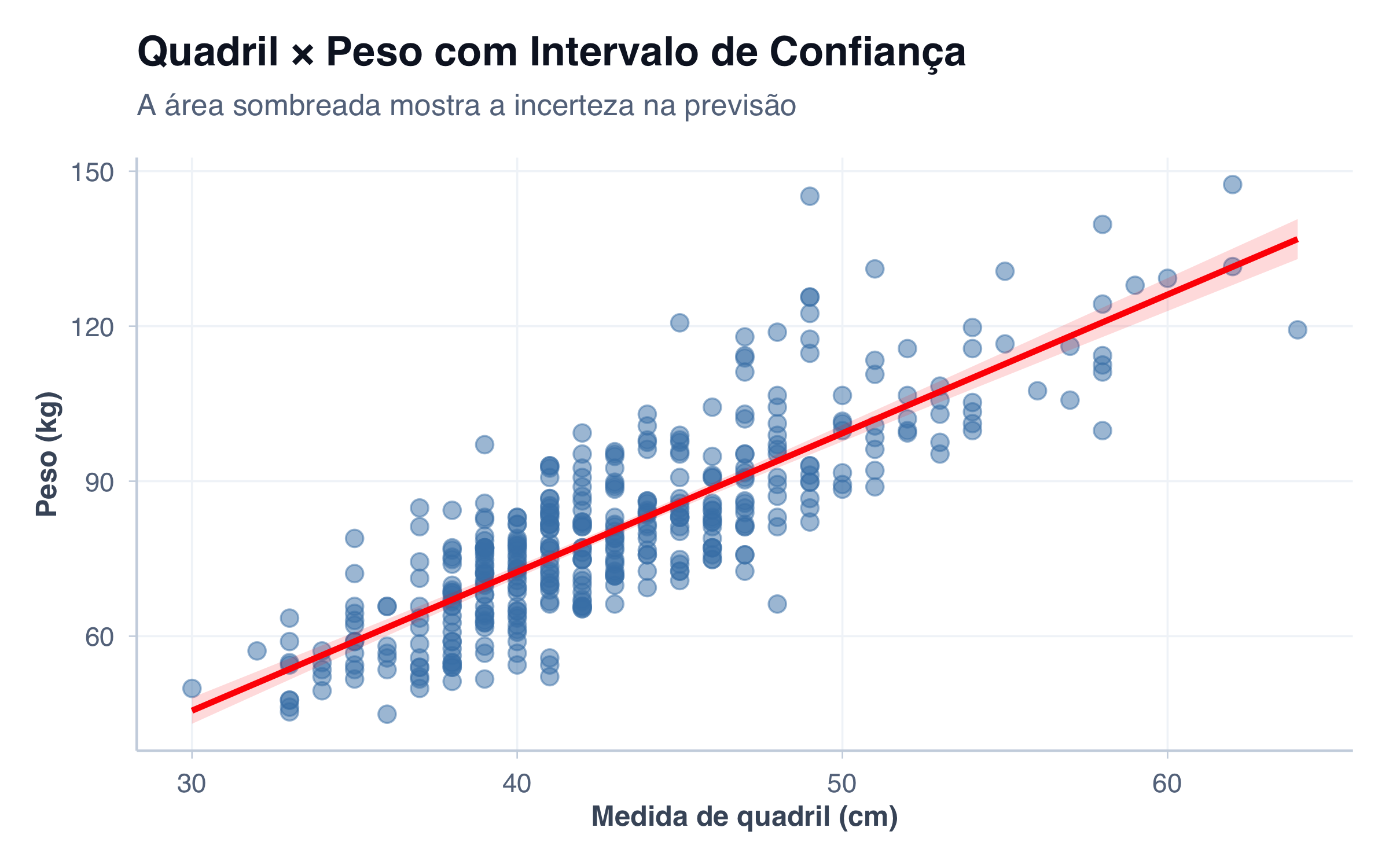
Para visualizar essa incerteza, podemos mostrar o intervalo de confiança (a área sombreada ao redor da linha):
Ver código R
# Scatter plot com intervalo de confiançaggplot(pacientes, aes(x = quadril, y = peso)) +geom_point(size =3, alpha =0.5, color ="steelblue") +geom_smooth(method ="lm", se =TRUE, color ="red", linewidth =1.2, fill ="red", alpha =0.15) +tema_graficos() +labs(title ="Quadril × Peso com Intervalo de Confiança",subtitle ="A área sombreada mostra a incerteza na previsão",x ="Medida de quadril (cm)",y ="Peso (kg)" )
A área sombreada ao redor da linha representa o intervalo de confiança de 95% — podemos ter 95% de confiança de que um novo paciente com determinado quadril terá peso dentro dessa faixa.
Os Resíduos
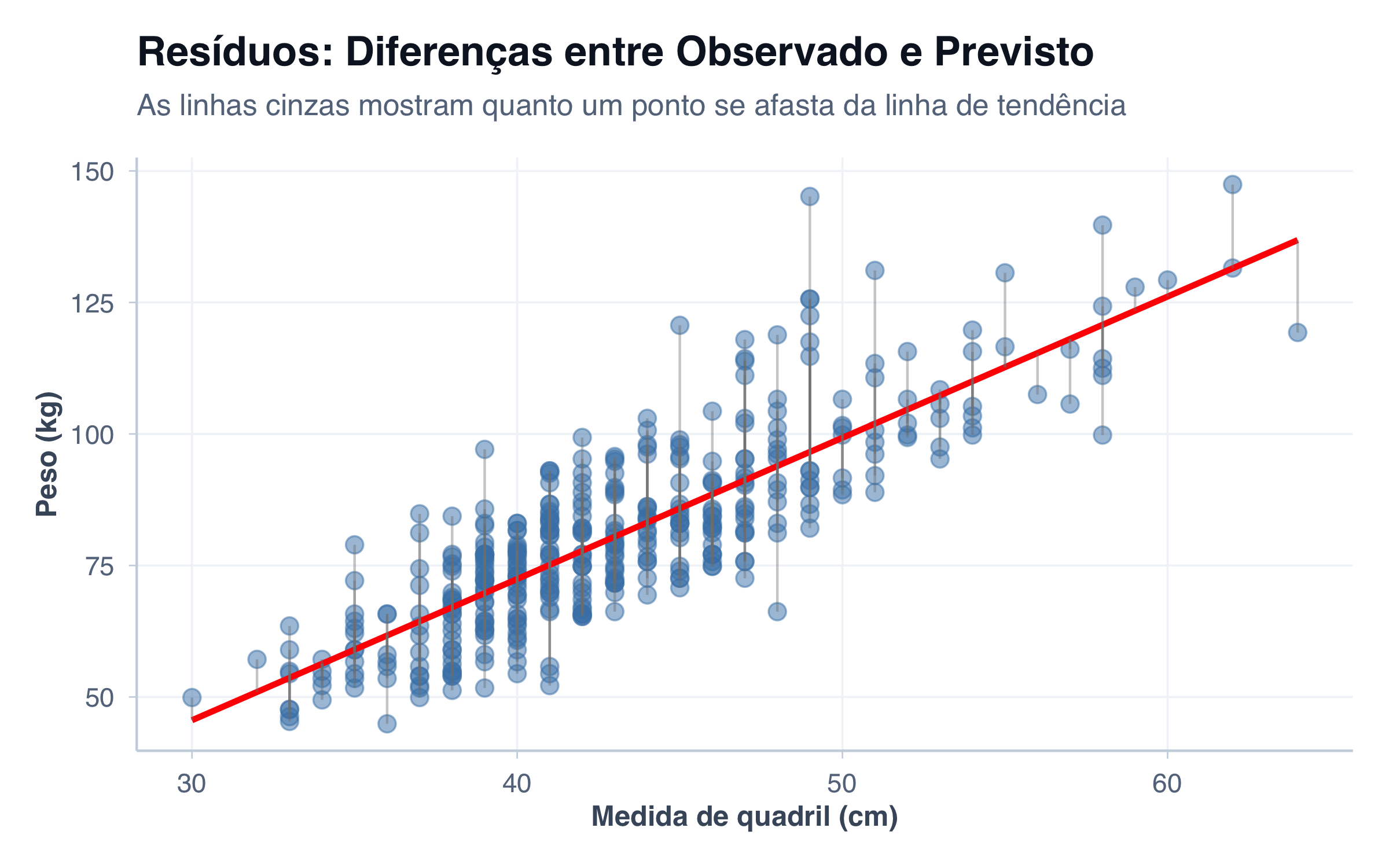
Imagine que a linha de tendência é sua “previsão” para cada paciente. Por exemplo, se um paciente tem quadril de 100 cm, a linha prevê que seu peso será, digamos, 78 kg. Mas o peso real desse paciente é 85 kg. Essa diferença de 7 kg entre o valor real e o previsto é o que chamamos de resíduo. Quanto menores e mais aleatoriamente distribuídos forem os resíduos, melhor o modelo se ajusta aos dados.
No gráfico abaixo, as linhas verticais entre cada ponto e a reta representam exatamente isso — o resíduo de cada observação. Pontos acima da reta têm resíduo positivo (a realidade superou a previsão); pontos abaixo têm resíduo negativo (a previsão superestimou). Essas linhas são apenas uma ferramenta visual para entender o conceito — na prática, o que nos interessa é o que fazemos com esses resíduos depois.
O passo seguinte é somar os quadrados de todos os resíduos. Elevamos ao quadrado para que resíduos positivos e negativos não se cancelem, e para penalizar erros grandes mais do que erros pequenos. Essa soma — chamada de soma dos quadrados dos resíduos (SQR) — mede o erro total do modelo: quanto menor, melhor a reta se ajusta aos dados.
Mas “menor” em relação a quê? Precisamos de uma referência. A referência é a variação total dos dados — a soma dos quadrados das distâncias de cada ponto até a média geral de Y (sem usar nenhuma reta). Essa variação total mede quanto os dados variam “por conta própria”.
O R² (coeficiente de determinação) é simplesmente a proporção da variação total que a reta conseguiu explicar:
\(R^2 = 1 - \frac{\text{Soma dos quadrados dos resíduos}}{\text{Variação total dos dados}}\)
A interpretação é direta: um R² = 0,85 significa que a reta explica 85% da variação nos dados — os resíduos representam apenas 15% de “erro”. Um R² = 0,10 significa que a reta explica quase nada — os pontos estão tão espalhados que a reta não ajuda muito a prever.
Ver código R
# Criar modelo linear para extrair resíduos (remover NAs primeiro)pacientes_modelo <- pacientes %>%filter(!is.na(peso), !is.na(quadril))modelo <-lm(peso ~ quadril, data = pacientes_modelo)pacientes_modelo <- pacientes_modelo %>%mutate(peso_previsto =predict(modelo),residuo = peso - peso_previsto )# Visualizar alguns resíduosggplot(pacientes_modelo, aes(x = quadril, y = peso)) +geom_point(size =3, alpha =0.5, color ="steelblue") +geom_smooth(method ="lm", se =FALSE, color ="red", linewidth =1.2) +# Adicionar segmentos mostrando os resíduosgeom_segment(aes(xend = quadril, yend = peso_previsto),color ="gray50", alpha =0.4, linewidth =0.5) +tema_graficos() +labs(title ="Resíduos: Diferenças entre Observado e Previsto",subtitle ="As linhas cinzas mostram quanto um ponto se afasta da linha de tendência",x ="Medida de quadril (cm)",y ="Peso (kg)" )
Correlação: Quantificando a Relação
Enquanto a linha de tendência nos mostra o padrão geral, o coeficiente de correlação nos dá um número único que quantifica o quão forte é essa relação.
O Coeficiente de Correlação de Pearson (r)
O coeficiente de correlação de Pearson (r) varia de -1 a +1:
r = +1: Correlação perfeita positiva (todos os pontos exatamente na linha, subindo)
r = 0: Nenhuma correlação linear
r = -1: Correlação perfeita negativa (todos os pontos exatamente na linha, descendo)
Interpretação Visual de Diferentes Correlações
Para entender visualmente o que diferentes valores de r significam, vamos criar simulações:
Ver código R
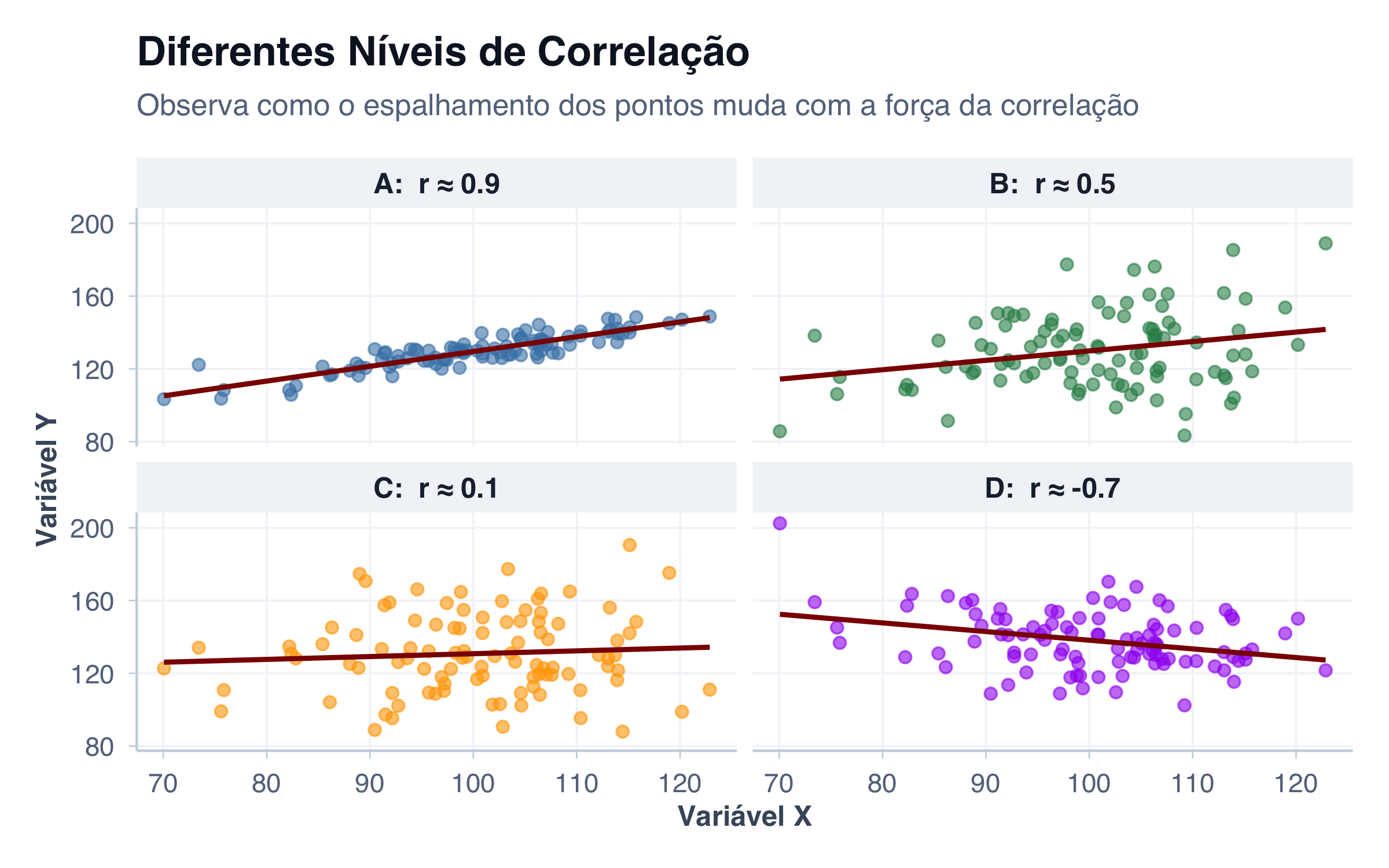
# Criar dados com diferentes correlaçõesset.seed(42)# Correlação forte (r ≈ 0.9)n <-100x_forte <-rnorm(n, mean =100, sd =10)y_forte <-50+0.8* x_forte +rnorm(n, mean =0, sd =5)A_df_forte <-data.frame(x = x_forte, y = y_forte, categoria ="A: r ≈ 0.9")# Correlação moderada (r ≈ 0.5)y_moderada <-50+0.8* x_forte +rnorm(n, mean =0, sd =20)B_df_moderada <-data.frame(x = x_forte, y = y_moderada, categoria ="B: r ≈ 0.5")# Correlação fraca (r ≈ 0.1)y_fraca <-rnorm(n, mean =130, sd =25)C_df_fraca <-data.frame(x = x_forte, y = y_fraca, categoria ="C: r ≈ 0.1")# Correlação negativa (r ≈ -0.7)y_negativa <-200-0.6* x_forte +rnorm(n, mean =0, sd =15)D_df_negativa <-data.frame(x = x_forte, y = y_negativa, categoria ="D: r ≈ -0.7")# Combinar tudodf_simulado <-bind_rows(A_df_forte, B_df_moderada, C_df_fraca, D_df_negativa)# Calcular correlações reaiscor_forte <-cor(A_df_forte$x, A_df_forte$y)cor_moderada <-cor(B_df_moderada$x, B_df_moderada$y)cor_fraca <-cor(C_df_fraca$x, C_df_fraca$y)cor_negativa <-cor(D_df_negativa$x, D_df_negativa$y)# Plotarggplot(df_simulado, aes(x = x, y = y, color = categoria)) +facet_wrap(~categoria, nrow =2) +geom_point(size =2, alpha =0.6) +geom_smooth(method ="lm", se =FALSE, color ="darkred", linewidth =1) +scale_color_manual(values =c("steelblue", "seagreen", "orange", "purple")) +tema_graficos() +theme(legend.position ="none") +labs(title ="Diferentes Níveis de Correlação",subtitle ="Observa como o espalhamento dos pontos muda com a força da correlação",x ="Variável X",y ="Variável Y" )
Observe a diferença:
Na primeira imagem (r ≈ 0.9), os pontos ficam muito perto da linha — correlação forte
Na segunda (r ≈ 0.5), há mais dispersão — correlação moderada
Na terceira (r ≈ 0.1), os pontos estão completamente espalhados — quase nenhuma correlação
Na quarta (r ≈ -0.7), os pontos tendem a descer conforme X aumenta — correlação negativa forte
Calculando a Correlação com Dados Reais
Vamos calcular a correlação entre quadril e peso dados do arquivo pacientes:
Ver código R
ggplot(pacientes, aes(x = quadril, y = peso)) +geom_point(size =3, alpha =0.6, color ="steelblue") +geom_smooth(method ="lm", se =FALSE, color ="darkred", linewidth =1) +tema_graficos() +labs(title ="Relação entre Medida de Quadril e Peso",caption =paste0("n = ", nrow(pacientes), " pacientes"),x ="Medida de quadril (cm)",y ="Peso (kg)" )
Ver código R
# Calcular correlaçãor_quadril_peso <-cor(pacientes$quadril, pacientes$peso, use ="complete.obs")cat("Coeficiente de correlação (Quadril × Peso):",round(r_quadril_peso, 4), "\n")
Coeficiente de correlação (Quadril × Peso): 0.8291
Uma correlação de r ≈ 0.83 indica uma relação forte e positiva: conforme o quadril aumenta, o peso tende a aumentar também.
⚠️ Correlação NÃO é Causalidade!
Este é talvez o conceito mais importante de todo este capítulo. Uma correlação forte NÃO significa que uma variável causa a outra.
Exemplos Clássicos de Correlações Espúrias
Um dos melhores exemplos de como correlações podem ser enganosas vem do trabalho de Tyler Vigen, um estudante de Direito em Harvard que, em 2014, criou o site Spurious Correlations e depois publicou o livro Spurious Correlations(Vigen, 2015). O projeto é simples e genial: Vigen coletou milhares de séries temporais de fontes oficiais norte-americanas — CDC, USDA, NSF, Census Bureau — e calculou correlações entre pares de variáveis que não têm absolutamente nada a ver uma com a outra. O resultado é uma coleção hilária (e instrutiva) de gráficos que mostram correlações altíssimas entre coisas completamente absurdas.
O projeto (Vigen, 2024) se tornou viral e hoje é uma das referências mais citadas em aulas de estatística para ilustrar por que correlação não implica causalidade. Vamos reproduzir dois dos exemplos mais famosos usando os dados originais disponíveis no pacote R spuriouscorrelations.
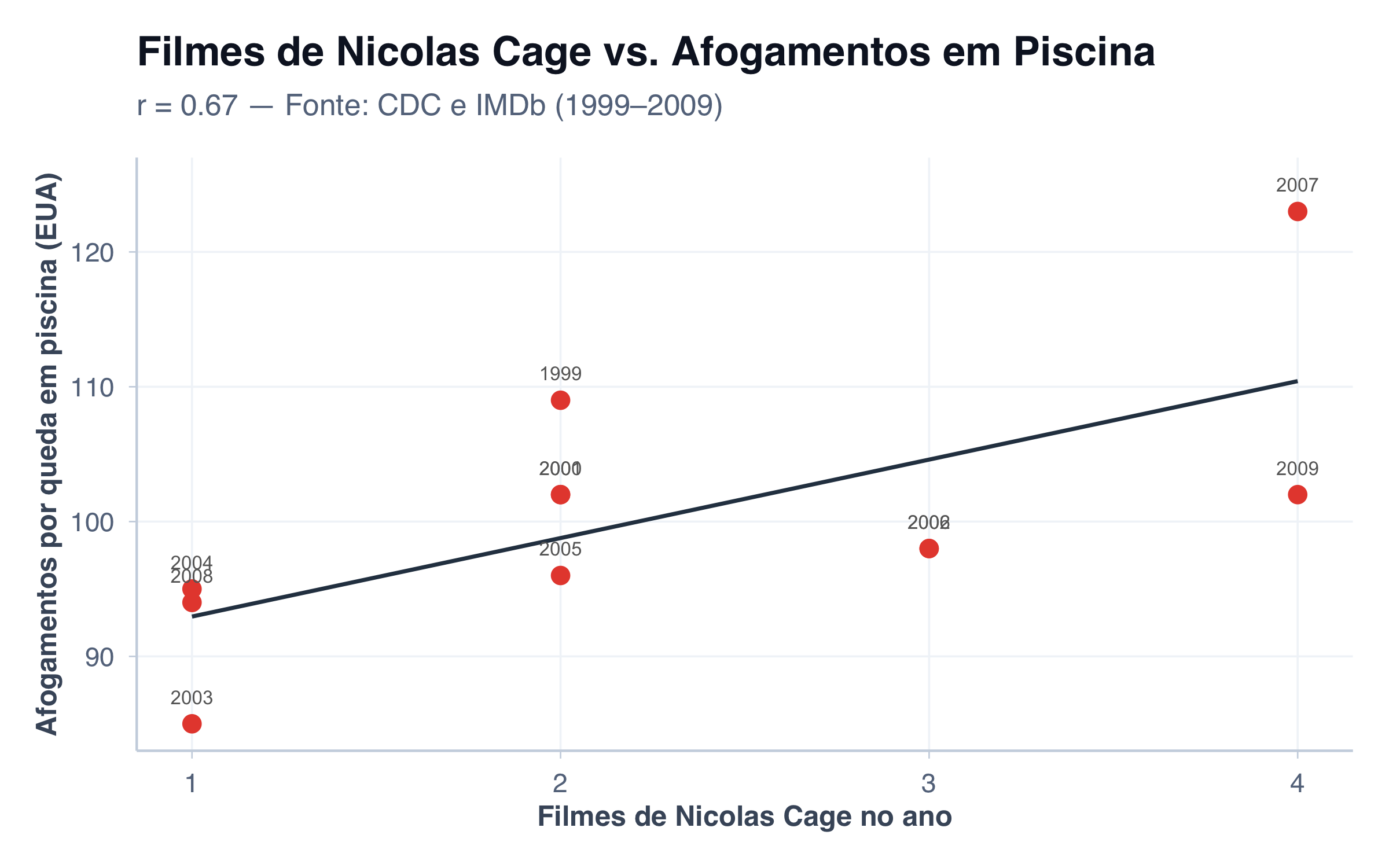
Filmes de Nicolas Cage e Afogamentos em Piscinas
Entre 1999 e 2009, o número de filmes em que Nicolas Cage apareceu em cada ano apresenta correlação de r = 0,67 com o número de pessoas que morreram afogadas ao cair em piscinas nos Estados Unidos. Nos anos em que Cage lançou mais filmes, mais pessoas se afogaram — e quando ele fez poucos filmes, os afogamentos diminuíram. Um padrão estatisticamente consistente, mas que obviamente não significa que os filmes de Nicolas Cage causam afogamentos.
Ver código R
cage <- vigen |>filter(var1_short =="Falling into a pool drownings")r_cage <-cor(cage$var2_value, cage$var1_value)ggplot(cage, aes(x = var2_value, y = var1_value)) +geom_point(color ="#E74C3C", size =3) +geom_smooth(method ="lm", se =FALSE, color ="#2C3E50", linewidth =0.8) +geom_text(aes(label = year), size =2.8, nudge_y =2, color ="gray40") +tema_graficos() +labs(title ="Filmes de Nicolas Cage vs. Afogamentos em Piscina",subtitle =paste0("r = ", round(r_cage, 2)," — Fonte: CDC e IMDb (1999–2009)"),x ="Filmes de Nicolas Cage no ano",y ="Afogamentos por queda em piscina (EUA)" )
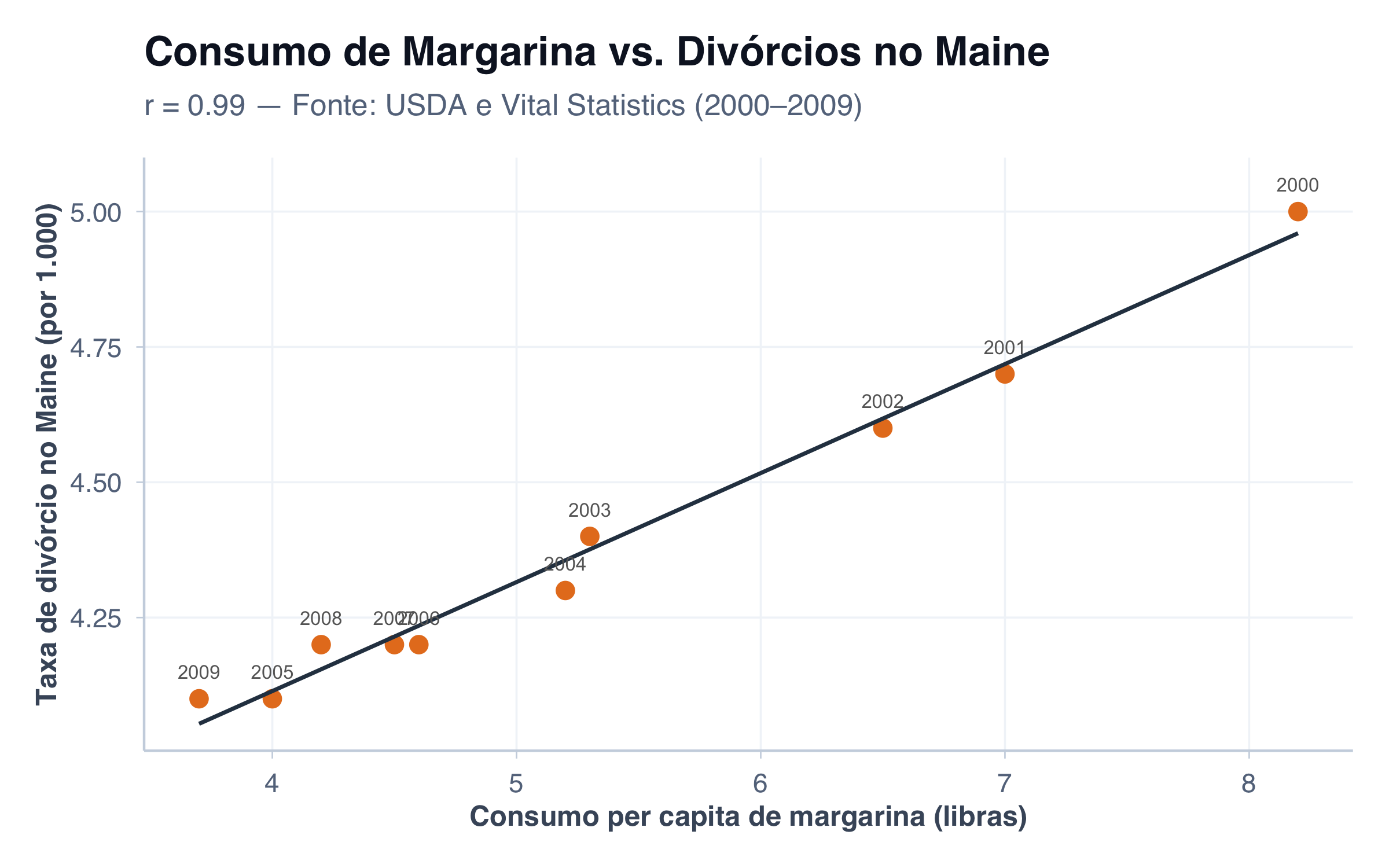
Consumo de Margarina e Divórcios no Maine
Esse é talvez o exemplo mais impressionante de Vigen: entre 2000 e 2009, o consumo per capita de margarina nos Estados Unidos e a taxa de divórcio no estado do Maine apresentam uma correlação de r = 0,99 — quase perfeita, como se uma variável determinasse a outra. Mas ninguém acredita que comer menos margarina salva casamentos no Maine, nem que casais felizes em Maine fazem os americanos rejeitar margarina.
Ver código R
marg <- vigen |>filter(var1_short =="Divorce rate in Maine")r_marg <-cor(marg$var2_value, marg$var1_value)ggplot(marg, aes(x = var2_value, y = var1_value)) +geom_point(color ="#E67E22", size =3) +geom_smooth(method ="lm", se =FALSE, color ="#2C3E50", linewidth =0.8) +geom_text(aes(label = year), size =2.8, nudge_y =0.05, color ="gray40") +tema_graficos() +labs(title ="Consumo de Margarina vs. Divórcios no Maine",subtitle =paste0("r = ", round(r_marg, 2)," — Fonte: USDA e Vital Statistics (2000–2009)"),x ="Consumo per capita de margarina (libras)",y ="Taxa de divórcio no Maine (por 1.000)" )
Outras correlações absurdas do projeto incluem o consumo per capita de mozzarella com o número de doutorados em engenharia civil (r = 0,96), a idade da Miss America com assassinatos por vapor e objetos quentes, e os gastos dos EUA com ciência e tecnologia com suicídios por enforcamento. Todas com correlações altas, todas completamente sem sentido causal.
DicaO Clássico: Sorvete e Afogamentos
Outro exemplo clássico, anterior ao projeto de Vigen: há uma forte correlação positiva entre as vendas de sorvete e o número de afogamentos em uma região. Comer sorvete causa afogamento? Não — ambas as variáveis são influenciadas por uma terceira: a temperatura. No verão, mais pessoas comem sorvete e mais pessoas nadam, aumentando os afogamentos. Essa terceira variável oculta é chamada de variável confundidora (confounding variable).
O Ponto Principal:
Mesmo em nosso exemplo com quadril e peso, a correlação forte sugere que eles variam juntos, mas a relação causal é mais complexa:
Pessoas com quadril maior tendem a ter maior peso (ambos relacionados ao tamanho corporal geral).
Mas quadril não causa peso, nem peso causa quadril.
Ambos são consequência da estrutura corporal e composição corporal geral.
Quando Podemos Inferir Causalidade?
Correlação pode sugerir causalidade apenas quando:
Existe mecanismo plausível: há uma razão biológica/fisiológica para a relação.
Experimentação: em estudos controlados (não observacionais).
Temporalidade: a causa precede o efeito.
Consistência: a relação é observada repetidamente em diferentes populações.
Em dados observacionais (como nossos dados de pacientes), devemos ser muito cautelosos ao afirmar causalidade.
Limitação Importante: Correlação e Linearidade
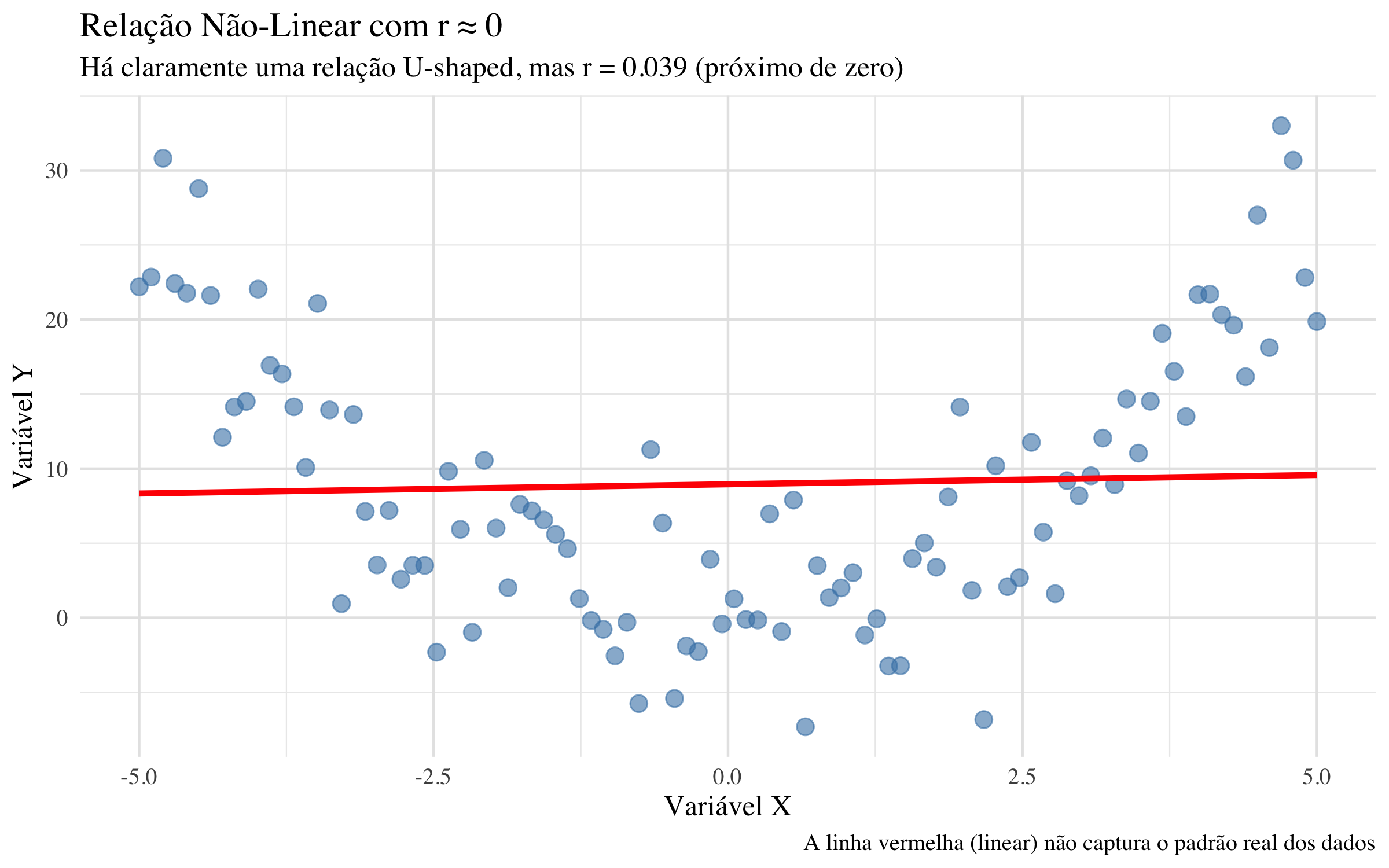
O coeficiente de correlação de Pearson mede apenas correlação LINEAR. Se há um padrão claramente não-linear nos dados, r pode ser próximo de zero mesmo que haja uma relação óbvia!
Vamos demonstrar com um exemplo:
Ver código R
# Criar dados com relação U-shaped (não-linear)set.seed(123)x_nao_linear <-seq(-5, 5, length.out =100)y_nao_linear <- x_nao_linear^2+rnorm(100, 0, 5)df_nao_linear <-data.frame(x = x_nao_linear, y = y_nao_linear)# Calcular correlaçãor_nao_linear <-cor(df_nao_linear$x, df_nao_linear$y)# Visualizarggplot(df_nao_linear, aes(x = x, y = y)) +geom_point(size =3, alpha =0.6, color ="steelblue") +geom_smooth(method ="lm", se =FALSE, color ="red", linewidth =1.2) +theme_minimal() +theme(plot.background =element_rect(fill ="white", color =NA),panel.background =element_rect(fill ="white", color =NA),panel.grid.major =element_line(color ="gray90"),text =element_text(family ="serif", size =12) ) +labs(title ="Relação Não-Linear com r ≈ 0",subtitle =paste0("Há claramente uma relação U-shaped, mas r = ",round(r_nao_linear, 3)," (próximo de zero)"),x ="Variável X",y ="Variável Y",caption ="A linha vermelha (linear) não captura o padrão real dos dados" )
Veja: Há claramente um padrão óbvio (formato de U), mas a correlação linear é r ≈ 0 porque a relação não é linear! Existe correlação sim, chamada correlação não linear.
Esta é uma razão crucial para sempre visualizar os dados antes de confiar em um único número de correlação.
Enriquecendo o Scatter Plot
Até aqui, nossos scatter plots mostraram a relação entre duas variáveis numéricas — e só. Mas na prática clínica, raramente estamos interessados em apenas duas variáveis. Queremos saber se a relação muda entre homens e mulheres, se o biotipo altera o padrão, ou se uma terceira medida ajuda a explicar o que estamos vendo. A seguir, veremos como adicionar camadas de informação ao scatter plot sem perder a clareza.
Separando Grupos por Cor
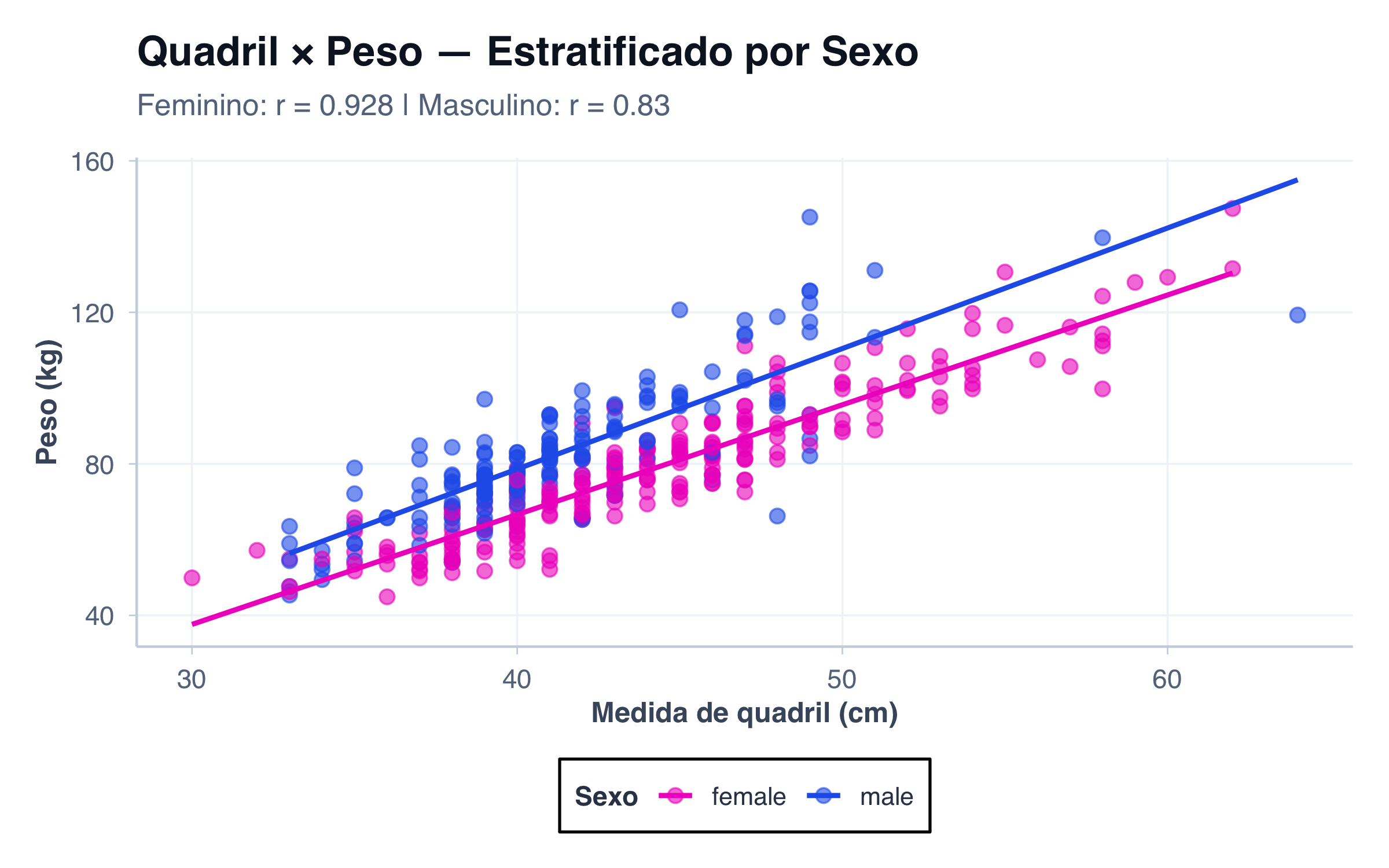
A forma mais direta de incluir uma variável categórica no scatter plot é mapear cada grupo a uma cor diferente. Isso permite comparar as linhas de tendência lado a lado, no mesmo gráfico. No exemplo abaixo, separamos homens e mulheres — e imediatamente percebemos que a relação quadril × peso não é idêntica nos dois grupos:
Ver código R
# Correlações por sexor_feminino <-cor(filter(pacientes, sexo =="female")$quadril,filter(pacientes, sexo =="female")$peso,use ="complete.obs")r_masculino <-cor(filter(pacientes, sexo =="male")$quadril,filter(pacientes, sexo =="male")$peso,use ="complete.obs")ggplot(pacientes, aes(x = quadril, y = peso, color = sexo)) +geom_point(size =2.5, alpha =0.6) +geom_smooth(method ="lm", se =FALSE, linewidth =1) +scale_color_manual(values = paleta_sexo) +tema_graficos() +labs(title ="Quadril × Peso — Estratificado por Sexo",subtitle =paste0("Feminino: r = ", round(r_feminino, 3)," | Masculino: r = ", round(r_masculino, 3)),x ="Medida de quadril (cm)",y ="Peso (kg)",color ="Sexo" )
A estratificação por cor revela padrões que poderiam estar ocultos nos dados gerais. Se olhássemos apenas o scatter plot combinado, veríamos uma única nuvem de pontos — mas separando por sexo, percebemos que cada grupo tem sua própria dinâmica.
Separando Grupos em Painéis (Facetas)
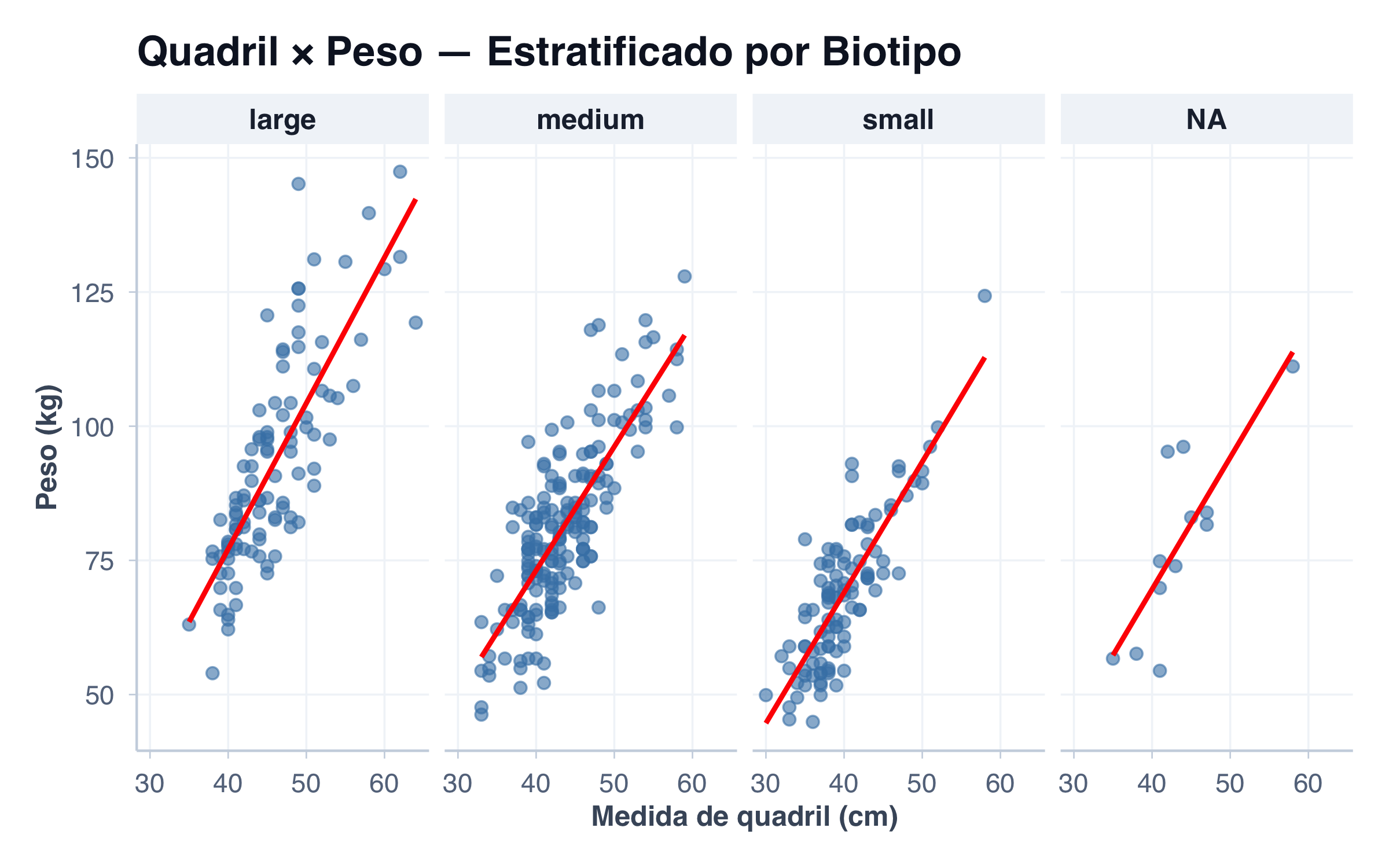
Quando há muitos grupos ou quando as nuvens de pontos se sobrepõem demais, separar em painéis (facetas) pode ser mais eficaz do que usar apenas cores. Cada painel mostra um subgrupo isolado, com sua própria linha de tendência, facilitando a comparação visual. Aqui, separamos por biotipo:
Ver código R
# Correlações por biotipobiotipo_levels <-c("pequeno", "médio", "grande")r_por_biotipo <- pacientes %>%group_by(biotipo) %>%summarise(correlacao =cor(quadril, peso, use ="complete.obs"), .groups ="drop") %>%arrange(match(biotipo, biotipo_levels))ggplot(pacientes, aes(x = quadril, y = peso)) +facet_wrap(~biotipo, nrow =1) +geom_point(size =2, alpha =0.6, color ="steelblue") +geom_smooth(method ="lm", se =FALSE, color ="red", linewidth =1) +tema_graficos() +labs(title ="Quadril × Peso — Estratificado por Biotipo",x ="Medida de quadril (cm)",y ="Peso (kg)" )
Rotulando Pontos de Interesse
Quando um scatter plot tem poucos pontos — ou quando alguns pontos merecem destaque — podemos rotulá-los diretamente no gráfico. Isso é mais informativo do que forçar o leitor a cruzar o gráfico com uma tabela para descobrir quem é quem.
O problema é que, em gráficos com muitos rótulos, os textos se sobrepõem e ficam ilegíveis. O pacote ggrepel resolve isso: ele posiciona os rótulos automaticamente em espaços livres e desenha linhas conectoras finas até o ponto correspondente. Vamos demonstrar com um exemplo clássico de dados internacionais.
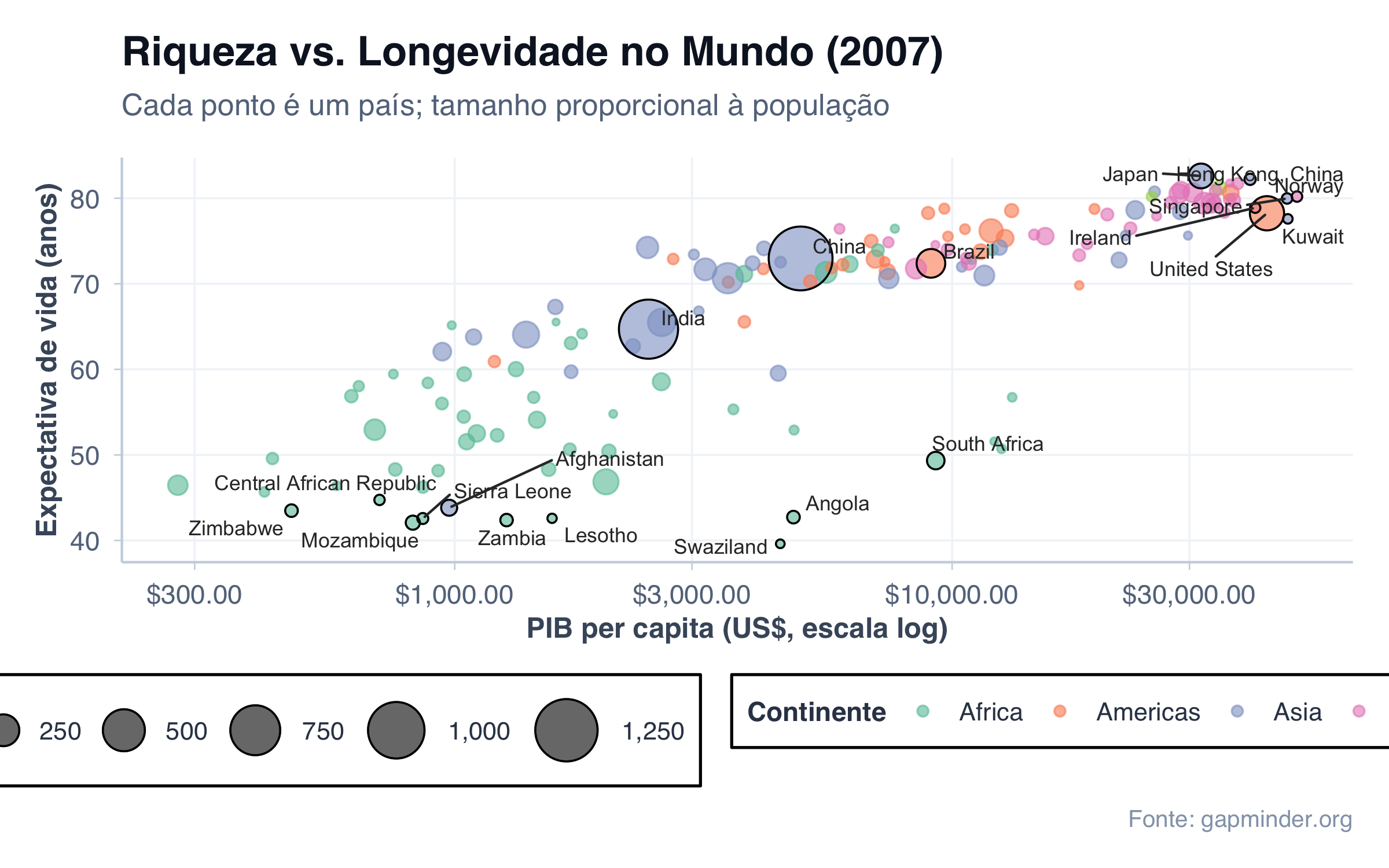
O dataset gapminder, do pacote de mesmo nome, contém dados de 142 países ao longo de décadas: expectativa de vida, população e PIB per capita. Filtrando o ano de 2007, podemos plotar a riqueza de cada país contra a longevidade de sua população — e rotular os casos extremos.
Ver código R
library(gapminder)gap2007 <- gapminder |>filter(year ==2007)# Selecionar países para rotular: extremos de expectativa de vida e PIBrotular <- gap2007 |>filter( lifeExp <45|# menor expectativa de vida lifeExp >82|# maior expectativa de vida gdpPercap >40000|# mais ricos country %in%c("Brazil", "China", "India","United States", "South Africa") )ggplot(gap2007, aes(x = gdpPercap, y = lifeExp)) +geom_point(aes(size = pop /1e6, color = continent),alpha =0.6) +geom_point(data = rotular,aes(size = pop /1e6),color ="black", shape =1, stroke =0.6) + ggrepel::geom_text_repel(data = rotular,aes(label = country),size =3, color ="gray20",max.overlaps =20, seed =42 ) +scale_x_log10(labels = scales::dollar_format()) +scale_size_continuous(range =c(1, 12),labels = scales::comma_format(),name ="População\n(milhões)") +scale_color_brewer(palette ="Set2", name ="Continente") +tema_graficos() +labs(title ="Riqueza vs. Longevidade no Mundo (2007)",subtitle ="Cada ponto é um país; tamanho proporcional à população",x ="PIB per capita (US$, escala log)",y ="Expectativa de vida (anos)",caption ="Fonte: gapminder.org" )
O gráfico revela um padrão claro: países mais ricos tendem a ter maior expectativa de vida, mas a relação não é linear — ela se achata a partir de certo nível de riqueza. Os rótulos do ggrepel nos permitem identificar imediatamente quem são os extremos: no canto inferior esquerdo, países africanos como Swaziland e Mozambique, com expectativa de vida abaixo de 45 anos; no canto superior direito, Japão e Noruega, acima de 80 anos e com alto PIB. Brasil, China e Índia aparecem no meio, cada um com sua posição particular.
Este é um exemplo de scatter plot com quatro variáveis simultâneas: PIB no eixo X, expectativa de vida no eixo Y, continente na cor e população no tamanho dos pontos — além dos rótulos para os casos de interesse.
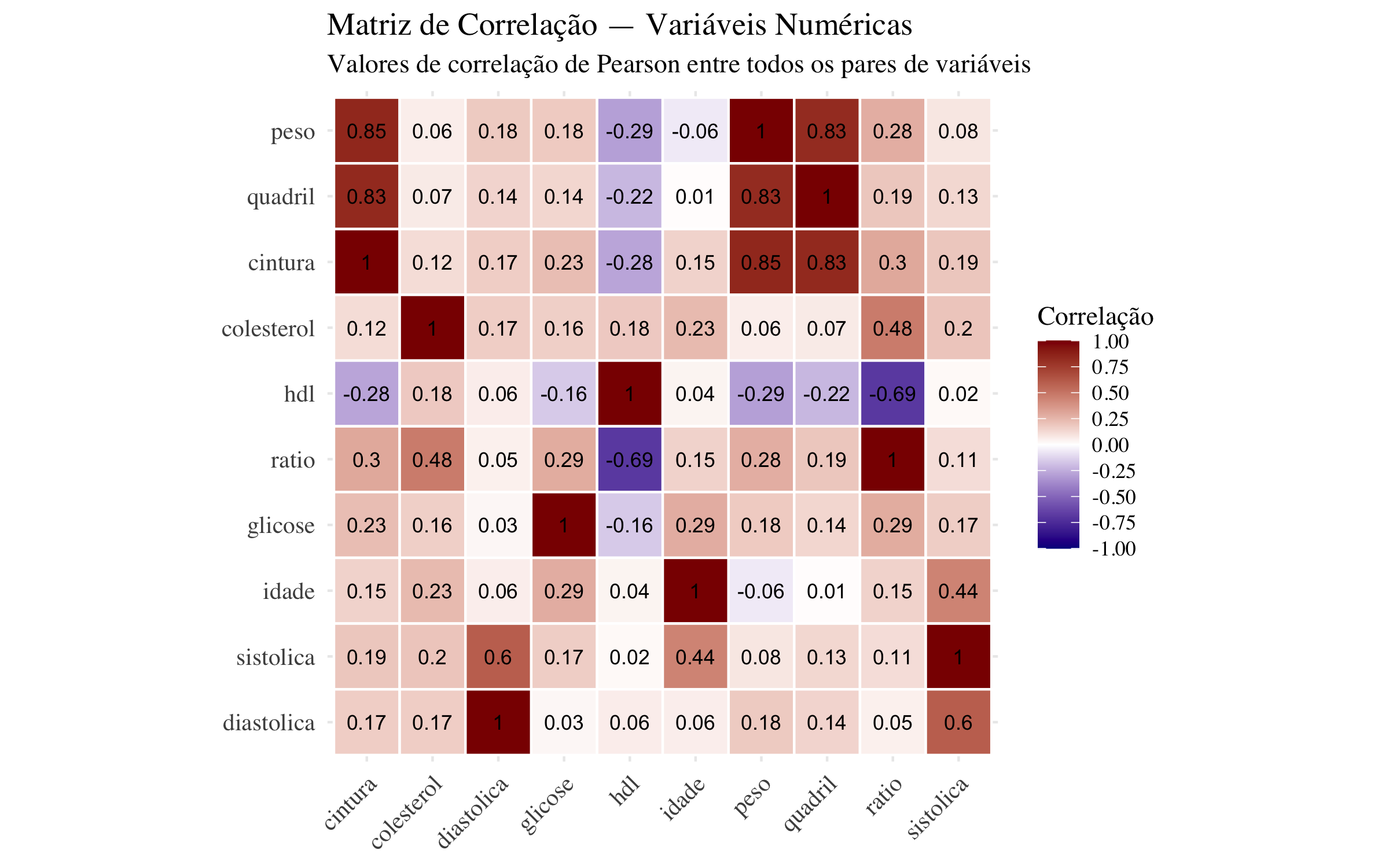
Matriz de Correlação
Quando queremos entender como múltiplas variáveis numéricas se correlacionam entre si, uma matriz de correlação é extremamente útil.
Uma matriz de correlação mostra todos os pares de correlações de uma só vez:
Ver código R
# Selecionar apenas variáveis numéricasvars_numericas <- pacientes %>%select(peso, quadril, cintura, colesterol, hdl, ratio, glicose, idade, sistolica, diastolica) %>%names()# Calcular matriz de correlaçãomatriz_cor <- pacientes %>%select(all_of(vars_numericas)) %>%cor(use ="complete.obs")# Converter para formato longo para ggplotmatriz_cor_long <-as.data.frame(matriz_cor) %>%rownames_to_column("var1") %>%pivot_longer(cols =-var1, names_to ="var2", values_to ="correlacao")# Criar heatmapggplot(matriz_cor_long, aes(x = var2, y = var1, fill = correlacao)) +geom_tile(color ="white", linewidth =0.5) +geom_text(aes(label =round(correlacao, 2)), size =3, color ="black") +scale_fill_gradient2(low ="darkblue", mid ="white", high ="darkred",limits =c(-1, 1), breaks =seq(-1, 1, 0.25)) +scale_x_discrete(guide =guide_axis(angle =45)) +scale_y_discrete(limits =rev(vars_numericas)) +theme_minimal() +theme(plot.background =element_rect(fill ="white", color =NA),panel.background =element_rect(fill ="white", color =NA),axis.title =element_blank(),axis.text =element_text(size =10),text =element_text(family ="serif") ) +labs(title ="Matriz de Correlação — Variáveis Numéricas",subtitle ="Valores de correlação de Pearson entre todos os pares de variáveis",fill ="Correlação" ) +coord_fixed()
Leitura da matriz: - Valores próximos a +1 (vermelho escuro) indicam forte correlação positiva - Valores próximos a -1 (azul escuro) indicam forte correlação negativa - Valores próximos a 0 (branco) indicam fraca ou nenhuma correlação
A diagonal principal sempre mostra 1 (cada variável correlaciona perfeitamente consigo mesma).
Quando Usar Scatter Plot?
Use scatter plot quando:
Explorar associações: Você quer visualizar se duas variáveis numéricas estão relacionadas
Investigar causalidade potencial: Você suspeita que uma variável pode afetar outra
Identificar outliers: Pontos que se desviam dramaticamente da tendência geral
Detectar não-linearidades: Padrões que não são simplesmente lineares
Estratificar por grupos: Comparar a mesma relação em subgrupos diferentes (sexo, idade, biotipo, etc.)
Fazer previsões: Usar a linha de tendência para estimar valores
Erros Comuns e Armadilhas
1. Confundir Correlação com Causalidade
Erro: “Como r = 0.83, o quadril causa peso (ou vice-versa)”
Realidade: Ambos são medidas do tamanho corporal geral. A correlação mostra que variam juntos, não que um causa o outro.
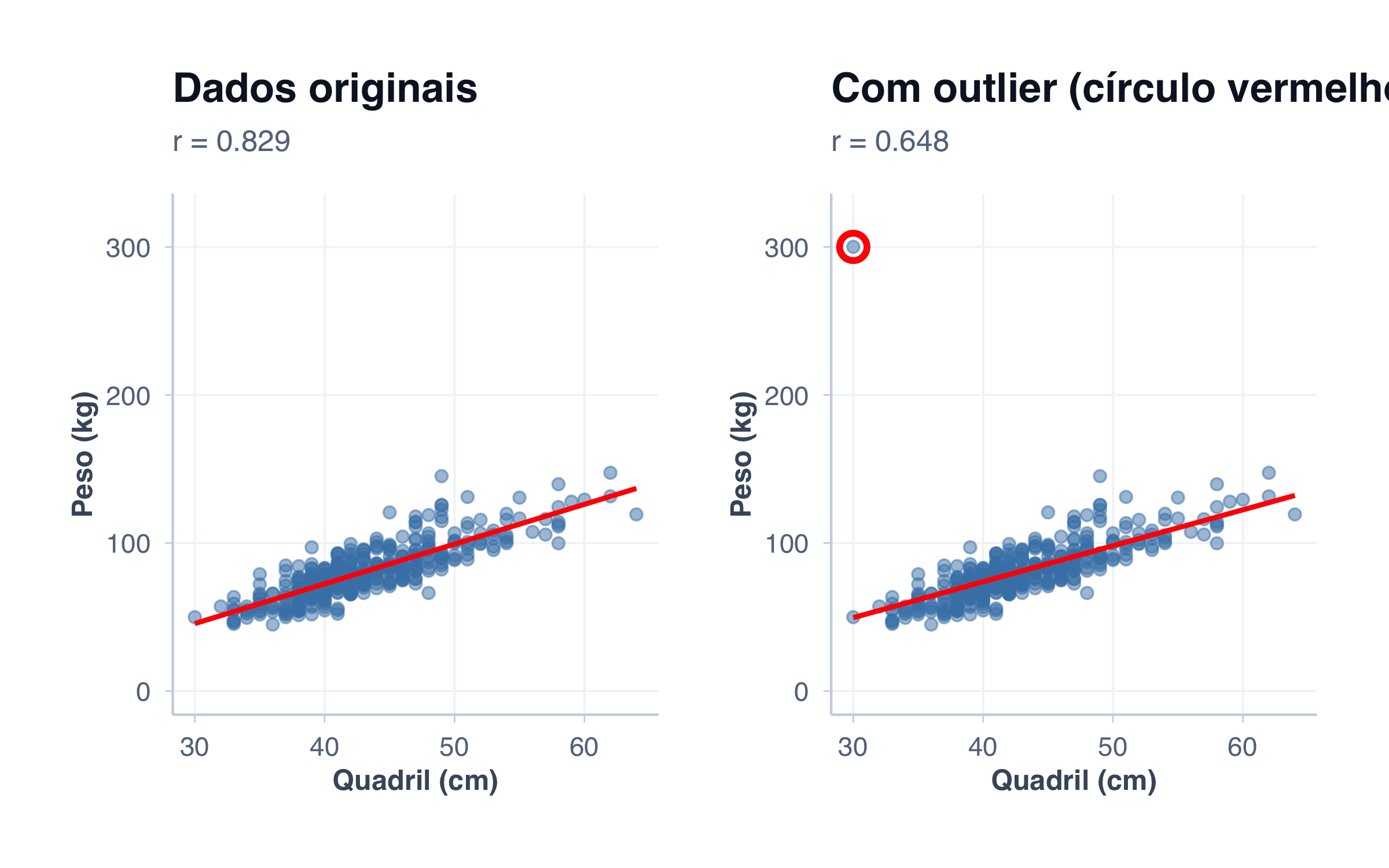
2. Ignorar Outliers Influentes
Um único ponto extremo pode distorcer a linha de tendência e o coeficiente de correlação — especialmente quando está longe da nuvem principal de dados. Para ilustrar, vamos inserir artificialmente um registro absurdo no dataset de pacientes: alguém com quadril de 30 cm e peso de 300 kg. Esse ponto não faz sentido clinicamente e provavelmente seria um erro de digitação (quem sabe, alguém digitou 300 em vez de 30 na coluna errada).
Ver código R
# Inserir um outlier artificial (possível erro de digitação)outlier <-data.frame(quadril =30, peso =300)pacientes_com_outlier <- pacientes |>select(quadril, peso) |>bind_rows(outlier)r_sem <-cor(pacientes$quadril, pacientes$peso, use ="complete.obs")r_com <-cor(pacientes_com_outlier$quadril, pacientes_com_outlier$peso,use ="complete.obs")p1 <-ggplot(pacientes, aes(x = quadril, y = peso)) +geom_point(size =2, alpha =0.5, color ="steelblue") +geom_smooth(method ="lm", se =FALSE, color ="red", linewidth =1) +tema_graficos() +ylim(0, 320) +labs(title ="Dados originais",subtitle =paste0("r = ", round(r_sem, 3)),x ="Quadril (cm)",y ="Peso (kg)" )p2 <-ggplot(pacientes_com_outlier, aes(x = quadril, y = peso)) +geom_point(size =2, alpha =0.5, color ="steelblue") +geom_point(data = outlier, size =4, color ="red", shape =1, stroke =2) +geom_smooth(method ="lm", se =FALSE, color ="red", linewidth =1) +tema_graficos() +ylim(0, 320) +labs(title ="Com outlier (círculo vermelho)",subtitle =paste0("r = ", round(r_com, 3)),x ="Quadril (cm)",y ="Peso (kg)" )p1 + p2
Um único ponto fez a correlação cair de r = 0,83 para r ≈ 0,65. O efeito é dramático porque o outlier está muito distante da nuvem principal.
AvisoOutlier ou Erro de Dados?
Nem todo valor extremo é um erro — alguns pacientes realmente têm medidas incomuns. Mas quando um ponto isolado muda substancialmente a correlação ou a inclinação da reta, é preciso investigar antes de decidir o que fazer. Verifique se houve erro na coleta ou na digitação dos dados (troca de colunas, vírgula no lugar errado, unidades diferentes). Se o valor for real, considere reportar a análise com e sem o outlier, para que o leitor avalie o impacto.
3. Forçar Linearidade
Se há claramente um padrão não-linear, o scatter plot linear não é a melhor ferramenta. Considere:
- Transformações dos dados (logaritmo, raiz quadrada). - Modelos não-lineares. - Splines.
4. Ignorar Confundidores
Uma correlação forte entre duas variáveis pode ser explicada por uma terceira variável.
Por exemplo, a correlação forte entre peso e colesterol pode ser parcialmente explicada pela idade (ambos aumentam com a idade).
Um Lembrete: Anscombe Revisited
Lembra do Quarteto de Anscombe (1973) e do Datasaurus Dozen de Matejka e Fitzmaurice (2017) que vimos no capítulo Você Precisa Mesmo de um Gráfico?? É um lembrete perfeito aqui:
Datasets completamente diferentes podem ter: - A mesma correlação (r ≈ 0.816) - A mesma linha de regressão - Os mesmos valores de média, desvio padrão, etc.
Mas quando visualizados, são completamente diferentes!
Isso reforça nossa mensagem central: sempre visualize os dados antes de confiar em um número.
Resumo Prático
Aspecto
Detalhes
Função R
geom_point() para pontos, geom_smooth(method = "lm") para linha
Correlação
cor(x, y, use = "complete.obs")
Interpretação r
-1 a +1; valores próximos a 0 = fraca correlação
Cuidado
Correlação ≠ Causalidade; sempre visualize
Matriz
cor() em múltiplas variáveis cria matriz de correlação
Quiz
NotaQuizz
Questão 1: O que é Regressão?
Qual é o principal objetivo de uma linha de regressão em um scatter plot?
Provar causalidade entre as variáveis
Descrever o padrão geral e fazer previsões
Eliminar outliers dos dados
Transformar dados não-normais
NotaResposta
b) Descrever o padrão geral e fazer previsões. A linha de regressão (ou best fit line) resume a tendência geral dos dados — por exemplo, “a cada centímetro a mais no quadril, o peso tende a aumentar X quilos”. Isso nos permite fazer previsões para novos indivíduos. Importante: a regressão não prova causalidade (alternativa a). Ela apenas descreve a associação observada nos dados. Também não elimina outliers (alternativa c) — eles continuam lá, apenas não influenciam tanto a direção da reta.
Questão 2: Interpretando Correlação
Se r = -0.78 entre idade e função renal, o que isso significa?
Quanto maior a idade, melhor a função renal
Quanto maior a idade, pior a função renal (relação forte)
Não há relação entre idade e função renal
A idade causa queda na função renal
NotaResposta
b) Quanto maior a idade, pior a função renal (relação forte). O sinal negativo do coeficiente indica que as variáveis variam em direções opostas: quando uma sobe, a outra tende a descer. O valor absoluto (0,78) indica a força da relação — quanto mais próximo de 1, mais forte. Um r = −0,78 é uma correlação negativa forte: à medida que a idade aumenta, a função renal tende a diminuir. A alternativa d está errada porque correlação não é causalidade — mesmo que clinicamente saibamos que a idade de fato afeta a função renal, o coeficiente r sozinho não prova isso.
Questão 3: Correlação vs Causalidade
Um estudo observa correlação r = 0.65 entre número de piscinas em uma cidade e taxa de desemprego. O que você conclui?
Piscinas causam desemprego
Desemprego causa falta de piscinas
Há uma terceira variável (tamanho/riqueza da cidade) explicando ambas
As variáveis não têm relação alguma
NotaResposta
c) Há uma terceira variável (tamanho/riqueza da cidade) explicando ambas. Este é um exemplo clássico de variável confundidora (confounding variable): cidades maiores e mais ricas tendem a ter mais piscinas e mais pessoas desempregadas (simplesmente porque têm mais população). A correlação é real, mas não há relação causal entre piscinas e desemprego. Como vimos com as correlações espúrias do projeto de Tyler Vigen, correlações estatisticamente fortes podem ser completamente sem sentido quando existe uma terceira variável influenciando ambas.
Questão 4: Observando o Scatter Plot
Você vê um scatter plot com pontos formando um padrão de U perfeito (curva parabólica). O que você espera do coeficiente r?
r ≈ 0.95 (correlação forte)
r ≈ 0.00 (nenhuma correlação linear)
r ≈ -0.95 (correlação negativa forte)
r não pode ser calculado para padrões não-lineares
NotaResposta
b) r ≈ 0.00 (nenhuma correlação linear). O coeficiente de Pearson mede apenas a correlação linear — ou seja, o quanto os dados se aproximam de uma reta. Em um padrão de U, os valores sobem de um lado e descem do outro, de modo que os efeitos se cancelam e r fica próximo de zero. Mas isso não significa que não haja relação entre as variáveis! Existe uma relação clara, porém não linear. Por isso é tão importante olhar o scatter plot antes de confiar cegamente no r — como nos ensina o Quarteto de Anscombe. A alternativa d está errada: o r pode ser calculado, apenas não capta relações curvilíneas e não faz sentido fazer esse cálculo.
Questão 5: Escolha de Variável X vs Y
Em um scatter plot de “Pressão Arterial × Idade”, qual variável deve estar no eixo X?
Pressão arterial (resultado) deve estar em X
Idade (variável explicativa/tempo) deve estar em X
Não importa a orientação
Depende do tamanho dos valores
NotaResposta
b) Idade (variável explicativa/tempo) deve estar em X. A convenção em scatter plots é colocar a variável explicativa (independente, preditora) no eixo X e a variável de resposta (dependente, desfecho) no eixo Y. A pergunta que fazemos é: “como a pressão arterial varia em função da idade?” — e não o contrário. A idade vem primeiro (não podemos mudar a idade de alguém alterando sua pressão), então ela é a variável explicativa e vai no eixo X. Essa convenção ajuda o leitor a interpretar o gráfico intuitivamente: a “causa” ou “preditor” na horizontal, o “efeito” ou “resultado” na vertical.
Referências
ANSCOMBE, Francis J. Graphs in Statistical Analysis. The American Statistician, [s.l.], vol. 27, n.º 1, pp. 17–21, 1973.