NotaDois matemáticos, um artigo, seis anos de cartas
Em 1952, dois jovens matemáticos americanos — sem se conhecerem pessoalmente — começaram a trabalhar, de forma independente, no mesmo problema: como estimar a probabilidade de sobrevivência quando nem todos os indivíduos foram observados até o final? Um deles era Edward L. Kaplan (1920–2006), engenheiro e estatístico dos Bell Telephone Laboratories; o outro era Paul Meier (1924–2011), professor na Johns Hopkins University. Ambos haviam sido alunos de doutorado de John Tukey — o mesmo Tukey do boxplot — em Princeton (Stalpers; Kaplan, 2018).
Quando submeteram manuscritos separados ao Journal of the American Statistical Association, o editor percebeu a sobreposição e sugeriu que unissem forças. O que se seguiu foi uma correspondência de mais de quatro anos, com discordâncias metodológicas consideráveis. Kaplan preferia uma abordagem baseada em estimadores de máxima verossimilhança; Meier defendia argumentos de teoria de decisão. Finalmente, em 1958, publicaram juntos o artigo “Nonparametric Estimation from Incomplete Observations”(Kaplan; Meier, 1958) — que se tornaria um dos artigos mais citados de toda a história da ciência, com mais de 44 mil citações no Web of Science até 2017 (Stalpers; Kaplan, 2018) e mais de 65 mil no Google Scholar atualmente.
O mais surpreendente é que o artigo foi praticamente ignorado por uma década. Publicado em um periódico de estatística teórica, só chegou à pesquisa médica em 1969, pelas mãos de Edmund Gehan, bioestatístico do MD Anderson Cancer Center, que aplicou o método em ensaios clínicos oncológicos (Gehan, 1965; Stalpers; Kaplan, 2018). A primeira curva de Kaplan–Meier com o formato de escada que hoje reconhecemos instantaneamente apareceu em 1971, em um estudo sobre quimioterapia para tumores sólidos no mesmo centro (Coltman et al., 1971; Stalpers; Kaplan, 2018). Em 1972, o modelo de riscos proporcionais de David Cox(Cox, 1972) deu o segundo grande impulso: o método de Cox precisava da curva de KM como ponto de partida, e juntos os dois se tornaram as ferramentas padrão de toda pesquisa clínica.
Hoje, curvas de Kaplan–Meier aparecem na grande maioria dos artigos de oncologia clínica (Stalpers; Kaplan, 2018).
O Que é Análise de Sobrevivência?
Análise de sobrevivência é um conjunto de métodos estatísticos para estudar o tempo até a ocorrência de um evento(Schober; Vetter, 2018). Na medicina, o evento de interesse pode ser:
Óbito (sobrevida global, ou overall survival)
Recidiva de uma doença (sobrevida livre de doença, ou disease-free survival)
Progressão tumoral (sobrevida livre de progressão)
Alta hospitalar, concepção, readmissão — qualquer desfecho binário com dimensão temporal
O nome “sobrevivência” é histórico: os primeiros métodos foram desenvolvidos para estudar mortalidade. Mas a técnica se aplica a qualquer situação em que queremos medir quanto tempo leva até algo acontecer (Clark et al., 2003).
O Problema da Censura
O que torna a análise de sobrevivência diferente de uma simples média ou mediana é a censura (censoring). Em um estudo clínico, nem todos os pacientes são observados até o desfecho. Alguns motivos comuns:
O estudo termina antes que o evento ocorra (o paciente ainda está vivo ao final do seguimento)
O paciente muda de cidade e perde o acompanhamento
O paciente falece por uma causa não relacionada ao estudo
Nesses casos, sabemos que o paciente sobreviveu pelo menos até o momento da censura, mas não sabemos exatamente quando o evento ocorreria. Descartar esses pacientes desperdiçaria informação valiosa; incluí-los como se tivessem tido o evento seria incorreto. A genialidade do método de Kaplan–Meier é justamente incorporar essas observações incompletas de forma matematicamente rigorosa (Bland; Altman, 1998; Kaplan; Meier, 1958).
DicaCensura à direita
O tipo mais comum de censura em estudos clínicos é a censura à direita (right censoring): sabemos quando o paciente entrou no estudo, mas não sabemos quando o evento ocorrerá — apenas que ainda não ocorreu até o último contato. Nas curvas de KM, os pacientes censurados são indicados por pequenos traços verticais (tick marks) sobre a curva (Rich et al., 2010).
O Estimador de Kaplan–Meier
O estimador de Kaplan–Meier (também chamado de estimador produto-limite) calcula a probabilidade de sobrevivência em cada momento em que ocorre um evento (Kaplan; Meier, 1958). A ideia é simples e elegante:
Em cada tempo \(t_j\) em que ocorre um evento, a probabilidade de sobreviver além daquele momento é calculada como a fração dos pacientes em risco que não tiveram o evento.
onde \(d_j\) é o número de eventos no tempo \(t_j\) e \(n_j\) é o número de indivíduos em risco naquele momento (Clark et al., 2003).
O resultado é uma função-escada (step function): a probabilidade de sobrevivência permanece constante entre os eventos e cai abruptamente em cada tempo em que um evento ocorre. Essa é a característica visual mais marcante da curva de Kaplan–Meier.
NotaPor que não usar uma média simples?
Se todos os pacientes fossem observados até o desfecho (sem censura), bastaria calcular a média ou mediana dos tempos. Mas com censura, a média é enviesada para baixo (porque tratamos pacientes censurados como se tivessem tido o evento antes do que realmente teriam). O estimador de KM resolve isso: cada paciente contribui com informação enquanto estiver em risco, e deixa de contribuir no momento em que é censurado — sem distorcer as estimativas dos demais (Bland; Altman, 1998).
Construindo Passo a Passo com Dados Reais
Vamos usar dados reais de um dos ensaios clínicos mais importantes da oncologia: o estudo de Moertel et al. (1990), publicado no New England Journal of Medicine(Moertel et al., 1990). Esse estudo demonstrou, pela primeira vez, que a quimioterapia adjuvante com levamisol e fluorouracil reduzia a recorrência e a mortalidade em pacientes com câncer de cólon ressecado.
Os dados desse ensaio estão disponíveis no R através do pacote survival, no dataset colon. Vamos construir nossa curva de KM passo a passo.
Conhecendo os dados
Ver código R
# Carregar os dados do ensaio de Moertel et al. (1990)dados_colon <- survival::colon |>filter(etype ==2) |># etype 2 = óbito (1 = recorrência)mutate(tratamento =case_when( rx =="Obs"~"Observação", rx =="Lev"~"Levamisol", rx =="Lev+5FU"~"Levamisol + 5-FU" ),tratamento =factor(tratamento,levels =c("Observação", "Levamisol", "Levamisol + 5-FU")),tempo_anos = time /365.25# converter dias para anos )# Resumo dos dadosdados_colon |>group_by(tratamento) |>summarise(n =n(),obitos =sum(status),censurados =sum(status ==0),mediana_dias =median(time),.groups ="drop" ) |>kable(col.names =c("Tratamento", "N", "Óbitos", "Censurados", "Mediana (dias)"),caption ="Resumo dos dados do ensaio de Moertel et al. (1990) — desfecho: óbito" ) |>kable_styling(bootstrap_options =c("striped", "hover", "condensed"),full_width =FALSE, position ="center")
Resumo dos dados do ensaio de Moertel et al. (1990) — desfecho: óbito
Tratamento
N
Óbitos
Censurados
Mediana (dias)
Observação
315
168
147
1856
Levamisol
310
161
149
1882
Levamisol + 5-FU
304
123
181
2100
O dataset contém 929 pacientes com câncer de cólon estágio B2 ou C, randomizados em três braços: observação (controle), levamisol isolado e levamisol combinado com fluorouracil (5-FU). Vamos acompanhar o tempo até o óbito.
A primeira curva: sobrevida global
Ver código R
# Ajustar o modelo de sobrevivênciafit_colon <-survfit(Surv(tempo_anos, status) ~ tratamento, data = dados_colon)# Criar o gráfico com survminerggsurvplot( fit_colon,data = dados_colon,# Aparênciapalette =c(cores$vermelho, cores$verde, cores$azul),size =0.9,censor.shape ="|",censor.size =3,# Intervalo de confiançaconf.int =TRUE,conf.int.alpha =0.15,# Risk tablerisk.table =TRUE,risk.table.col ="strata",risk.table.height =0.28,risk.table.fontsize =3.2,# Labelsxlab ="Tempo (anos)",ylab ="Probabilidade de sobrevivência",title ="Sobrevida global — Ensaio de câncer de cólon",subtitle ="Moertel et al. (1990) · N Engl J Med",legend.title ="Tratamento",legend.labs =c("Observação", "Levamisol", "Levamisol + 5-FU"),# Estéticaggtheme =tema_graficos(base_size =12),tables.theme =theme_cleantable())
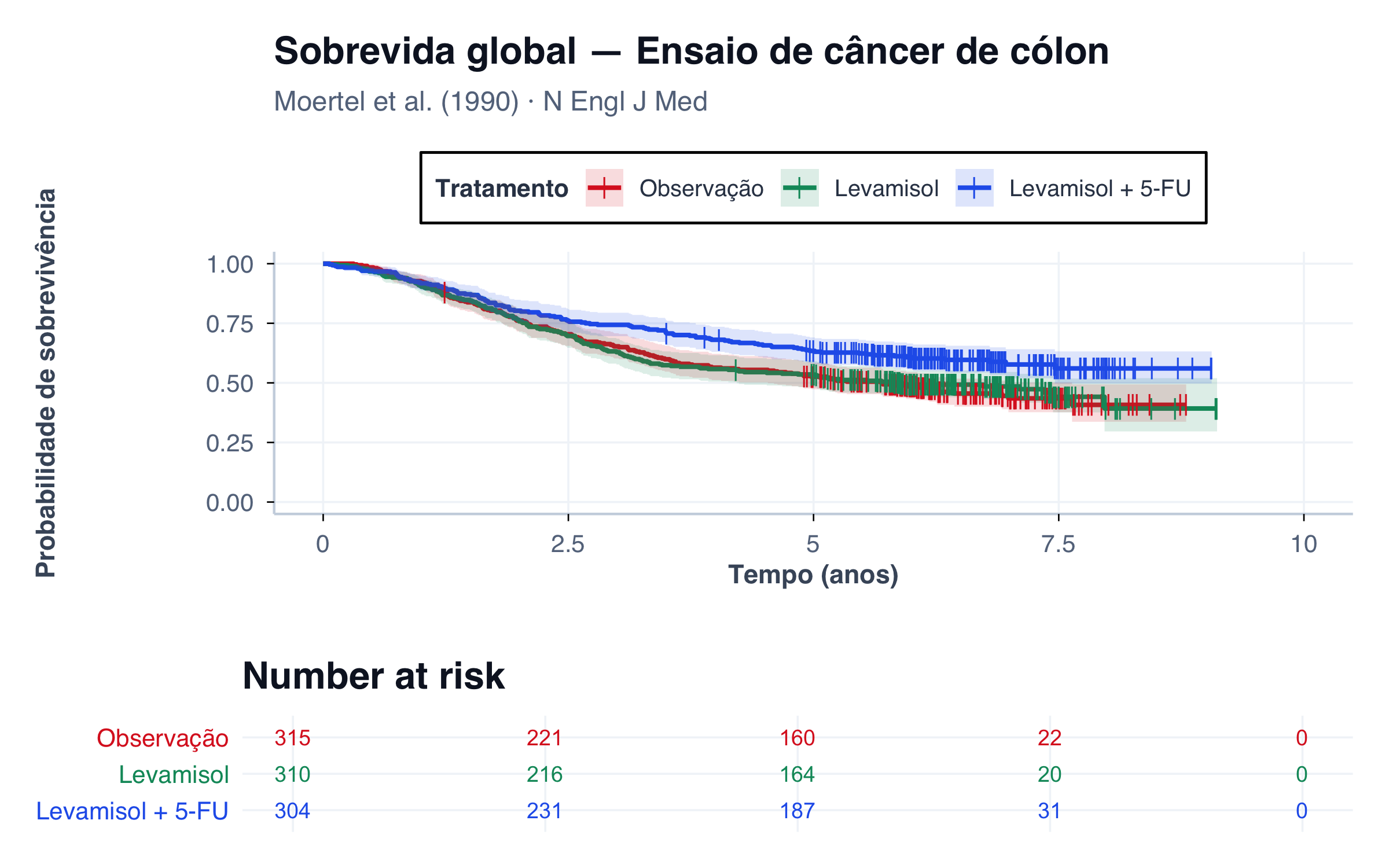
Figura 1: Curva de Kaplan–Meier para o ensaio de Moertel et al. (1990): sobrevida global dos três braços de tratamento. Cada degrau representa um óbito; traços verticais indicam censuras.
O eixo Y mostra a probabilidade de sobrevivência estimada, começando em 1,0 (100%) no tempo zero — quando todos os pacientes estão vivos.
O eixo X mostra o tempo de seguimento, em anos.
Os degraus (a “escada”) indicam os momentos em que ocorrem óbitos. Quanto maior o degrau, mais óbitos ocorreram naquele momento. Quanto mais longa a parte horizontal, mais tempo se passou sem eventos.
Os traços verticais (tick marks) sobre a curva indicam censuras — pacientes que saíram do estudo sem ter o evento.
A tabela de risco (number at risk) abaixo do gráfico mostra quantos pacientes ainda estão em acompanhamento em cada momento. Essa informação é essencial: à medida que o tempo passa, o número de pacientes em risco diminui, e as estimativas se tornam menos precisas.
As faixas sombreadas representam o intervalo de confiança de 95% — quanto mais larga a faixa, maior a incerteza.
ImportanteA “cauda” da curva
Cuidado com interpretações na parte final (à direita) da curva, onde poucos pacientes permanecem em risco. As estimativas nessa região são instáveis e os intervalos de confiança se alargam. Alguns autores recomendam interromper a curva quando menos de 10–20% da amostra original está em risco (Rich et al., 2010).
Mediana de Sobrevivência
A mediana de sobrevivência é o tempo no qual a probabilidade de sobrevivência cruza 50% — ou seja, o tempo em que metade dos pacientes já teve o evento. É a medida-resumo mais usada em análise de sobrevivência, preferida sobre a média porque os tempos de sobrevida raramente seguem uma distribuição simétrica (Clark et al., 2003).
Ver código R
# Extrair medianas de sobrevivênciamediana_surv <-surv_median(fit_colon)mediana_surv |>mutate(strata =c("Observação", "Levamisol", "Levamisol + 5-FU"),across(where(is.numeric), ~round(.x, 2)) ) |>select(strata, median, lower, upper) |>kable(col.names =c("Tratamento", "Mediana (anos)", "IC 95% inferior", "IC 95% superior"),caption ="Mediana de sobrevivência por braço de tratamento" ) |>kable_styling(bootstrap_options =c("striped", "hover", "condensed"),full_width =FALSE, position ="center")
Tabela 1: Mediana de sobrevivência por braço de tratamento
Tratamento
Mediana (anos)
IC 95% inferior
IC 95% superior
Observação
5.70
4.53
7.64
Levamisol
5.89
4.22
NA
Levamisol + 5-FU
NA
7.46
NA
Visualmente, estimamos a mediana traçando uma linha horizontal no nível de 0,50 do eixo Y e verificando onde ela cruza cada curva. Se a curva não cruza os 50%, significa que mais da metade dos pacientes sobreviveu além do período de seguimento — e a mediana não pode ser estimada.
Comparando Curvas: O Teste Log-Rank
Olhar para as curvas e “achar” que uma é melhor que a outra não basta — precisamos de um teste estatístico formal. O teste log-rank é o método mais usado para comparar curvas de Kaplan–Meier entre grupos (Clark et al., 2003; Schober; Vetter, 2018).
O teste compara o número observado de eventos em cada grupo com o número esperado sob a hipótese nula de que as curvas são iguais. O resultado é uma estatística qui-quadrado com (g − 1) graus de liberdade, onde g é o número de grupos.
Ver código R
# Teste log-rankteste_lr <-survdiff(Surv(tempo_anos, status) ~ tratamento, data = dados_colon)teste_lr
Pairwise comparisons using Log-Rank test
data: dados_colon and tratamento
Observação Levamisol
Levamisol 1.0000 -
Levamisol + 5-FU 0.0048 0.0125
P value adjustment method: bonferroni
O teste log-rank global nos diz se pelo menos um grupo difere dos demais. Para saber quais grupos diferem entre si, fazemos comparações pareadas com correção para múltiplos testes.
Interpretando o p-valor do log-rank
O p-valor responde a uma pergunta simples: se os tratamentos fossem idênticos, qual a probabilidade de observar uma diferença tão grande (ou maior) quanto a que vemos nos dados? Por convenção, quando o p-valor é menor que 0,05, consideramos a diferença estatisticamente significativa — ou seja, é improvável que se deva apenas ao acaso. Quando o p-valor é maior que 0,05 (por exemplo, p = 0,15), dizemos que as curvas não diferem de forma estatisticamente significativa ao nível de 5%. Isso não prova que os tratamentos sejam iguais; apenas que os dados disponíveis não fornecem evidência suficiente para afirmar que são diferentes — o que pode ocorrer, por exemplo, quando a amostra é pequena.
DicaLog-rank vs. Hazard Ratio
O teste log-rank responde se as curvas diferem, mas não quantifica o quanto. Para isso, usamos a razão de riscos (hazard ratio, HR), obtida pelo modelo de Cox (Cox, 1972). Um HR < 1 indica que o grupo de tratamento tem menor risco de evento em relação ao controle. O modelo de Cox é o complemento natural da curva de KM e aparece em praticamente todo artigo que apresenta curvas de sobrevivência (Schober; Vetter, 2018).
A Razão de Riscos (Hazard Ratio)
O modelo de riscos proporcionais de Cox (Cox, 1972) permite estimar o hazard ratio (HR) — a razão entre as taxas instantâneas de evento entre dois grupos — ajustando para covariáveis.
Ver código R
# Modelo de Coxcox_fit <-coxph(Surv(tempo_anos, status) ~ tratamento, data = dados_colon)# Resultados formatadoscox_summary <-summary(cox_fit)data.frame(Comparacao =c("Levamisol vs. Observação", "Levamisol + 5-FU vs. Observação"),HR =round(cox_summary$conf.int[, 1], 3),IC_inferior =round(cox_summary$conf.int[, 3], 3),IC_superior =round(cox_summary$conf.int[, 4], 3),p =format.pval(cox_summary$coefficients[, 5], digits =3)) |>kable(col.names =c("Comparação", "HR", "IC 95% inferior", "IC 95% superior", "p"),caption ="Modelo de Cox — Hazard Ratios por braço de tratamento" ) |>kable_styling(bootstrap_options =c("striped", "hover", "condensed"),full_width =FALSE, position ="center")
Modelo de Cox — Hazard Ratios por braço de tratamento
Comparação
HR
IC 95% inferior
IC 95% superior
p
tratamentoLevamisol
Levamisol vs. Observação
0.974
0.784
1.209
0.80917
tratamentoLevamisol + 5-FU
Levamisol + 5-FU vs. Observação
0.690
0.546
0.870
0.00175
Como interpretar o Hazard Ratio
O HR funciona como um multiplicador de risco. Três cenários possíveis:
HR = 1: os dois grupos têm o mesmo risco — o tratamento não faz diferença.
HR < 1: o grupo de tratamento tem menor risco que o controle. Para saber quanto menor, fazemos a conta: redução = 1 − HR. Por exemplo, um HR de 0,65 significa redução de 1 − 0,65 = 0,35, ou seja, 35% menos risco de evento.
HR > 1: o grupo de tratamento tem maior risco que o controle.
O intervalo de confiança de 95% (IC 95%) do HR nos diz se o resultado é estatisticamente significativo. A regra prática: se o IC não inclui o valor 1, o resultado é significativo. Se o IC inclui o 1, não podemos afirmar que haja diferença real entre os grupos. Por exemplo, um HR de 0,65 com IC 95% de 0,48 a 0,88 é significativo (o intervalo inteiro fica abaixo de 1). Já um HR de 0,85 com IC 95% de 0,60 a 1,20 não seria significativo (o intervalo cruza o 1).
Na tabela acima, o HR para o grupo Levamisol + 5-FU confirma o que vemos visualmente na curva: pacientes tratados com a combinação têm menor risco de óbito em comparação com o grupo de observação. Esse resultado mudou a prática clínica e estabeleceu a quimioterapia adjuvante como padrão para câncer de cólon estágio C (Moertel et al., 1990).
Anatomia Visual da Curva de KM
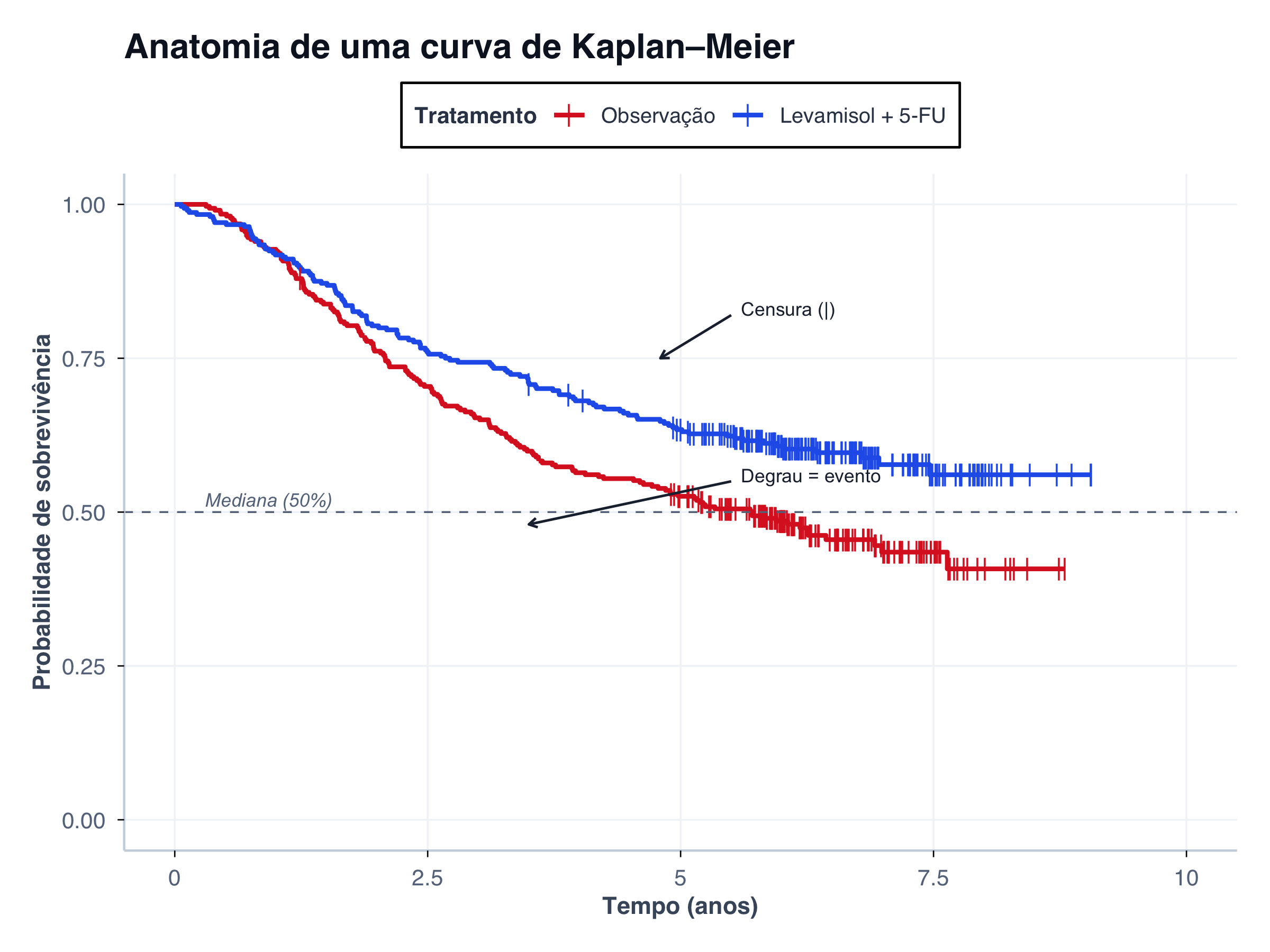
Vamos criar um gráfico anotado para identificar visualmente cada elemento:
Ver código R
# Dados simplificados: apenas Observação vs. Lev+5FUdados_2g <- dados_colon |>filter(tratamento %in%c("Observação", "Levamisol + 5-FU"))fit_2g <-survfit(Surv(tempo_anos, status) ~ tratamento, data = dados_2g)p_anat <-ggsurvplot( fit_2g,data = dados_2g,palette =c(cores$vermelho, cores$azul),size =1,censor.shape ="|",censor.size =3.5,conf.int =FALSE,legend.title ="Tratamento",legend.labs =c("Observação", "Levamisol + 5-FU"),xlab ="Tempo (anos)",ylab ="Probabilidade de sobrevivência",ggtheme =tema_graficos(base_size =12))# Adicionar anotaçõesp_anat$plot <- p_anat$plot +# Linha da medianageom_hline(yintercept =0.5, linetype ="dashed", color = cores$cinza, linewidth =0.4) +annotate("text", x =0.3, y =0.52, label ="Mediana (50%)",size =3, color = cores$cinza, hjust =0, fontface ="italic") +# Seta para censuraannotate("segment", x =5.5, y =0.82, xend =4.8, yend =0.75,arrow =arrow(length =unit(0.15, "cm")), color = cores$escuro) +annotate("text", x =5.6, y =0.83, label ="Censura (|)",size =3, color = cores$escuro, hjust =0) +# Seta para degrauannotate("segment", x =5.5, y =0.55, xend =3.5, yend =0.48,arrow =arrow(length =unit(0.15, "cm")), color = cores$escuro) +annotate("text", x =5.6, y =0.56, label ="Degrau = evento",size =3, color = cores$escuro, hjust =0) +# Títulolabs(title ="Anatomia de uma curva de Kaplan–Meier")p_anat
Figura 2: Anatomia de uma curva de Kaplan–Meier: cada elemento visual carrega informação clínica.
Sobrevida em Diferentes Cenários: Estágio da Doença
Uma das aplicações mais informativas da curva de KM é estratificar pacientes por fatores prognósticos. No dataset do estudo de Moertel, temos informação sobre a profundidade de invasão tumoral e o número de linfonodos positivos.
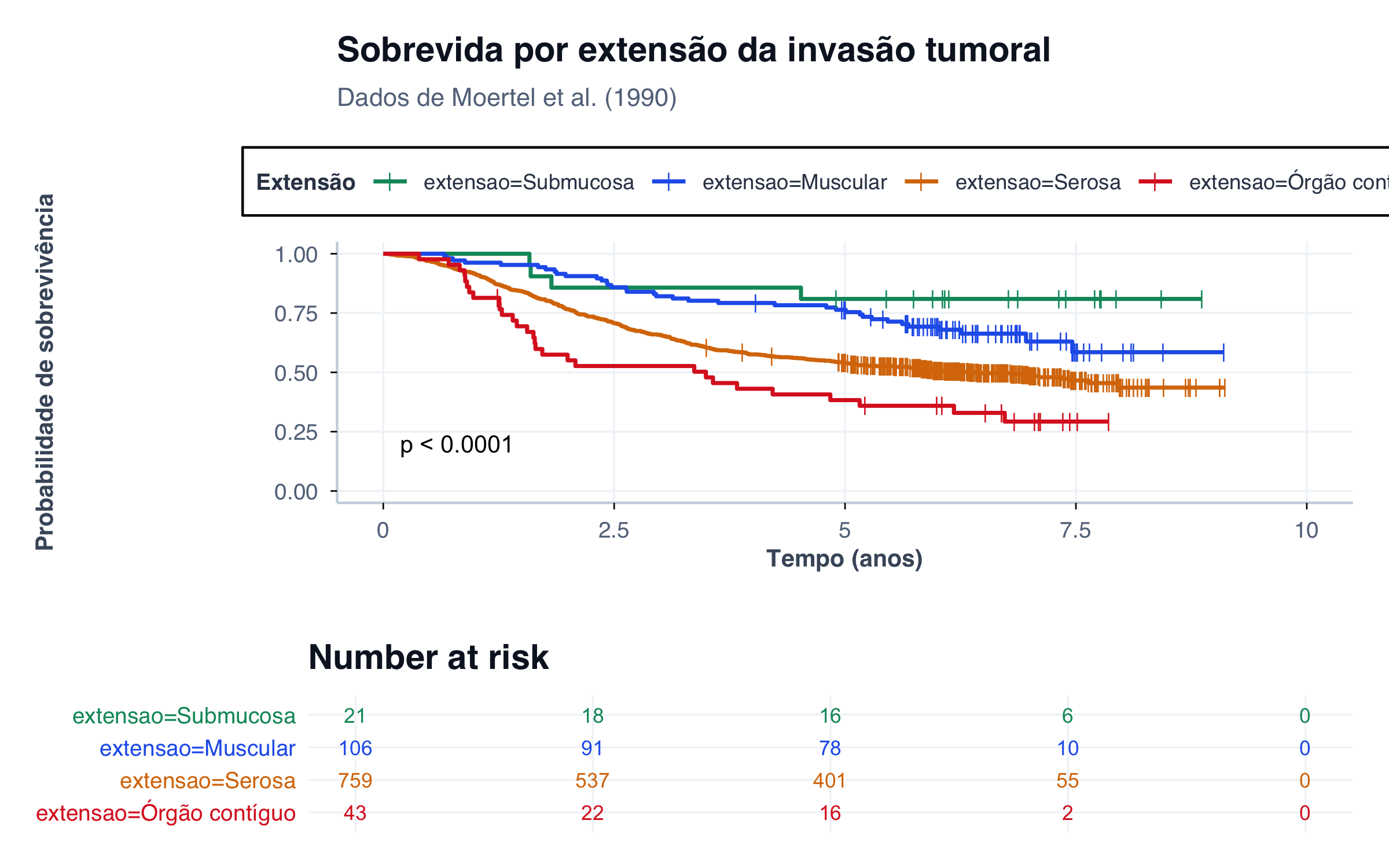
Figura 3: Curvas de Kaplan–Meier estratificadas pela extensão da invasão tumoral. O prognóstico piora substancialmente com invasão mais profunda.
A separação visual entre as curvas traduz diferenças reais de prognóstico. Quando as curvas se separam precocemente e mantêm distância constante, temos uma indicação visual de que o pressuposto de riscos proporcionais (necessário para o modelo de Cox) pode ser razoável (Schober; Vetter, 2018).
Número de Linfonodos e Sobrevida
Ver código R
# Categorizar número de linfonodosdados_nodes <- dados_colon |>filter(!is.na(nodes)) |>mutate(grupo_nodes =case_when( nodes ==0~"0 linfonodos", nodes <=3~"1–3 linfonodos", nodes <=6~"4–6 linfonodos",TRUE~"7+ linfonodos" ),grupo_nodes =factor(grupo_nodes,levels =c("0 linfonodos", "1–3 linfonodos","4–6 linfonodos", "7+ linfonodos")) )fit_nodes <-survfit(Surv(tempo_anos, status) ~ grupo_nodes, data = dados_nodes)ggsurvplot( fit_nodes,data = dados_nodes,palette =c(cores$verde, cores$azul, cores$ambar, cores$vermelho),size =0.8,censor.shape ="|",censor.size =2.5,conf.int =FALSE,risk.table =TRUE,risk.table.height =0.30,risk.table.fontsize =3,risk.table.col ="strata",xlab ="Tempo (anos)",ylab ="Probabilidade de sobrevivência",title ="Sobrevida por número de linfonodos positivos",subtitle ="Dados de Moertel et al. (1990)",legend.title ="Linfonodos",pval =TRUE,pval.size =3.5,ggtheme =tema_graficos(base_size =11),tables.theme =theme_cleantable())
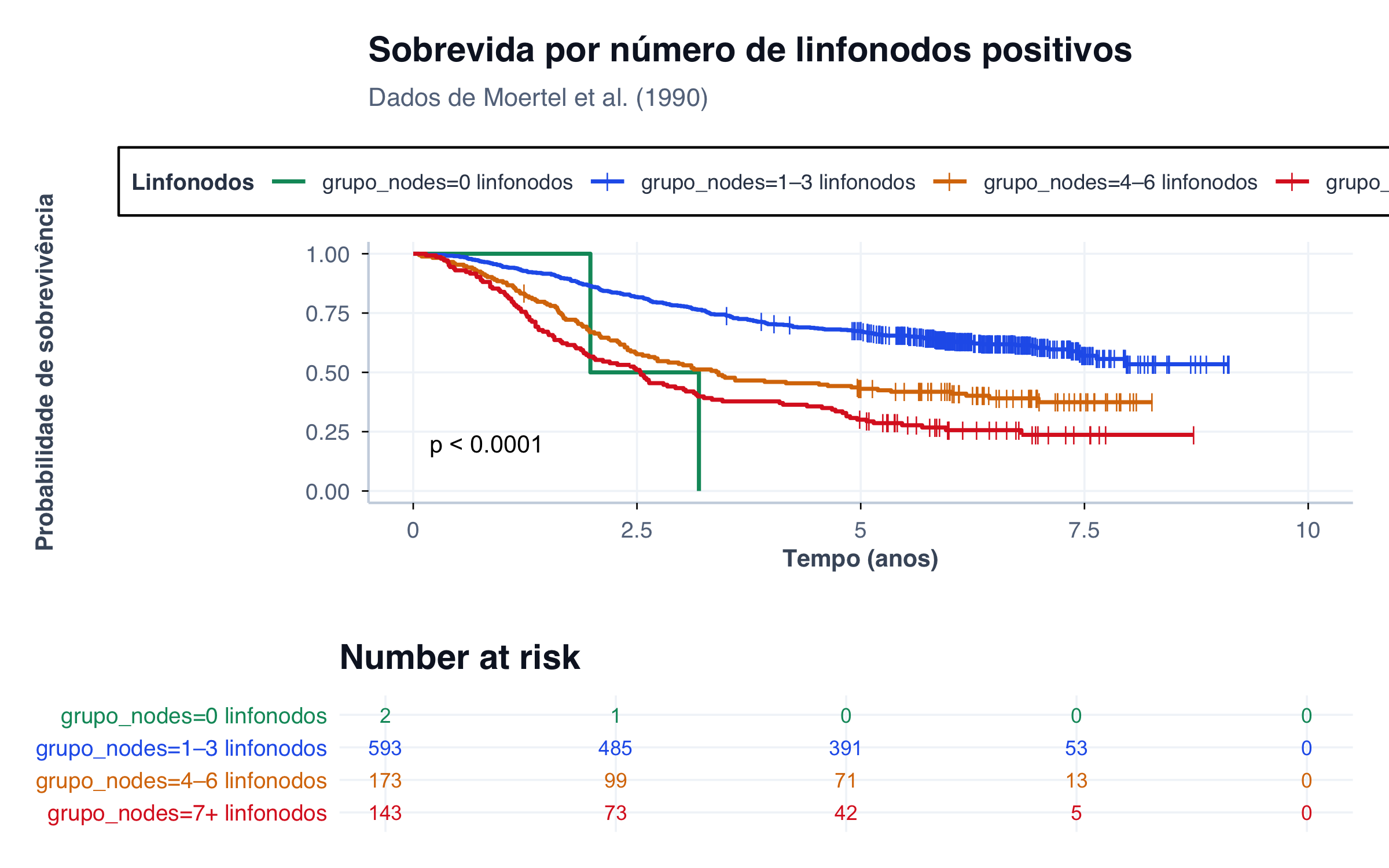
Figura 4: Curvas de Kaplan–Meier por número de linfonodos positivos. O envolvimento linfonodal é um dos fatores prognósticos mais importantes em câncer de cólon.
O número de linfonodos positivos é um dos fatores prognósticos mais fortes em câncer de cólon (Moertel et al., 1990). A curva de KM torna essa relação visualmente evidente: pacientes sem envolvimento linfonodal têm sobrevida muito superior àqueles com sete ou mais linfonodos comprometidos.
Sobrevida em 5 Anos
Na oncologia, é comum reportar a sobrevida estimada em pontos específicos (1 ano, 3 anos, 5 anos). Podemos extrair essas informações diretamente da curva de KM:
Ver código R
# Sobrevida em tempos específicostempos <-c(1, 2, 3, 5)surv_tempos <-summary(fit_colon, times = tempos)data.frame(Tempo =rep(paste0(tempos, " ano(s)"), each =3),Tratamento =rep(c("Observação", "Levamisol", "Levamisol + 5-FU"), times =length(tempos)),Sobrevida =paste0(round(surv_tempos$surv *100, 1), "%"),IC_inferior =paste0(round(surv_tempos$lower *100, 1), "%"),IC_superior =paste0(round(surv_tempos$upper *100, 1), "%")) |>kable(col.names =c("Tempo", "Tratamento", "Sobrevida", "IC 95% inf.", "IC 95% sup."),caption ="Probabilidade de sobrevivência estimada em tempos específicos" ) |>kable_styling(bootstrap_options =c("striped", "hover", "condensed"),full_width =FALSE, position ="center") |>collapse_rows(columns =1, valign ="middle")
Tabela 2: Probabilidade de sobrevivência estimada em tempos específicos
Tempo
Tratamento
Sobrevida
IC 95% inf.
IC 95% sup.
1 ano(s)
Observação
92.4%
89.5%
95.4%
Levamisol
76.1%
71.6%
81%
Levamisol + 5-FU
65.3%
60.3%
70.8%
2 ano(s)
Observação
52.6%
47.3%
58.4%
Levamisol
90.6%
87.5%
93.9%
Levamisol + 5-FU
75.8%
71.2%
80.7%
3 ano(s)
Observação
62.9%
57.7%
68.5%
Levamisol
53.5%
48.3%
59.4%
Levamisol + 5-FU
91.8%
88.7%
94.9%
5 ano(s)
Observação
80.3%
75.9%
84.9%
Levamisol
74.3%
69.6%
79.4%
Levamisol + 5-FU
63.4%
58.2%
69.1%
Erros Comuns na Interpretação
AvisoArmadilhas na leitura de curvas de KM
1. Extrapolar além dos dados. Se o seguimento máximo é de 5 anos, não podemos dizer nada sobre sobrevida em 10 anos. A curva termina onde os dados terminam.
2. Ignorar o número em risco. Uma curva que parece estável no final pode estar baseada em apenas 3 pacientes. Sempre olhe a tabela de risco abaixo do gráfico (Rich et al., 2010).
3. Confundir separação visual com significância estatística. Duas curvas podem parecer separadas visualmente, mas o teste log-rank pode não ser significativo — especialmente com amostras pequenas. O inverso também ocorre: com amostras muito grandes, diferenças clinicamente irrelevantes podem ser estatisticamente significativas.
4. Comparar pontos isolados em vez de curvas inteiras. O teste log-rank compara a distribuição completa dos tempos de sobrevivência, não apenas a sobrevida em um ponto específico (Dudley; Wickham; Coombs, 2016; Rich et al., 2010).
5. Assumir que “censurado” significa “curado”. Censura significa apenas que perdemos o acompanhamento; o paciente pode ter tido o evento logo depois (Schober; Vetter, 2018).
Um Segundo Exemplo: Câncer de Pulmão
Para consolidar o aprendizado, vamos analisar outro dataset clássico do R: lung, do pacote survival. Estes dados vêm do North Central Cancer Treatment Group e incluem 228 pacientes com câncer de pulmão avançado.
Ver código R
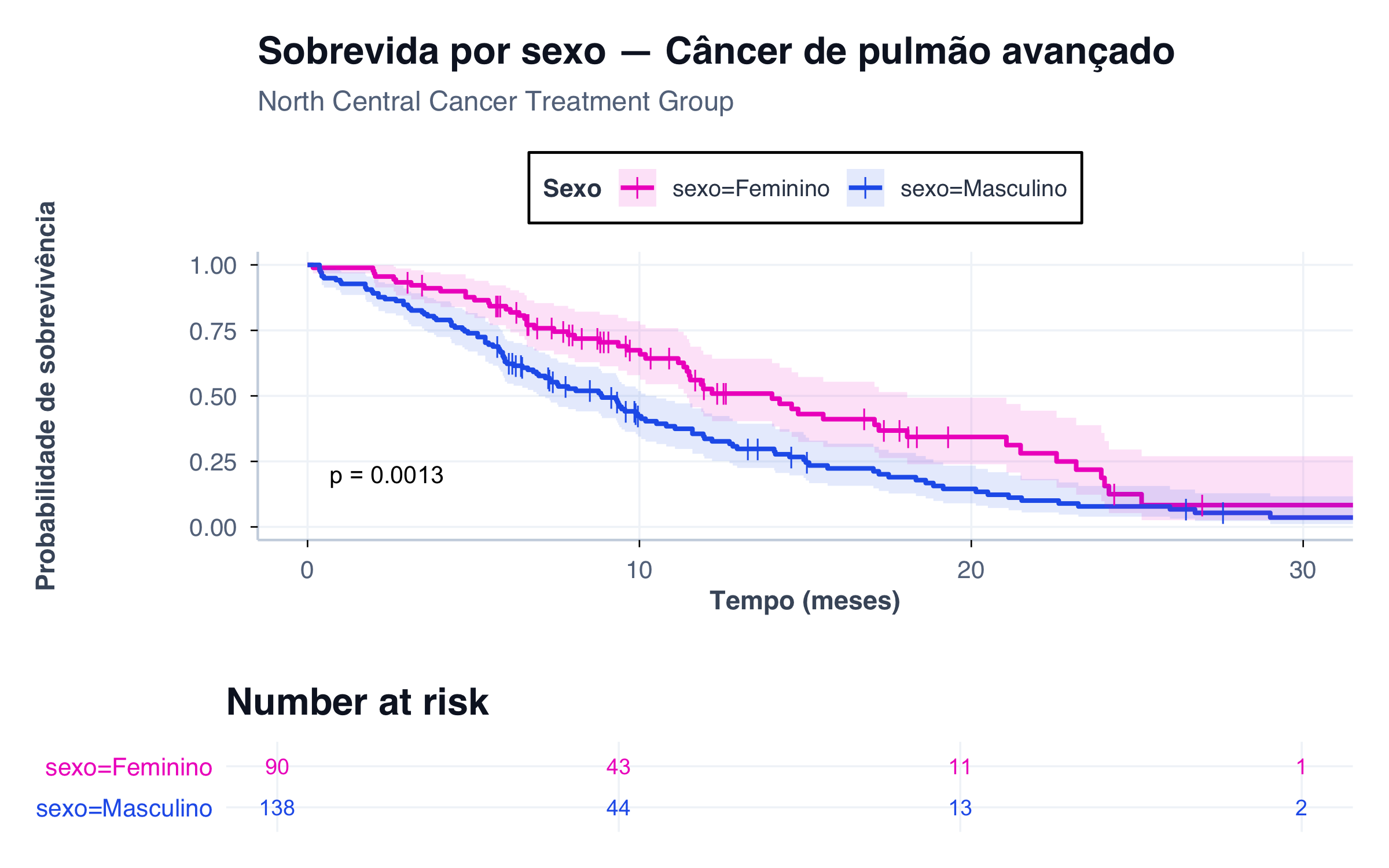
# Preparar dadosdados_lung <- survival::lung |>mutate(sexo =ifelse(sex ==1, "Masculino", "Feminino"),tempo_meses = time /30.44# converter dias para meses )fit_lung <-survfit(Surv(tempo_meses, status) ~ sexo, data = dados_lung)ggsurvplot( fit_lung,data = dados_lung,palette =c("#ef24c6", "#2563EB"), # Feminino (rosa), Masculino (azul)size =0.9,censor.shape ="|",censor.size =3,conf.int =TRUE,conf.int.alpha =0.12,risk.table =TRUE,risk.table.height =0.25,risk.table.fontsize =3.2,risk.table.col ="strata",xlab ="Tempo (meses)",ylab ="Probabilidade de sobrevivência",title ="Sobrevida por sexo — Câncer de pulmão avançado",subtitle ="North Central Cancer Treatment Group",legend.title ="Sexo",pval =TRUE,pval.size =3.5,ggtheme =tema_graficos(base_size =12),tables.theme =theme_cleantable())
Figura 5: Curvas de Kaplan–Meier para 228 pacientes com câncer de pulmão avançado, separadas por sexo. A curva rosa (feminino) permanece acima da curva azul (masculino) ao longo de todo o seguimento, indicando que, neste estudo, as mulheres sobreviveram por mais tempo. O teste log-rank (p = 0,0013) confirma que essa diferença é estatisticamente significativa — ou seja, é improvável que se deva apenas ao acaso.
Este exemplo ilustra outro uso fundamental da curva de KM: identificar fatores prognósticos. A diferença de sobrevida por sexo é visualmente clara e estatisticamente significativa — e leva à pergunta seguinte, tipicamente respondida com um modelo de Cox: essa diferença persiste após ajuste para idade, performance status e outros fatores?
Conexão com a Prática Clínica
As curvas de Kaplan–Meier são a linguagem visual da pesquisa clínica. Saber lê-las permite ao profissional de saúde:
Avaliar criticamente artigos que recomendam mudanças na prática
Comunicar prognóstico a pacientes e familiares de forma mais informada
Comparar tratamentos visualmente antes de mergulhar nas estatísticas
Identificar subgrupos com prognóstico diferente (como vimos com estágio e linfonodos)
DicaChecklist para leitura de curvas de KM
Ao encontrar uma curva de Kaplan–Meier em um artigo, verifique:
Qual é o evento? (óbito, recorrência, progressão?)
Qual é o tempo no eixo X? (dias, meses, anos?)
O eixo Y começa em 0 ou 1? (curvas descendentes vs. ascendentes)
Há tabela de risco? (quantos pacientes em cada tempo?)
Há intervalos de confiança? (as faixas estão estreitas ou largas?)
As marcas de censura estão visíveis? (muitas censuras podem indicar problemas no seguimento)
O teste log-rank é significativo? (p-valor reportado?)
O hazard ratio e seu IC estão reportados? (qual a magnitude do efeito?)
Além da Curva de KM
A curva de Kaplan–Meier é o primeiro passo da análise de sobrevivência. Na prática, os pesquisadores tipicamente seguem uma sequência (Clark et al., 2003; Schober; Vetter, 2018):
Kaplan–Meier para visualizar e descrever os dados
Teste log-rank para comparar grupos
Modelo de Cox para ajustar por covariáveis e estimar hazard ratios
O modelo de riscos proporcionais de Cox (Cox, 1972) é semiparamétrico: não assume uma forma específica para a função de sobrevivência (como o KM), mas assume que o efeito das covariáveis é constante ao longo do tempo (pressuposto de riscos proporcionais). Quando esse pressuposto é violado — por exemplo, se um tratamento tem efeito forte no início mas diminui com o tempo — os pesquisadores precisam de extensões mais avançadas, como modelos com covariáveis dependentes do tempo ou modelos de riscos competitivos (Schober; Vetter, 2018).
Quiz
NotaQuizz
Pergunta 1: Em uma curva de Kaplan–Meier, o que representam os pequenos traços verticais sobre a curva?
Eventos (óbitos ou recorrências)
Erros de medição
Censuras (pacientes que saíram do estudo sem evento)
Intervalos de confiança
NotaResposta
c) Censuras (pacientes que saíram do estudo sem evento). Os traços verticais (tick marks) sobre a curva indicam pacientes censurados — aqueles que deixaram de ser acompanhados antes de ter o evento (por exemplo, mudaram de cidade, o estudo terminou ou faleceram por outra causa). Os degraus da escada é que representam os eventos.
Pergunta 2: A mediana de sobrevivência em uma curva de KM é estimada como:
A média aritmética dos tempos de sobrevivência
O tempo em que a curva cruza o nível de 50%
O tempo do último evento observado
A metade do tempo total de seguimento
NotaResposta
b) O tempo em que a curva cruza o nível de 50%.
A mediana corresponde ao momento em que 50% dos pacientes já teve o evento. Como a probabilidade de sobrevivência está no eixo Y, traçamos uma linha horizontal no nível de 0,50 e verificamos onde ela intercepta a curva. Desse ponto de interseção, descemos verticalmente até o eixo X para ler o tempo correspondente — essa é a mediana de sobrevivência. A linha é horizontal (e não vertical) porque estamos buscando um valor fixo de probabilidade (50%), não um valor fixo de tempo. Se a curva não chega a cruzar os 50%, a mediana não pode ser estimada, pois mais da metade dos pacientes não apresentou o evento durante o período de seguimento do estudo.
Pergunta 3: Qual das seguintes afirmações sobre censura é VERDADEIRA?
Pacientes censurados devem ser excluídos da análise
Censura significa que o paciente foi curado
Pacientes censurados contribuem com informação enquanto estão em risco
A censura não afeta as estimativas de sobrevivência
NotaResposta
c) Pacientes censurados contribuem com informação enquanto estão em risco.
Esse é o grande mérito do método de Kaplan–Meier: cada paciente contribui para a estimativa de sobrevivência durante todo o período em que foi acompanhado. No momento da censura, o paciente sai do denominador (“em risco”), mas toda a sua informação anterior é preservada. Excluí-lo da análise (alternativa a) desperdiçaria dados valiosos. E censura não significa cura (alternativa b) — apenas que não sabemos o que aconteceu depois.
Pergunta 4: Um estudo mostra curvas de KM separadas, mas o teste log-rank dá p = 0,15. O que concluímos?
As curvas são significativamente diferentes
As curvas não diferem de forma estatisticamente significativa ao nível de 5%
O gráfico está errado
Precisamos de mais variáveis
NotaResposta
b) As curvas não diferem de forma estatisticamente significativa ao nível de 5%
Um p-valor de 0,15 é maior que o limiar convencional de 0,05, portanto não temos evidência suficiente para rejeitar a hipótese de que as curvas sejam iguais. Isso não significa que os tratamentos sejam idênticos — apenas que, com os dados disponíveis, a diferença observada poderia ser explicada pelo acaso. É uma situação comum quando a amostra é pequena: visualmente as curvas parecem separadas, mas o teste não tem poder estatístico suficiente para confirmar.
Pergunta 5: Um hazard ratio de 0,65 (IC 95%: 0,48–0,88) para um novo tratamento significa:
O tratamento aumenta o risco de evento em 65%
O tratamento reduz o risco de evento em 35%
65% dos pacientes sobrevivem
O resultado não é estatisticamente significativo
NotaResposta
b) O tratamento reduz o risco de evento em 35%. O hazard ratio (HR) compara a taxa de eventos entre dois grupos. Um HR de 0,65 significa que, a qualquer momento, o grupo tratado tem 65% do risco do grupo controle — ou seja, uma redução de 35% (1 − 0,65 = 0,35). Como o intervalo de confiança (0,48–0,88) não inclui o valor 1 (que significaria risco igual), o resultado é estatisticamente significativo. Se o IC incluísse o 1, não poderíamos afirmar que há diferença real.
Referências
BLAND, J. Martin; ALTMAN, Douglas G. Survival Probabilities (the Kaplan–Meier Method). BMJ, [s.l.], vol. 317, n.º 7172, p. 1572, 1998. Disponível em: https://doi.org/10.1136/bmj.317.7172.1572.
CLARK, T. G. et al. Survival Analysis Part I: Basic Concepts and First Analyses. British Journal of Cancer, [s.l.], vol. 89, n.º 2, pp. 232–238, 2003. Disponível em: https://doi.org/10.1038/sj.bjc.6601118.
COX, David R. Regression Models and Life-Tables. Journal of the Royal Statistical Society: Series B (Methodological), [s.l.], vol. 34, n.º 2, pp. 187–202, 1972. Disponível em: https://doi.org/10.1111/j.2517-6161.1972.tb00899.x.
GEHAN, Edmund A. A Generalized Wilcoxon Test for Comparing Arbitrarily Singly-Censored Samples. Biometrika, [s.l.], vol. 52, n.º 1-2, pp. 203–224, 1965. Disponível em: https://doi.org/10.1093/biomet/52.1-2.203.
KAPLAN, E. L.; MEIER, Paul. Nonparametric Estimation from Incomplete Observations. Journal of the American Statistical Association, [s.l.], vol. 53, n.º 282, pp. 457–481, 1958. Disponível em: https://doi.org/10.1080/01621459.1958.10501452.
MOERTEL, Charles G. et al. Levamisole and Fluorouracil for Adjuvant Therapy of Resected Colon Carcinoma. The New England Journal of Medicine, [s.l.], vol. 322, n.º 6, pp. 352–358, 1990. Disponível em: https://doi.org/10.1056/NEJM199002083220602.
STALPERS, Lukas J. A.; KAPLAN, Edward L. Edward L. Kaplan and the Kaplan–Meier Survival Curve. BSHM Bulletin: Journal of the British Society for the History of Mathematics, [s.l.], vol. 33, n.º 2, pp. 109–135, 2018.